









本节内容
在访问网站的时候,我们经常遇到有些页面必须用户登录才能访问。这个时候我们之前写的傻傻的爬虫就被ban在门外了。所以本节,我们给爬虫配置cookie,使得爬虫能保持用户已登录的状态,达到获得那些需登录才能访问的页面的目的。
由于本节只是单纯的想保持一下登陆状态,所以就不写复杂的获取页面了,还是像本教程的第一部分一样,下载个网站主页验证一下就ok了。本节github戳此处。
原理
一般情况下,网站通过存放在客户端的一个被称作cookie的小文件来存放用户的登陆信息。在浏览器访问网站的时候,会把这个小文件发往服务器,然后服务器根据这个小文件确定你的身份,然后返回给你特定的信息。
我们要做的就是尽量模拟浏览器的行为,在使用爬虫访问网站时也带上cookie来访问。
前提
前提当然是你有个账号了,目前本教程一直使用的论坛心韵论坛是我本人搭建的,已经被各种爬虫发的广告水的不要不要的了,为了本教程,仍然是开放注册并一直开着服。但不保证会一直开着,不过根据本教程的讲解,爬取别的Discuz框架论坛一般是没问题的。扯远了……
获取cookie
按照以下步骤操作
- 登陆论坛,进入主页
- 按F12进入Chrome或Firefox的开发者调试工具,选择Network选项卡
- 按F5刷新一下页面
- 选择Doc子选项卡
- 找到主页的请求和返回情况
- 找到Request Headers
- 复制出cookie
如图:
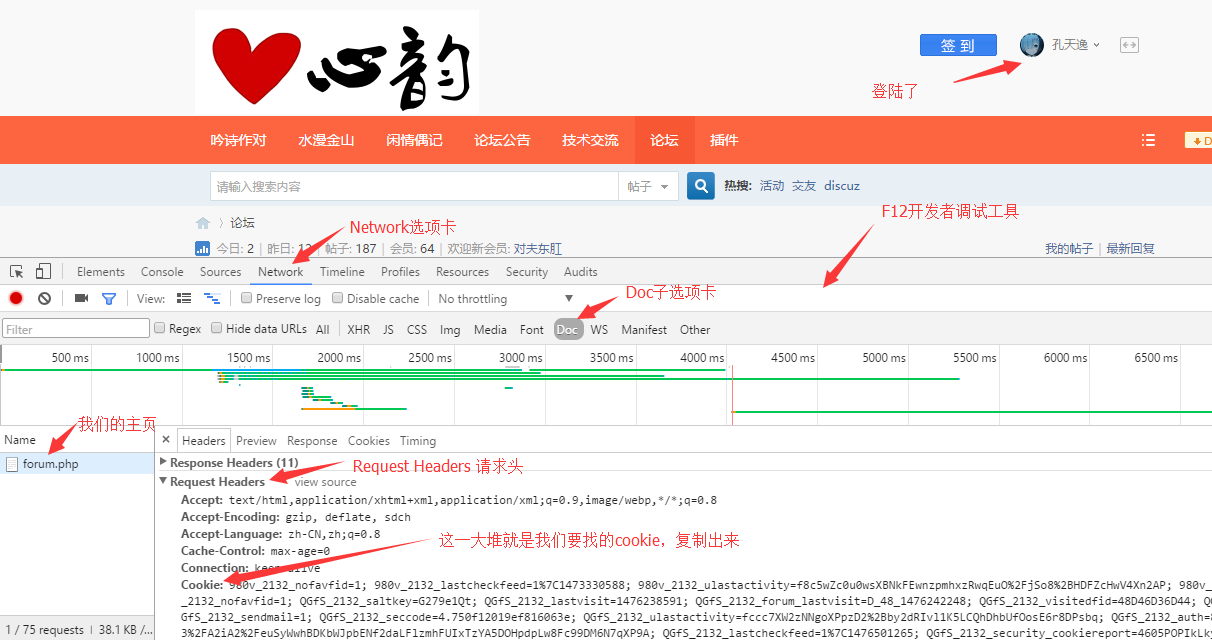
把cookie转化格式
在scrapy中,设置cookie需要是字典格式的,可是我们从浏览器Copy出来的是字符串格式的,所以我们需要写个小程序来转化一下
transCookie.py
# -*- coding: utf-8 -*-
class transCookie:
def __init__(self, cookie):
self.cookie = cookie
def stringToDict(self):
'''
将从浏览器上Copy来的cookie字符串转化为Scrapy能使用的Dict
:return:
'''
itemDict = {}
items = self.cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict
if __name__ == "__main__":
cookie = "你复制出的cookie"
trans = transCookie(cookie)
print trans.stringToDict()运行的效果如图
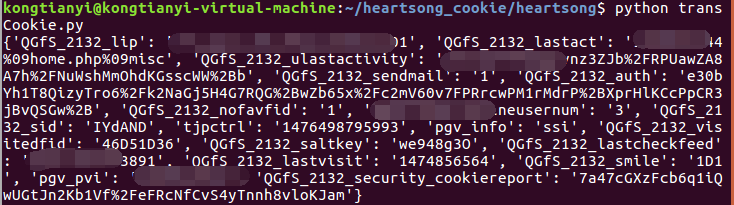
然后把这个字典复制出来。
给scrapy配置cookie
首先把刚才得到的cookie放到settings.py里
settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'heartsong'
SPIDER_MODULES = ['heartsong.spiders']
NEWSPIDER_MODULE = 'heartsong.spiders'
ROBOTSTXT_OBEY = False # 不遵守Robot协议
# 使用transCookie.py翻译出的Cookie字典
COOKIE = {'key1': 'value1', 'key2': 'value2'}然后编写爬虫文件
heartsong_spider.py
# -*- coding: utf-8 -*-
# import scrapy # 可以用这句代替下面三句,但不推荐
from scrapy.spiders import Spider
from scrapy import Request
from scrapy.conf import settings
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
# 主页,此例只下载主页,看是否有登录信息
"http://www.heartsong.top/forum.php"
]
cookie = settings['COOKIE'] # 带着Cookie向网页发请求
# 发送给服务器的http头信息,有的网站需要伪装出浏览器头进行爬取,有的则不需要
headers = {
'Connection': 'keep - alive', # 保持链接状态
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
# 对请求的返回进行处理的配置
meta = {
'dont_redirect': True, # 禁止网页重定向
'handle_httpstatus_list': [301, 302] # 对哪些异常返回进行处理
}
# 爬虫的起点
def start_requests(self):
# 带着cookie向网站服务器发请求,表明我们是一个已登录的用户
yield Request(self.start_urls[0], callback=self.parse, cookies=self.cookie,
headers=self.headers, meta=self.meta)
# Request请求的默认回调函数
def parse(self, response):
with open("check.html", "wb") as f:
f.write(response.body) # 把下载的网页存入文件总的来说一句话,就是带着cookie发起Request请求。
运行之后会将主页保存,我们打开文件查看一下效果
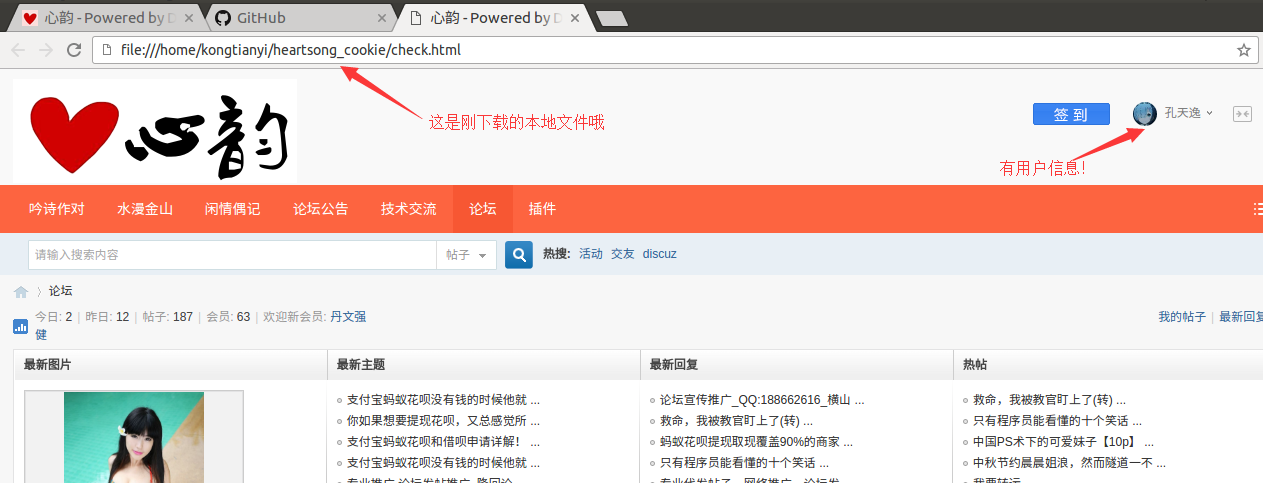
小结
本节介绍了cookie的获取方法和如何给scrapy设置cookie,下节我会介绍如果带着登陆状态去回复主题帖。















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











