







学习资料
慕课网——Hadoop大数据平台架构与实践–基础篇
设计架构
基本概念
- 块(Block)
- NameNode
- DataNode
HDFS的文件被分成块进行存储
HDFS块的默认大小为64MB
块是文件存储处理的逻辑单元,在此上进行存储、查找等操作
NameNode和DataNode是HDFS中的两类节点
NameNode是管理节点,存放文件元数据
- 文件与数据块的映射表
- 数据块与数据节点的映射表
DataNode是HDFS的工作节点,存放数据块
体系结构
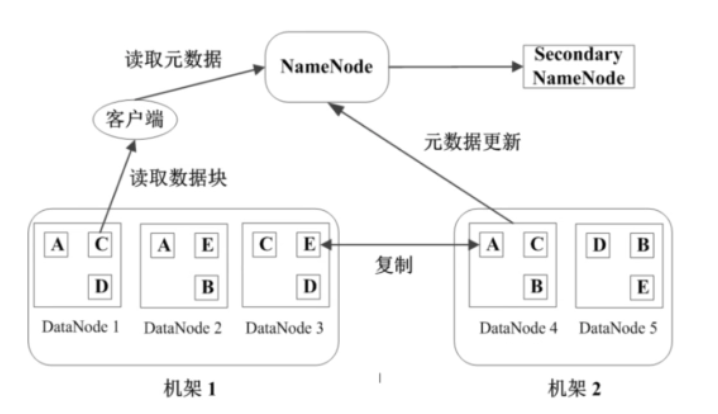
数据管理与容错
每个数据块3个副本,分布在两个机架内的三个节点,两份同一机架。如上图。
心跳检测
DataNode定期向NameNode发送心跳信息,报告自己的状态,是否正常。
二级NameNode
Secondary NameNode定期同步元数据映像文件和修改日志。当NameNode发生故障而瘫痪,二级NameNode会将它替换。
文件读取流程
- 客户端向NameNode发起文件读取请求
- NameNode查询元数据并返回
- 客户端读取Block并提取内容拼装
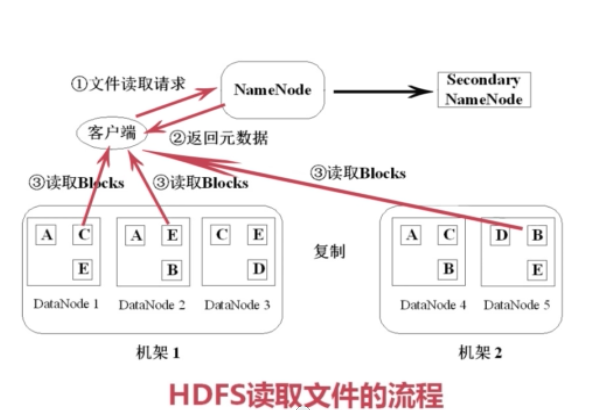
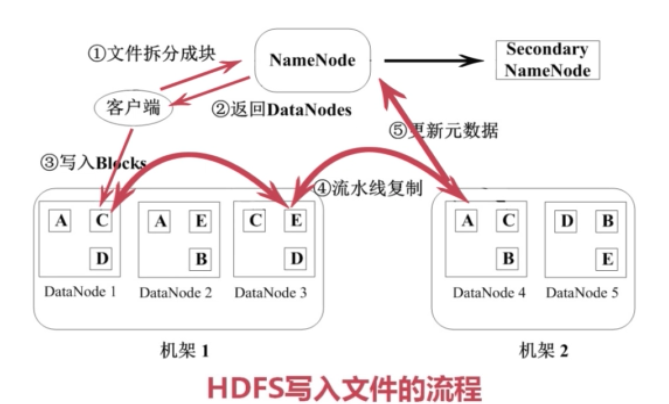
文件写入流程
- 文件拆分成块,通知NameNode
- 服务端返回可用的DataNode
- 写入Block
- 写入第一个块后,在DataNode间进行流水线复制
- 更新元数据,通知NameNode动作结束
- 重复以上步骤写其他块
HDFS特点
- 数据冗余,硬件容错
- 流式的数据访问,一次写入多次读取,无法随机修改,修改只能通过删除原数据再追加
- 存储大文件
适用性和局限性
- 适合数据批量读写,吞吐量高
- 不适合交互式应用,低延迟很难满足
- 适合一次写入多次读取,顺序读写
- 不支持多用户并发写相同文件
HDFS使用
打印HDFS内文件夹
hadoop fs -ls /创建目录
hadoop fs -mkdir input把本地文件提交到HDFS
hadoop fs -put localFile.xx aimPath/把HDFS内的文件下载
hadoop fs -get path/file.xx localFileName查看HDFS当前信息
hadoop dfsadmin -report
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











