







1:环境准备
3台服务器配置如下
公网ip 119.29.186.83 内网ip10.104.157.113
公网ip 119.29.250.47 内网ip 10.104.9.181
公网ip 119.29.251.99 内网ip 10.104.196.48
以上全是centos 7.2
安装java
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel //此时所有的机器的java都安装在同一个地方
//所有的机器修改profile文件增加这行代码
export JAVA_HOME=/usr/lib/jvm/java-openjdk2:配置hostname
在3台机器上分别执行
//主服务器
vim /etc/sysconfig/network
hostname=master
:wq
hostname master
exit
再次ssh登进
//从1
vim /etc/sysconfig/network
hostname=slave1
:wq
hostname slave1
exit
依次类推3:配置hosts文件
vim /etc/hosts
主服务器如下
10.104.157.113 master
119.29.250.47 slave1
119.29.251.99 slave2
从1
10.104.9.181 slave1
119.29.186.83 master
119.29.251.99 slave2
注意 本机的hostname与内网ip对应
其他的hostname与外网ip对应
然后依次ping master,ping slave14:增加hadoop用户
在各台机器上执行
useradd hadoop
passwd hadoop
并设置密码
vim /etc/sudoers
在root下面复制一行
将root改为hadoop5:配置ssh免登陆
3台服务器上都执行
ssh-keygen
然后一直回车
主服务器上执行:
ssh-copy-id hadoop@slave1
ssh-copy-id hadoop@slave2
从服务器上执行:
ssh-copy-id hadoop@master
ssh-copy-id slave1(其他hostname)6:关闭各机器防火墙
systemctl start firewalld
firewall-cmd --permanent --zone=public --add-port=50070/tcp //namenode web端口
firewall-cmd --permanent --zone=public --add-port=50070/udp
firewall-cmd --permanent --zone=public --add-port=9000/tcp //namenode rpc端口
firewall-cmd --permanent --zone=public --add-port=9000/udp
firewall-cmd --permanent --zone=public --add-port=50010/udp //datanode rpc端口
firewall-cmd --permanent --zone=public --add-port=50010/udp
firewall-cmd --permanent --zone=public --add-port=50075/udp //下载文件端口
firewall-cmd --permanent --zone=public --add-port=50075/udp
firewall-cmd --permanent --zone=public --add-port=8031/tcp //nodemanager rpc端口
firewall-cmd --permanent --zone=public --add-port=8031/udp
firewall-cmd --reload
以上所有端口在namenode和datanode均全部开启
需要什么端口可以自行开放(推荐一种暴力方法)
firewall-cmd --permanent --zone=public --add-port=10-50100/tcp
firewall-cmd --permanent --zone=public --add-port=10-50100/udp
firewall-cmd --reload7:创建运行目录
su hadoop
cd /home/hadoop
mkdir apps
将hadoop解压到apps文件夹下8:配置文件配置
cd /etc
vim hadoop-env.sh
将JAVA_HOME修改为本机的JAVA_HOME
JAVA_HOME=/usr/lib/jvm/java-openjdk9:公共参数配置
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> //文件系统
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> //临时目录
<value>/home/hadoop/hdpdata</value>
</property>
</configuration>10:文件系统配置文件
vim hdfs-site.xml
<property>
<name>dfs.replication</name> //副本数量
<value>2</value>
</property>11:mapreduce配置
vim mapreduce-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>12:yarn配置
vim yarn-site.xml
//yarn的主机
<property>
<name>yarn.resoucemanager.hostname</name>
<value>master</value>
</property>
//shuffle服务
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>13:分发
tar -zcvf hadoop-2.7.3.tar.gz hadoop-2.7.3/
scp -r hadoop-2.7.3.tar.gz hadoop@slave1:/home/hadoop/apps
scp -r hadoop-2.7.3.tar.gz hadoop@slave2:/home/hadoop/apps14:一键脚本启动
cd /etc/hadoop/
vim slaves然后在namenode上,(仅在namenode上修改slaves文件)
vim slaves (slaves文件在hadoop/etc目录中)
slaves文件内容:
slave1
slave2
之后在namenode上执行命令:
start-dfs.sh
start-yarn.sh
“`
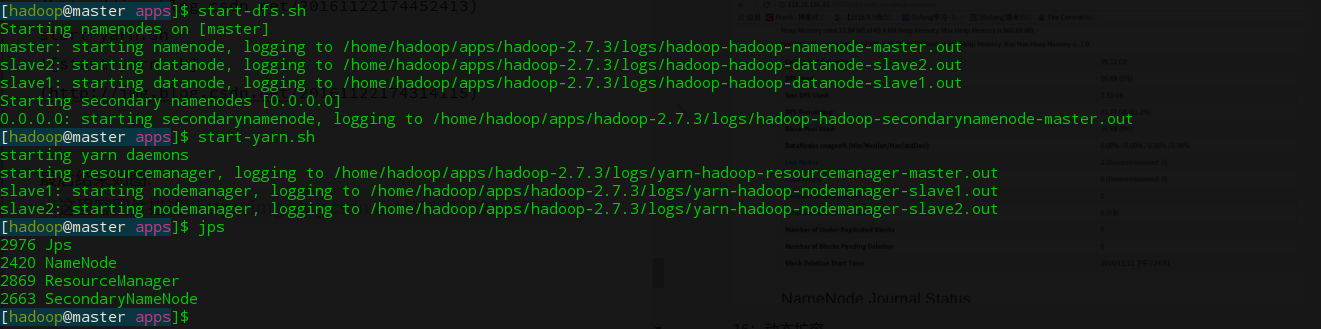
最后结果如图:
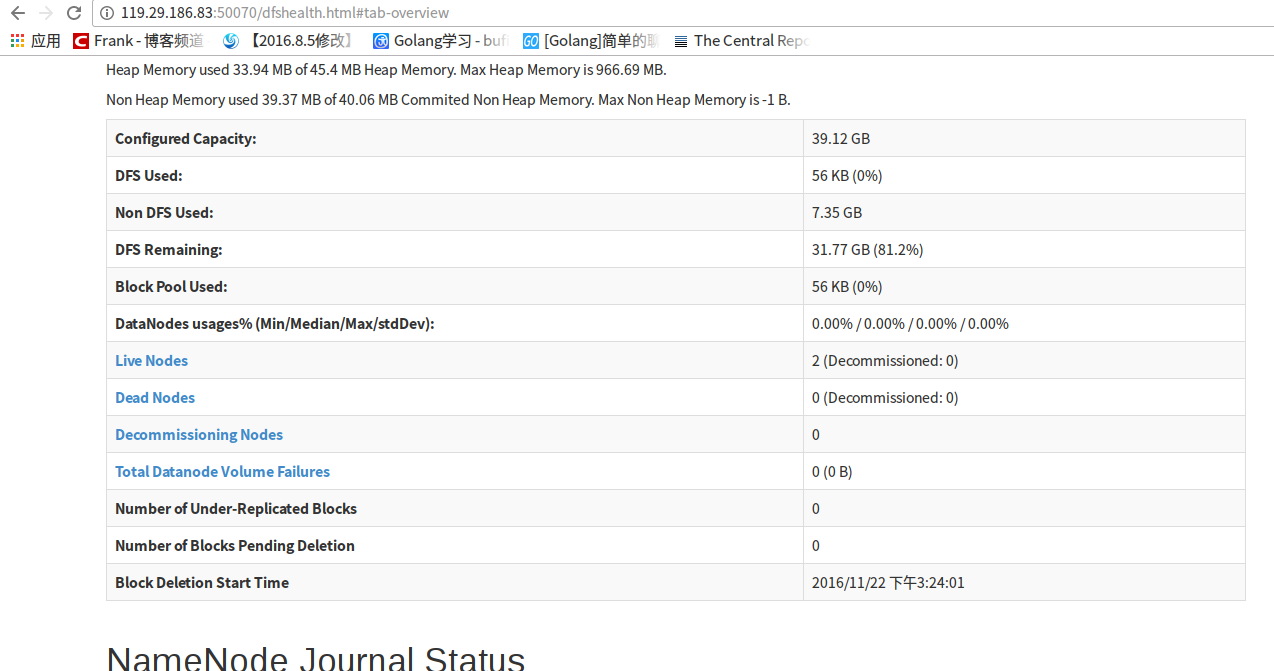
16:动态扩容
直接scp一份到一个服务器,起一个datanode即可
下线一台,由于数据有2份,所以完全不用担心














 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









