







引言
这学期上自然语言处理课,老师需要我们合作完成一项大作业。当时的我早已对知识图谱感兴趣,有种跃跃欲试的冲动。正好逢上这样的一次机会,所谓初生牛犊不怕虎,我就报上了“基于知识图谱的电影自动问答系统”。但是我后来才发现,这项目的难度真的挺大,要做好不容易呀。
关于本体、知识库、知识图谱
本体(Ontology),是知识库本身的存在。维基百科的定义是“a formal naming and definition of the types, propreties,and interrelationships of entities that really or fundamentally exist for a particular domain of discourse”。例如我是一个人,人就是type;我有性别、年龄,这些是property。而我与爸爸构建父子关系,就是interrelationships。
知识库(Knowledge Base),就是很多本体的集合。例如百度百科里面的百度人物。
知识图谱(Knowledge Graph), 源自于Google的知识库的名字(The Knowledge Graph is a knowledge base used by Google to enhance its search engine‘s search results with semantic-search informantion gathered from a wide variety of sources)。不过现在人们对知识图谱的研究越来越感兴趣,尤其在知识的存储和推理上。
上面的观点,我主要摘自于知乎上:
https://www.zhihu.com/question/34835422/answer/60367501
电影数据的获取
数据的获取主要锁定多个电影网站信息源,通过分布在不同电脑的爬虫文件,聚合了电影百度百科、豆瓣网、时光网、M1905、中国电影票房网等各大电影门户网站的电影信息。我们一共爬取了 997 部电影信息,爬取后利用正则表达式匹配得到相应的内容。当时爬虫的工作确实比较繁琐,而且需要改动非常多的正则。不过现在我们有了新的想法,也正在研制一个TinySpider,将爬虫与提取分离出来,同时实现分布式。
关于数据爬虫的代码,我放置到我的github上:电影数据的获取
数据的存储及查询
我主要采用的是Neo4j。Neo4j 是一个无框架数据库,它将数据作为顶点和边存储,适合知识图谱的存储结构。在开始添加数据之前,不需要定义表和关系。一个结点可以具有任何属性,任何结点都可以和其他结点建立关系。Neo4j 的查询语言 Cypher 是一种对图形声明查询的语言,使用图形模式匹配作为主要的机制来处理图形数据选择。Neo4j 提供 Java 版的基本操作 API 接口,方便融合到整个系统当中。
关于neo4j的安装使用,我放到博客:http://blog.csdn.net/qq_30843221/article/details/53306540
至于neo4j的JAVA学习,我推荐我师妹的一份博客:http://blog.csdn.net/yinglish_/article/details/54565449
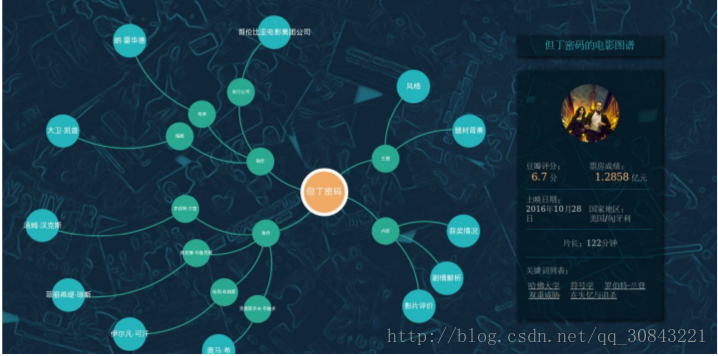
我们主要构建以电影为核心的知识图谱,以电影名称为根节点,以此延伸出电影的主题、内容、制作和角色,每一级节点又可以延伸至下一级的节点。图谱的深度为 3。根节点和叶子节点都有他的知识卡片。我们看到电影的根节点含有电影的摘要信息,例如豆瓣评分、票房成绩等等.另外, 出品公司、导演都有他们各自的知识卡片。
我们还研制出一个可视化的前端效果,主要利用echart来做
后记
这里只是讲了关于知识收集与存储的模块,我会在下一篇博客中谈到如何做自动问答系统
基于知识图谱的电影自动问答系统(二)自动问答实现














 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









