









1 .安装jdk
先下载JDK安装包,一般不支持用wget下载,因为oracle 官网下载需要接受证书,所以先下载完,然后上传到linux环境中,/usr/local/jdk1.8.0_60 是jdk解压的目录
vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_60
JRE_HOME=$JAVA_HOME/jre
CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH最后: source /etc/profile
2.下载Hadoop
http://apache.claz.org/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
1. 解压压缩包 /opt/hadoop-2.7.1.tar.gz
tar -zxvf hadoop-2.7.1.tar.gz
2. 切换到 /opt/hadoop-2.7.1/etc/hadoop 有四个文件需要改
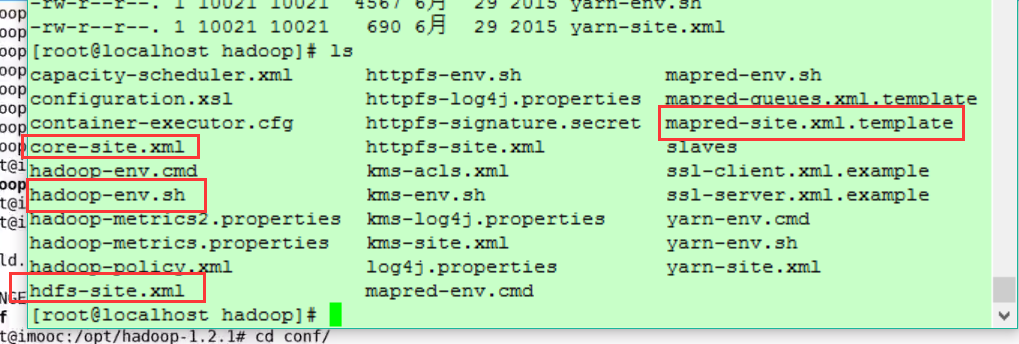
其中 mapred-site.xml.template需要复制一份mapred-site.xml
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value> 这里的localhost最好写当前主机的ip
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_60hdfs-site.xml
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
<property>
<name>dfs.web.ugi</name>
<value>ThinkPad,supergroup</value>
</property>
</configuration>
然后修改配置文件 vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_60
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/opt/hadoop-2.7.1/
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH最后格式化一下namenode,
/opt/hadoop-2.7.1/sbin,
hadoop namenode -format,然后 将服务启动 /opt/hadoop-2.7.1/sbin/start-all.sh
jps 查看一下已经启动的服务
[root@VM_33_17_centos hadoop]# jps
15939 NameNode
29302 SecondaryNameNode
29143 DataNode
26216 Jps
29743 NodeManager
29455 ResourceManager
[root@VM_33_17_centos hadoop]#
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









