







Linear Regression with One Variable
=========================Model and Cost Function=================================
costfunction函数体现的假设函数与训练数据的误差的大小

Hypothesis: 假设
Parameters: 通过训练数据进行训练的参数
CostFunction:代价函数
Simplified: 是简化的假设,即令theta0=0
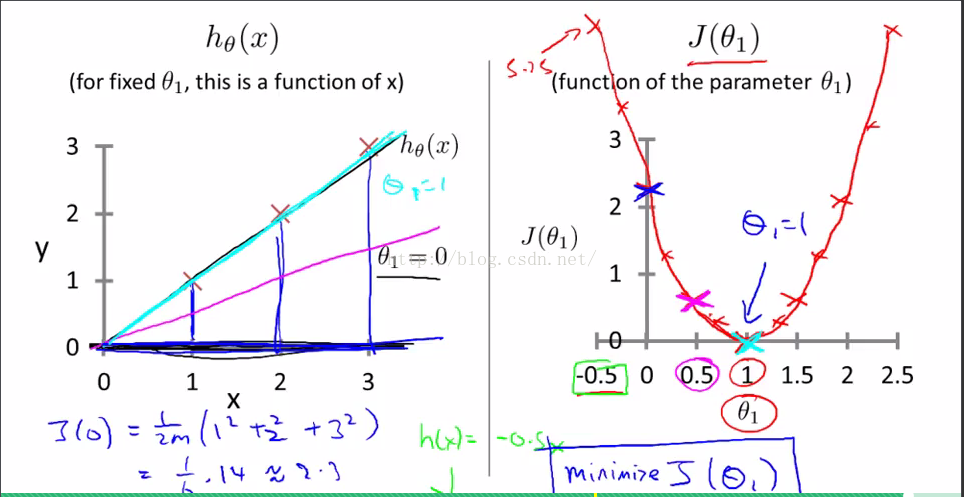
h(x)=theta0+theta1*x
左图为不同的theta1的h(x)图像,右图是theta=0,theta1变化的costfuntion图像
注:
浅蓝色为theta0=0,theta1=1时,h(x)图像和其在costfuntion中的点的位置
紫红色为theta0=0,theta1=0.5时,h(x)图像和其在costfuntion中的点的位置
浅蓝色为theta0=0,theta1=0时,h(x)图像和其在costfuntion中的点的位置
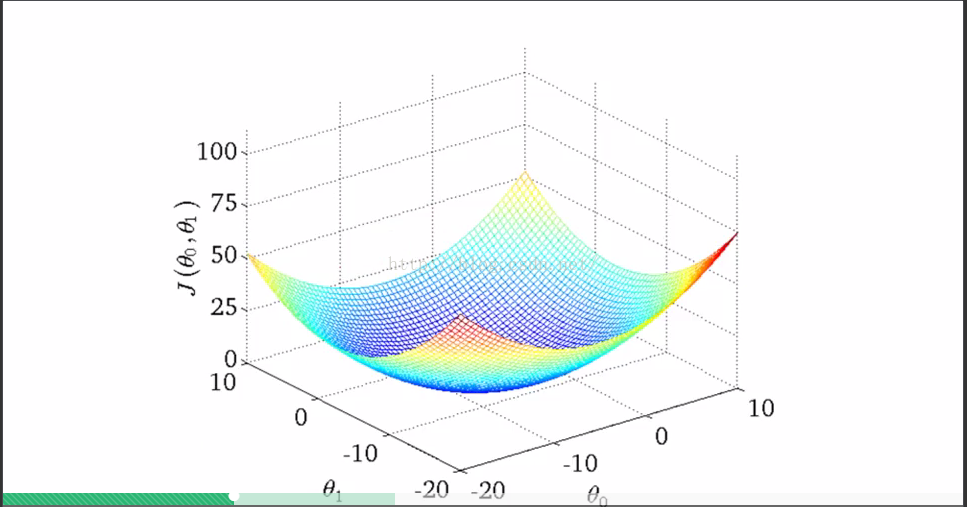
此图是costfunction关于theta0和theta1的关系三维图
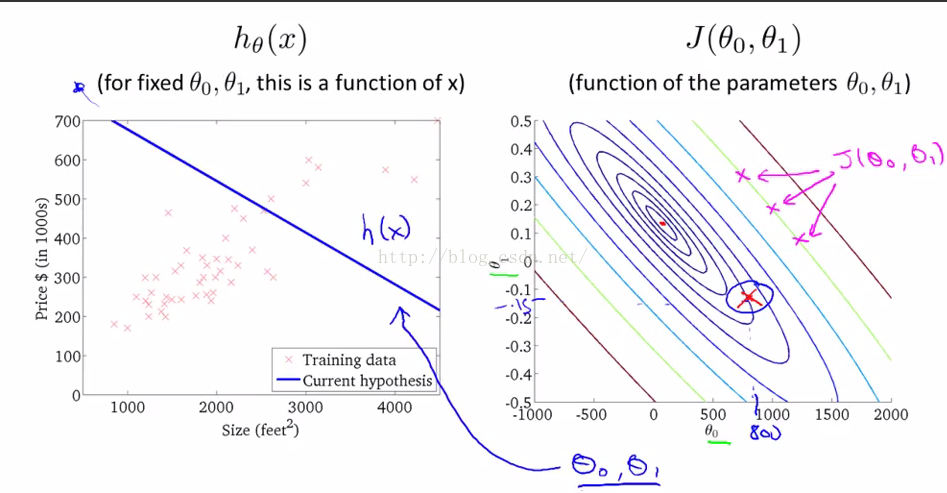
此图是costfunction关于theta0和theta1的二维图像
1、 同一个闭合圆圈的costfunction的值是一样的
2、 图像中心的点则是costfunction的最小值点
===========================Parameter Learning====================================
gradient-descent(梯度下降算法)
作用:用于寻找costfunction的最小值
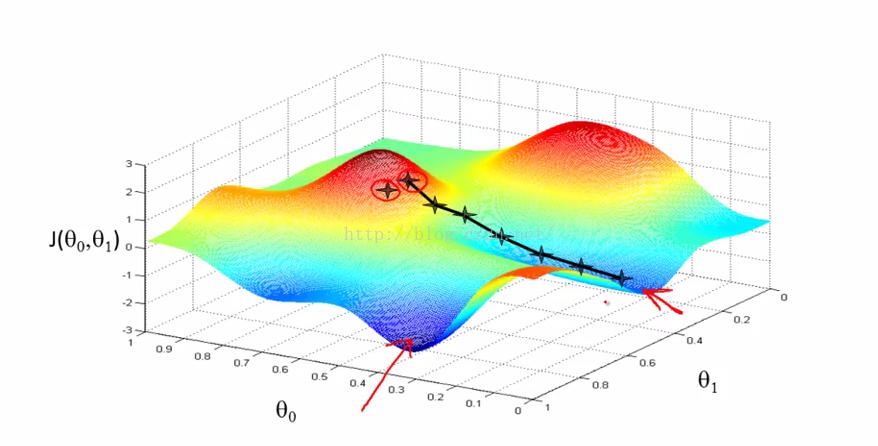
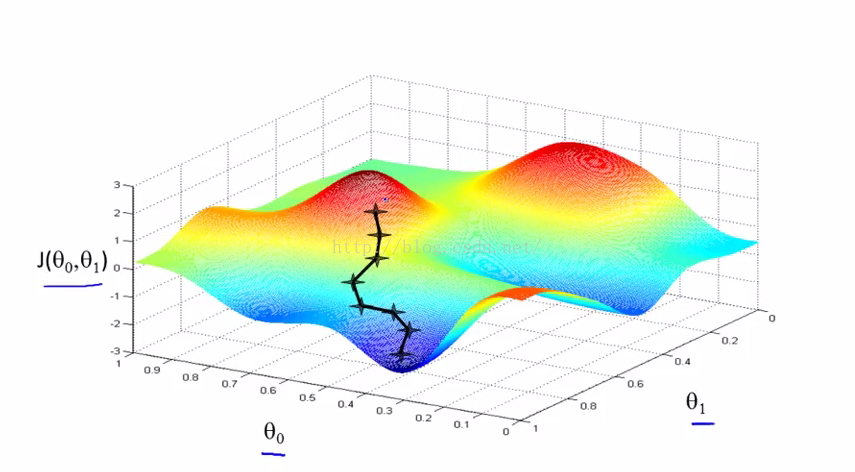
从上面的两幅图可以看出,从不同的点出发,下降的路线是不一样的。
所以可以看出梯度下降算法寻找的是局部最小值,而不是全局的最小值。

此PPT展示了梯度下降算法。
注:theta0和theta1是同时更新的,右下图是错误的。
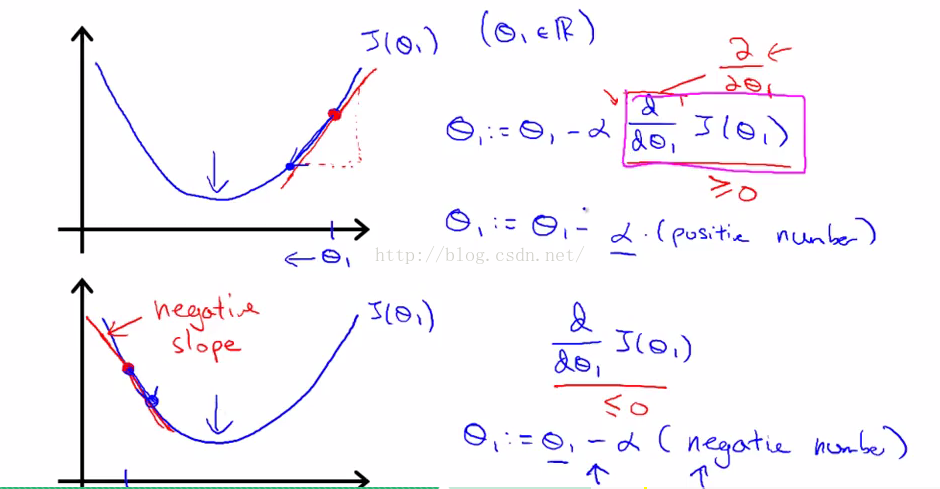
极点附近的下降方式,即偏导数为正或者为负。
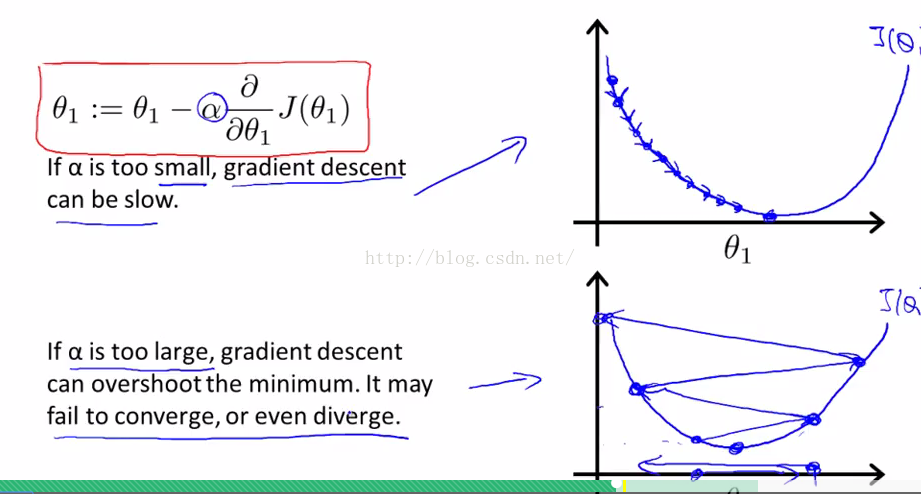
学习速率α过大或者过小的情况

将梯度下降算法和线性回归模型的结合。
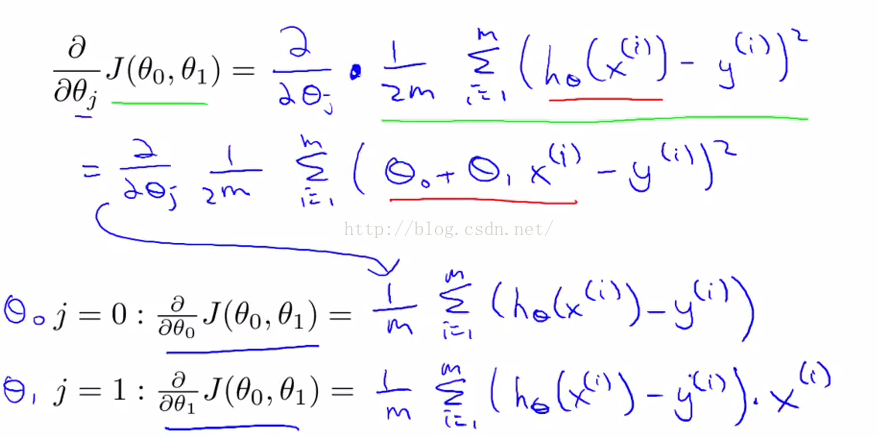
将梯度下降算法应用到线性回归模型中,梯度下降算法中偏导数的求法。

求偏导数数的公式

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









