







简介
kd树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
一个KDTree的例子
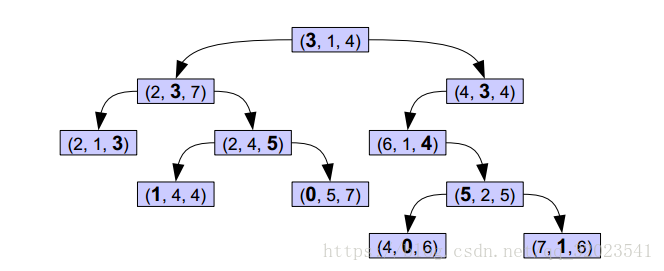
上图的树就是一棵KDTree,形似二叉搜索树,其实KDTree就是二叉搜索树的变种。这里的K = 3.
首先来看下树的组织原则。将每一个元组按0排序(第一项序号为0,第二项序号为1,第三项序号为2),在树的第n层,第 n%3 项被用粗体显示,而这些被粗体显示的树就是作为二叉搜索树的key值,比如,根节点的左子树中的每一个节点的第一个项均小于根节点的的第一项,右子树的节点中第一项均大于根节点的第一项,子树依次类推。
对于这样的一棵树,对其进行搜索节点会非常容易,给定一个元组,首先和根节点比较第一项,小于往左,大于往右,第二层比较第二项,依次类推。
分割的概念
看了上面的例子,确实比较简单,但不知道为何要这样做,这里从几何意义出发,引出分割的概念。
先看一个标准的BSTree,每个节点只有一个key值。
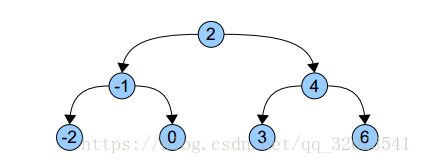
将key值对应到一维的坐标轴上。
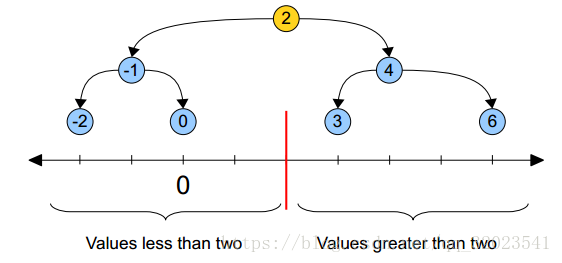
根节点对应的就是2,左子树都在2的左边,右子树都在2的右边,整个一维空间就被根节点分割成了两个部分,当要查找结点0的时候,由于是在2的左边,所以可以放心的只搜索左子树的部分。整个搜索的过程可以看成不断分割搜索区间的过程,直到找到目标节点。
这样的分割可以扩展到二维甚至更多维的情况。
但是问题来了,二维的节点怎么比较大小?
在BSTree中,节点分割的是一维数轴,那么在二维中,就应当是分割平面了,就像这样:

黄色的点作为根节点,上面的点归左子树,下面的点归右子树,接下来再不断地划分,最后得到一棵树就是赫赫有名的BSPTree(binary space partitioning tree). 分割的那条线叫做分割超平面(splitting hyperplane),在一维中是一个点,二维中是线,三维的是面。
KDTree就是超平面都垂直于轴的BSPTree。同样的数据集,用KDTree划分之后就是这样:
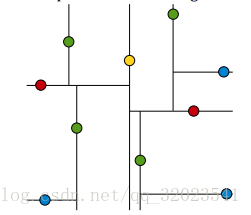
黄色节点就是Root节点,下一层是红色,再下一层是绿色,再下一层是蓝色。为了更好的理解KDTree的分割,我们在图形中来形象地看一下搜索的过程,假设现在需要搜寻右下角的一个点,首先要做的就是比较这个点的x坐标和root点的x坐标值,由于x坐标值大于root节点的x坐标,所以只需要在右边搜寻,接下来,要比较该节点和右边红色节点y值得大小...后面依此类推。整个过程如下图:
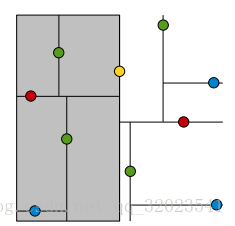
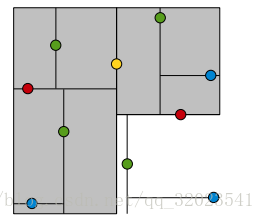
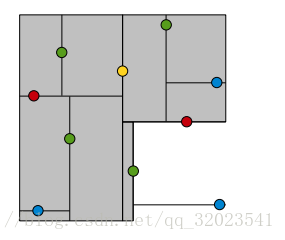
理解完KDTree之后,下面要说的就是关于KDTree的两个最重要的问题:
1.树的建立;
2.最近邻域搜索(Nearest-Neighbor Lookup)。
树的建立
先定义一下节点的数据结构。每个节点应当有下面几个域:
Node-data - 数据矢量, 数据集中某个数据点,是n维矢量(这里也就是k维)Range - 空间矢量, 该节点所代表的空间范围
split - 整数, 垂直于分割超平面的方向轴序号
Left - k-d树, 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树
Right - k-d树, 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树
parent - k-d树, 父节点
建立树最大的问题在于轴点(pivot)的选择,选择好轴点之后,树的建立就和BSTree差不多了。
建树必须遵循两个准则:
1.建立的树应当尽量平衡,树越平衡代表着分割得越平均,搜索的时间也就是越少。
2.最大化邻域搜索的剪枝机会。
第一种选取轴点的策略是median of the most spread dimension pivoting strategy,对于所有描述子数据(特征矢量),统计他们在每个维度上的数据方差,挑选出方差中最大值,对应的维就是split域的值。数据方差大说明沿该坐标轴方向上数据点分散的比较开。这个方向上,进行数据分割可以获得最好的平衡。数据点集Data-Set按照第split维的值排序,位于正中间的那个数据点 被选为轴点。
但是问题来了,理论上空间均匀分布的点,在一个方向上分割只有,通过计算方差,下一次分割就不会出现在这个方向上了,但是一些特殊的情况中,还是会出现问题,比如
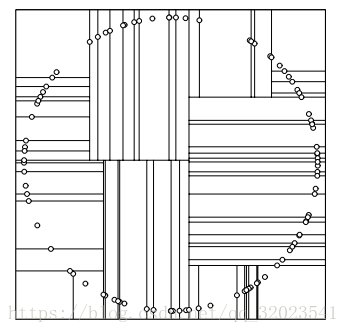
这样就会出现很多长条的分割,对于KDTree来说是很不利的。
为了避免这种情况,需要修改一下算法,纬度的选择的依据为数据范围最大的那一维作为分割纬度,之后也是选中这个纬度的中间节点作为轴点,然后进行分割,分割出来的结果是:
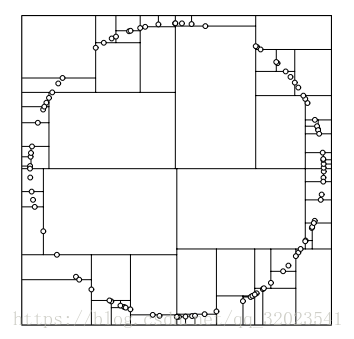
这样的结果对于最邻近搜索是非常友好的。
但是这样做还是有一些不好,就是在树上很可能有一些空的节点,当要限制树的高度的时候,这种方法就不合适了。
最邻近搜索
给定一个KDTree和一个节点,求KDTree中离这个节点最近的节点.(这个节点就是最临近点)
这里距离的求法用的是欧式距离。
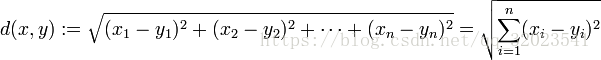
基本的思路很简单:首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于就进入左子树分支,等于就进入右子树分支直到叶子结点),顺着“搜索路径”很快能找到最近邻的近似点,也就是与待查询点处于同一个子空间的叶子结点;然后再回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中去搜索(将其他子结点加入到搜索路径)。重复这个过程直到搜索路径为空。
这里还有几个细节需要注意一下,如下图,假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
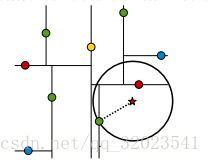
判断轴是否与候选超球相交的方法可以参考下图:

下面再用一个例子来具体说一下查询的过程。
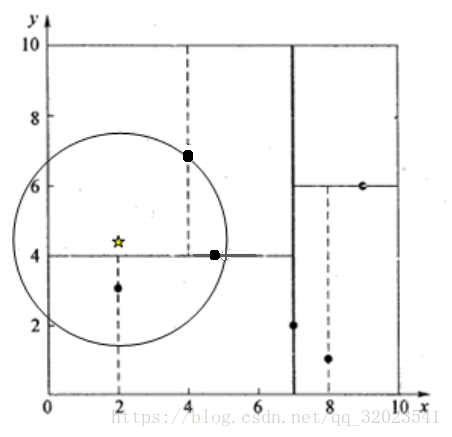
假设我们的k-d tree就是上面通过样本集{(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)}创建的。
我们来查找点(2.1,3.1),在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点为<(7,2), (5,4), (2,3)>,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141;
然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和超平面y=4相交,如下图,所以不必跳到结点(5,4)的右子空间去搜索,因为右子空间中不可能有更近样本点了。
于是在回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最近邻点,最近距离为0.141。

再举一个稍微复杂的例子,我们来查找点(2,4.5),在(7,2)处测试到达(5,4),在(5,4)处测试到达(4,7),然后search_path中的结点为<(7,2), (5,4), (4,7)>,从search_path中取出(4,7)作为当前最佳结点nearest, dist为3.202;
然后回溯至(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交,如下图,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到search_path中,现在search_path中的结点为<(7,2), (2, 3)>;另外,(5,4)与(2,4.5)的距离为3.04 < dist = 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
回溯至(2,3),(2,3)是叶子节点,直接平判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为(1.5)
回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交, 所以不用跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点,最近距离为1.5。
所以在搜索中可能会出现不同的情况,比如下面的两张图就是比较极端的两个例子
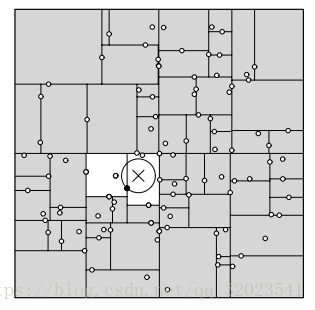
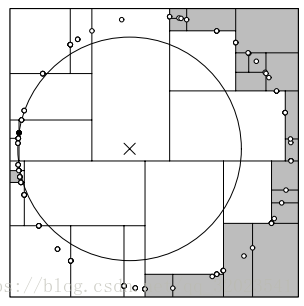














 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









