










本文概述:
1、什么是ZooKeeper?
2、ZooKeeper概述
3、Hadoop生态系统中那些框架使用到了ZooKeeper
4、ZooKeeper的架构
5、ZooKeeper核心组件
6、ZooKeeper的数据结构
7、Watch触发器
8、哪些框架使用到了ZooKeeper
9、ZooKeeper应用举例
10、节点属性
11、Znode的两种类型
12、ZooKeeper应用场景
13、ZooKeeper的安装
14、zk客户端的使用
15、使用Java API操作ZK
什么是ZooKeeper?
ZooKeeper是一个集中服务,用于维护配置信息,命名,提供分布式同步和提供组服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次实施时,都有很多工作要解决不可避免的错误和竞争条件。由于实施这些服务的困难,最初的应用程序通常会吝啬,这使得它们在变化和难以管理的情况下变得脆弱。即使正确完成,这些服务的不同实现会导致部署应用程序时的管理复杂性。
ZooKeeper概述
1、是一个开发和维护开源服务器的努力,它使高度可靠的分布式协调成为可能
2、是一个为用户的分布式应用程序提供协调的服务
是为别的分布式程序服务的
本身也是一个分布式程序(只要半数以上节点存储能正常提供服务)
3、目标是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户
4、随着发展我们在一台机器上运行的程序任务越来越重,资源请求越来越大,根据不同的情况主要有如下的解决方案一个是负载技术,一个是分布式技术
负载技术:主要解决资源使用压力
分布式技术:主要是把应用任务横向切分,跑在不同的机器上通过rpc协作为外部提供整体服务。
在以上的技术中主要面临的问题有:1,数据同步,2,分布式进程协作
zookeeper是其中一种可以为上述问题提供有效的解决方案的技术框架,所以我们下面先认识它。
Hadoop生态系统中那些框架使用到了ZooKeeper
HDFS HA:自动切换
HBase:master选举机制
Kafka:通信
Spark:
ZooKeeper的架构
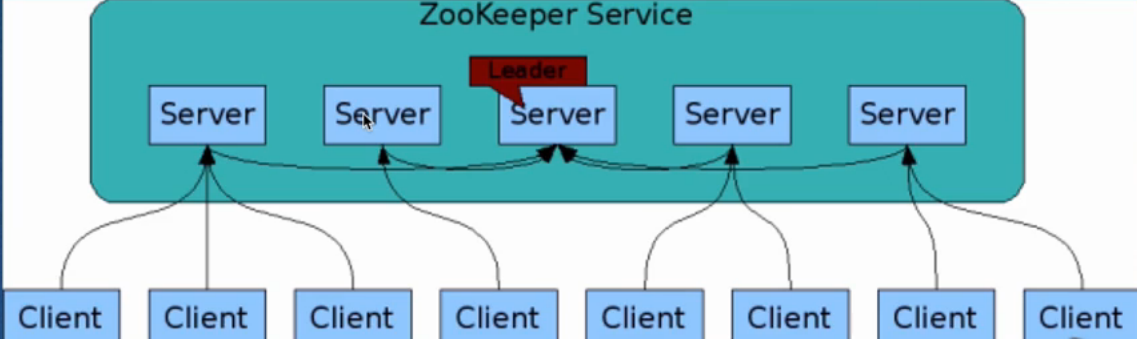
1)一个ZK集群中由一组Server节点构成
2)这一组Server节点中存在一个角色为Leader的节点,剩下的其他的节点都是Follower
3)当客户端Client连接到ZK集群时,并且执行读写请求,这些请求会被发送到Leader节点上
4)然后Leader上数据变更会同步到集群的其他的Follower节点
5)Leader节点接收到数据变更请求之后,首先将变更写入到本地磁盘(为了以后容错、恢复之用),当所有的写请求持久化到磁盘之后,才会将变更应用到内存中
6)当当前的Leader发生故障无法提供服务之后,故障/失败容错是快速响应的,会从Follower中选择,一个做为Leader(选择),新的Leader继续做为分布式协调服务的中心,处理所有Client发起的请求。
ZooKeeper核心组件
Server:数目一般选择为奇数3、5、7
Leader:
Leader选举算法是采用了Paxos协议:当
多数server写成功,则任务数据写成功
多数server:只要集群中有过半的机器是正常工作的,那么整个集群对外就是可用的
2n和2n-1的死亡容忍度是一样的,都是n-1
问题:何必增加那么一个不必要的ZK呢?
结论:ZK中的Server个数就是采用奇数个比较合适:3、5、7
Follower:一个Leader可以有很多Follower
Client:命令行或者API
ZooKeeper的数据结构
1)层次化的目录结构,命名是有规范
2)每个节点叫做znode,znode是有唯一的标识的
3)znode的数据是带有版本,比如说某个znode可以存放多个数据版本,在使用时可以直接根据版本号获取数据
4)节点数据必须是一次性完成完整的读写
节点属性:
cZxid: 是节点的创建时间所对应的Zxid格式时间戳。
mZxid:是节点的修改时间所对应的Zxid格式时间戳。
version:节点数据版本号
cversion:子节点版本号
aversion:节点所拥有的ACL版本号
Znode的两种类型:
1)短暂的(ephemeral)
客户端会话结束,那么zk就会将该类型的node删除,该类型的node是不可以有子节点
2)持久的(persistent)
就依赖于客户端会话,只有当客户端明确的使用命令或者是API的方式要删除该节点时才会被删除
Watch触发器

ZooKeeper可以为所有的读操作设置watch,这些读操作包括:exists()、getChildren()及getData()。watch事件是
一次性的
触发器,当watch的对象状态发生改变时,将会触发此对象上watch所对应的事件。watch事件将被异步地发送给客户端,并且ZooKeeper为watch机制提供了有序的一致性保证。理论上,客户端接收watch事件的时间要快于其看到watch对象状态变化的时间。
哪些框架使用到了ZooKeeper
HDFS HA
HBase
Kafka
Spark
dubbo
……
ZooKeeper应用举例
至此你了解了zk,那么我们能做什么?
1,选举
2,分布式锁
3,分布式队列
4,分布式事务
5,分布式隔离
6,数据同步
…..
选举,分布式锁可以应用在具有单点故障的问题中利用选举确定唯一的active,利用分布式锁防止“脑裂”
分布式队列可应用在分布式共享资源消费中
分布式事务,可以应用在rpc协作中
ZooKeeper应用场景
配置管理
在分布式集群中,各个节点的配置文件同步文件。对集群中的一台机器的配置信息修改之后,希望能够快速同步到其他各个节点上,这可以交由ZooKeeper来实现
将配置文件信息写入到ZooKeeper的一个znode上各个节点监听这个znode即可
ZooKeeper的安装
2)解压
bin: 启动脚本(删除.cmd)
conf:存放的 的配置文件
zoo.cfg
tickTime=2000 选票的默认时间
initLimit=10 初始化连接数
syncLimit=5 同时连接数
dataDir=/home/hadoop/app/zk/tmp/zookeeper 数据存储的目录
clientPort=2181 端口号
3)添加到系统环境变量
#zookeeper
export ZK_HOME=/home/hadoop/app/zk
export PATH=$ZK_HOME/bin:$PATH
重启:source ~/.bashrc
4) 启动zk
zkServer.sh start
5)检测启动是否成功
jps:QuorumPeerMain
6)其他
停止:./zkServer.sh stop
查看运行状态:./zkServer.sh status
zk客户端的使用
1)启动 zkCli.sh
2) 如何查看帮助: help
常用:
ZooKeeper -server host:port cmd args
connect host:port:远程连接
get path [watch]:获得值
ls path [watch]:查看
set path data [version]:设置
rmr path:删除
delquota [-n|-b] path:
quit :退出
printwatches on|off:
create [-s] [-e] path data acl:创建
stat path [watch]
close
ls2 path [watch]
history
listquota path
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
3)客户端常用命令
ls /:查看
create /node test:创建
get /node:获取
set /node test1:修改
rmr /node:删除
quit:退出
使用Java API操作ZK
常用操作命令:
create :创建Znode,父Znode必须存在
delete:删除Znode,Znode没有子节点
exists:测试Znode是否存在,并获取他的元数据
getAll/setAll:为Znode获取/获取ACL
getChildren:获取Znode所有子节点的列表
getData/setData:获取/设置Znode的相关数据
sync:使客户端的Znode视图与Zookeeper同步
1) pom.xml中添加zk的依赖
<
dependency
>
<
groupId
>
org.apache.hadoop
</
groupId
>
<
artifactId
>
zookeeper
</
artifactId
>
<
version
>
3.3.0
</
version
>
<
exclusions
>
<
exclusion
>
<
groupId
>
log4j
</
groupId
>
<
artifactId
>
log4j
</
artifactId
>
</
exclusion
>
</
exclusions
>
</
dependency
>
2)使用单元测试进行操作ZK















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









