









哈夫曼树是大二上学期的时候作为大一下学期的数据结构的课程设计的,所幸上学期并没有在学习了一些基础的数据结构之后就此忘记,而是自己在有空的时候自己去实现了它们。即是如此,在初步了解哈夫曼的原理之后,我只是隐隐约约的了解它的原理,在完成它的过程之中,依旧遇到了许多的问题,但是一切都已经成功的克服,下面我会简单的介绍哈夫曼编码的压缩和解压缩的原理。
Ⅰ.哈夫曼原理
哈夫曼是利用字符在一个文件中字符出现的次数作为频度构建哈夫曼树,遍历哈夫曼树就可以得到每一个字符的哈夫曼树,在哈夫曼树上,出现频率
最高的字符将被最短的字符作为代替,每一个源文件之中的字符都对应了一个哈夫曼编码,将哈夫曼编码来代替源文件之中的每一个字符写入
到压缩文件之中。这样,字符或多或少的减少了在文件中的存储长度,从而达到了文件的压缩效果。
Ⅱ.哈夫曼树的构建
⒈统计源文件之中字符的频度,并按照字符频度从小到大排列
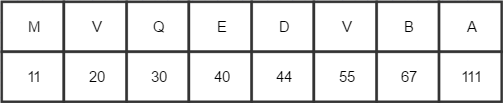
2.构建哈夫曼树
哈夫曼树是一棵有着特殊规则的二叉树,哈夫曼树是自下而上构建的,这一棵树每一个叶子节点都存储的是一个有效的字符和字符频度,非叶子的
节点存储的是NULL和左右子树的字符频度之和。所以,每次取出字符频度的两个子树构成一个哈夫曼树,最后直到所有节点全部化为一棵哈夫曼树。
二叉树的合并,已经不是类似于数组的数据结构可以简单解决的,我选择的是队列,队列的节点被初始化为指向一棵二叉树的根节点和指向下一个
节点。
struct Queue_Node
{
Trees_Node *Trees_Root;
Queue_Node* Next_Node;
Queue_Node(char letter = NULL, unsigned int weight = 0)
{
Binary_Trees *p = new Binary_Trees(letter, weight);
Trees_Root = p->Root_Point;
Next_Node = NULL;
}
};
哈夫曼树的合并简单图解如下:
将每一个字符和字符频度都转化为一棵二叉树串入到队列中去
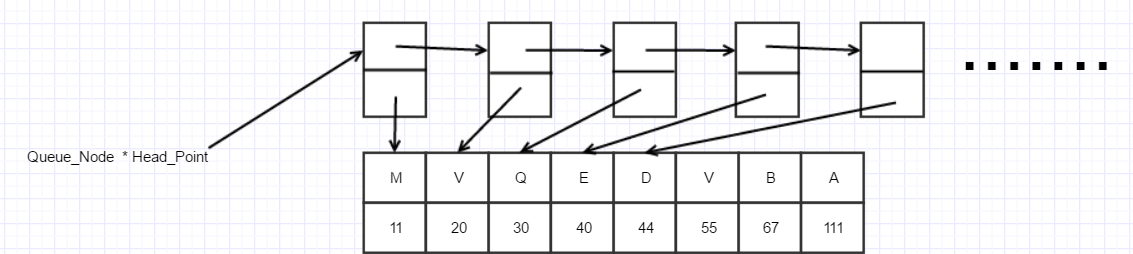
将树根频度最小的两棵子树合并为一棵哈夫曼树,再对它们进行排列,再取出频度最小的两棵哈夫曼树合并,知道最后合并为队列只剩一个节点,
哈夫曼树就构成了。
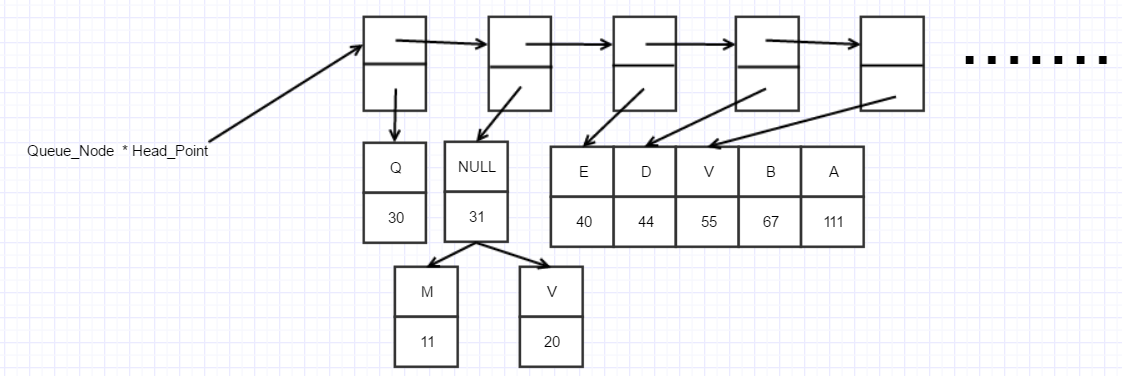
这是上面的字符频度构建的哈夫曼树
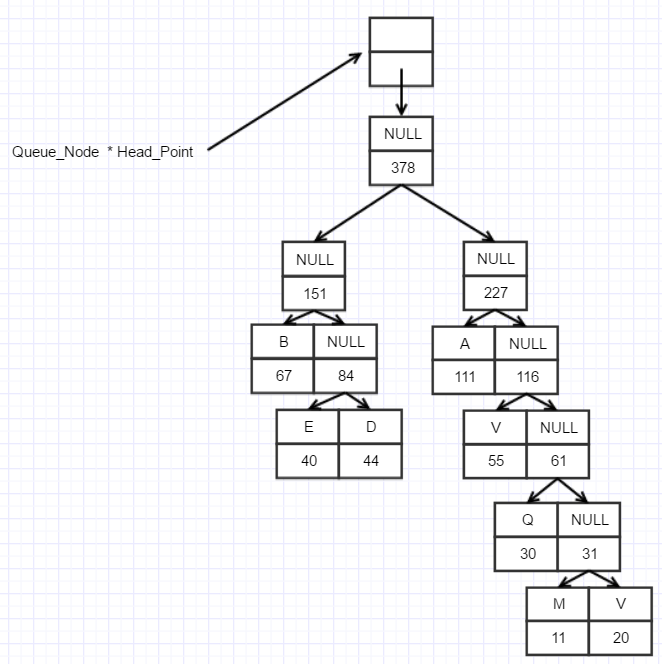
Ⅲ.获取哈夫曼编码
这是一棵以NULL和378为根节点的二叉树,我们规定每一个叶子节点的字符都有一个哈夫曼编码,并规定从根节点遍历到这个叶子节点的
路径编码为哈夫曼编码。令左子树为1,右子树为0。如E:101,D:100,A:10,其他的哈夫曼编码以此推理得到。
现在要做的就是将哈夫曼编码读取并存储,可以使用栈来遍历二叉树,遇到叶子节点就逆序寻找到根节点,二叉树的结构中存有指向父节点的指针,
再将编码逆序就得到哈夫曼编码了。
Ⅳ.哈夫曼编码压缩
现在我们要做的就是将源文件里面的字符替换为哈夫曼编码,现在也许应该有人应该有疑惑?我们读取文件并统计文件的字符都是使用unsigned char,
它只能存储256个字符,所以我们应该是按照读取二进制文件的方式来读取文件,无论什么内容,都按照一个字节的大小进行读取,但是我们我们却将
一个A(一个字节大小)转化为10(两个字节大小),这样岂不是只会比原来的文件更大了吗?所以我们将AAAA编码得到的哈夫曼编码10101010(0~255)
需要转化为一个unsigned char字符存入压缩文件之中。这样,四个字符不就成了一个字符,达到了压缩的效果。我们需要先将源文件之中所有的字符
都转化为哈夫曼编码,再将它们每8位转化为一个unsigned char存入到压缩文件之中。最后的不足8位的编码将补充0补足8位。
Ⅴ.哈夫曼解压缩
要想对压缩文件进行解压缩,我们需要得到哈夫曼树,所以我们需要在压缩文件前面写入哈夫曼树的信息,我将字符和对应频度写入到压缩文件中,
重新构建哈夫曼树。由于最后8位当中有0的存在,我还需要在最前面写入源文件字符总数,对最后的0可以进行丢弃不处理。
压缩文件写入内容如下:源文件字符总数,数组长度(字符类型个数),字符和字符对应频度,压缩内容
-----------------------------------------------------分割线--------------------------------------------------------------
下面贴出哈夫曼压缩的源代码:
Ⅰ.栈的头文件(Stack.h):栈是为了遍历二叉树而写,只是实现了一些最基本的方法。
#pragma once
#ifndef STACK_H_INCLUDED
#define STACK_H_INCLUDED
#include <iostream>
using namespace std;
template<class T>
struct Stack_Node
{
T Date;
Stack_Node* Next_Node;
Stack_Node(T date = 0)
{
Date = date;
Next_Node = NULL;
}
};
template<class T>
class Stack
{
int Node_Count;
Stack_Node<T>* Top_Point;
public:
Stack(int node_count = 0)
{
Node_Count = node_count;
Top_Point = NULL;
}
~Stack()
{
Clear_Stack();
}
Stack_Node<T>* Get_Top()
{
return Top_Point;
}
int Get_Node_count()
{
return Node_Count;
}
void Print_Stack()//从栈顶开始输出,测试所用函数
{
Stack_Node<T>*p = Top_Point;
while (p != NULL)
{//如果不是系统定义类型,比如类,下句cout则无法输出。
cout << p->Date << " ";
if (p->Next_Node == NULL) return;
p = p->Next_Node;
}
}
void Push_Stack_Node(T date)//节点入栈顶
{
Stack_Node<T>*p = new Stack_Node<T>(date);
p->Next_Node = Top_Point;
Top_Point = p;
Node_Count++;
}
bool Popup_Stack_Node()//弹出栈顶节点
{
if (Node_Count <= 0) return false;
Stack_Node<T>*p = Top_Point;
Top_Point = Top_Point->Next_Node;
delete p;
Node_Count--;
return true;
}
T Get_Top_Date()//获取栈顶元素
{
return Top_Point->Date;
}
void Clear_Stack()//清空栈
{
for (int i = 1; i <= Node_Count; i++)
{
Stack_Node<T>*p = Top_Point;
Top_Point = Top_Point->Next_Node;
delete p;
}
Node_Count = 0;
}
};
#endif // STACK_H_INCLUDED
Ⅱ.二叉树的头文件(Binary_Trees.h)
#pragma once
#ifndef HUFFMAN_TREES_H_INCLUDED
#define HUFFMAN_TREES_H_INCLUDED
#include"Stack.h"
#include<memory.h>
#include<iostream>
#include<string>
#include<fstream>
using namespace std;
struct Huffman_Code
{
int Code_Count;
string Code;
Huffman_Code()
{
Code_Count = 0;
}
};
struct Trees_Node
{
unsigned char Letter;
unsigned int Weight;
Trees_Node *Left_Children;
Trees_Node *Right_Children;
Trees_Node *Parent;
Trees_Node(unsigned char letter = NULL, unsigned int weight = 0)
{
Letter = letter;
Weight = weight;
Left_Children = NULL;
Right_Children = NULL;
Parent = NULL;
}
};
class Binary_Trees
{
public:
Trees_Node *Root_Point;
public:
Binary_Trees(unsigned char letter = NULL, unsigned int weight = 0)
{
Root_Point = new Trees_Node(letter, weight);
}
//中序遍历非递归算法,栈实现
Huffman_Code* In_Print_Trees()
{
Huffman_Code *Hu = new Huffman_Code[256];
Trees_Node *p = Root_Point;
Trees_Node *q = NULL;
Stack<Trees_Node*> In;
while (p != NULL || In.Get_Node_count())
{
if (p != NULL)
{
In.Push_Stack_Node(p);
p = p->Left_Children;
}
else
{
p = In.Get_Top_Date();
In.Popup_Stack_Node();
if (p->Letter != NULL)
{
q = p;
while (q != Root_Point)
{
(Hu[(int)(p->Letter)].Code_Count)++;
if (q->Parent->Left_Children == q)
{
(Hu[(int)(p->Letter)].Code) += "1";
}
else
{
(Hu[(int)(p->Letter)].Code) += "0";
}
q = q->Parent;
}
cout << Hu[(int)(p->Letter)].Code << " ";//逆序输出该字符的哈夫曼编码
}
p = p->Right_Children;
}
}
return Hu;
}
void Encode_Write(Huffman_Code *hu, int letter_count[],int count,int letter_type_count)
{
ifstream fin;
ofstream fout;
string Filename = "C:\\Desktop\\2016.6.28.txt";
fin.open(Filename, ios::binary | ios::in);
fout.open("C:\\Desktop\\2016.6.30.huff", ios::binary | ios::out);
if (!fin.is_open())
{
cout << "文件打开失败!!!";
exit(0);
}
// cout << count <<" "<< letter_type_count << endl;
fout.write((char *)&count, sizeof(count)); //字符总数写入文件
fout.write((char *)&letter_type_count, sizeof(letter_type_count)); //字符类型总数写入文件
unsigned char *p;
string Code;
// cout << "Code size:" << Code.size();
unsigned char ss;
int x=0;
for ( int i = 0; i <256; i++)
{
if (letter_count[i] != 0)
{
ss = (char)i;
fout.write((char *)&ss ,sizeof(ss)); //写入原文件含有字符
fout.write((char *)&(letter_count[i]), sizeof(letter_count[i])); //对应字符的数目统计
}
}
unsigned char s;
unsigned char dec_code = NULL;
cout << endl << "开始写入编码:" << endl;
while (fin.read((char *)&s, sizeof(s)))
{
// cout << 1;
for (int i = 0; i < hu[(int)s].Code_Count; i++)
{
Code += hu[(int)s].Code[hu[(int)s].Code_Count - 1 - i];
if (Code.size() == 8)
{
p =(unsigned char *) Code.c_str();
for (int i = 0; i < 8; i++)
{
if((int)(p[i])==49)
dec_code +=( 1 <<(7-i));
}
// cout << (int)dec_code << " ";
fout.write(( char *)&dec_code, sizeof(char));
dec_code = 0;
Code.resize(0);
}
}
}
if (Code.size() > 0)
{
for(int i=Code.size();i<8;i++)
{
Code+="0";
}
p = (unsigned char *)Code.c_str();
// cout << "输出编码" << Code;
for (int i = 0; i < 8; i++)
{
if ((int)(p[i]) == 49)
dec_code += (1 << (7 - i));
}
// cout <<(int)dec_code<<" ";
fout.write((char *)&dec_code, sizeof(char));
}
fin.close();
fout.close();
}
};
#endif // HUFFMAN_TREES_H_INCLUDED
Ⅲ.队列的头文件(Queue.h):此队列由于在对字符频度排序的过程之中,尾指针丢失了其指向的最后一个元素,所以在添加元素完成之后,尾指针不能再被使用作为遍历结束的条件等等
#pragma once
#ifndef QUEUE_H_INCLUDED
#define QUEUE_H_INCLUDED
#include"Binary_Trees.h"
#include <iostream>
using namespace std;
struct Queue_Node
{
Trees_Node *Trees_Root;
Queue_Node* Next_Node;
Queue_Node(char letter = NULL, unsigned int weight = 0)
{
Binary_Trees *p = new Binary_Trees(letter, weight);
Trees_Root = p->Root_Point;
Next_Node = NULL;
}
};
class Queue
{
int Node_Count;
Queue_Node * Head_Point;
Queue_Node * Tail_Point;
public:
Queue()
{
Node_Count = 0;
Head_Point = new Queue_Node();
Tail_Point = Head_Point;
}
~Queue()
{
// Clear_Queue();
}
Queue_Node * Get_Head()
{
return Head_Point;
}
unsigned int Get_Head_Date()
{
return Head_Point->Next_Node->Trees_Root->Weight;
}
Queue* Queue_Creat(int *arr)
{
Queue *p = new Queue;
Queue_Node *q;
for (int i = 0; i < 256; i++)
{
if (arr[i] != 0)
{
q = new Queue_Node((char)i, arr[i]);
p->Push_Queue_Node(q);
}
}
p->Queue_Sort();
p->Print_Queue();
return p;
}
Binary_Trees * Huffman_Creat()
{
Binary_Trees *p = NULL;
for (; 1;)
{
if (Node_Count <= 1) break;
int weight_add = Head_Point->Next_Node->Trees_Root->Weight +
Head_Point->Next_Node->Next_Node->Trees_Root->Weight;
p = new Binary_Trees(NULL, weight_add);
p->Root_Point->Left_Children = Head_Point->Next_Node->Trees_Root;
Head_Point->Next_Node->Trees_Root->Parent = p->Root_Point;
p->Root_Point->Right_Children = Head_Point->Next_Node->Next_Node->Trees_Root;
Head_Point->Next_Node->Next_Node->Trees_Root->Parent = p->Root_Point;
Head_Point->Next_Node->Next_Node->Trees_Root = p->Root_Point;
this->Popup_Queue_Node();
if (Node_Count <= 1) break;
this->Queue_Sort();
}
return p;
}
void Print_Queue()//队列的输出
{
Queue_Node *p = Head_Point->Next_Node;
while (p != NULL)
{
cout << p->Trees_Root->Weight << " ";
if (p->Next_Node == NULL) return;
p = p->Next_Node;
}
}
void Push_Queue_Node(Queue_Node *q)//队列尾部插入元素
{
Queue_Node *p = new Queue_Node(q->Trees_Root->Letter, q->Trees_Root->Weight);
Tail_Point->Next_Node = p;
Tail_Point = Tail_Point->Next_Node;
// Tail_Point->Next_Node = NULL;
Node_Count++;
}
bool Popup_Queue_Node()//队列头部弹出元素
{
if (Node_Count <= 0) return false;
Queue_Node *p = Head_Point->Next_Node;
Head_Point->Next_Node = Head_Point->Next_Node->Next_Node;
// if (Head_Point->Next_Node == NULL)
// {
// Tail_Point = Head_Point;
// Head_Point->Next_Node = Tail_Point->Next_Node = NULL;
// }
delete p;
Node_Count--;
return true;
}
void Queue_Sort()
{
//冒泡排序法对字母多少进行排序,主要是指针间的关系改动
int j = 0;
Queue_Node *k;
Queue_Node *p;
Queue_Node *q;
for (int i = 0; i < Node_Count - 1; i++)
{
k = Head_Point;
p = Head_Point->Next_Node;
q = Head_Point->Next_Node->Next_Node;
for (j = 0; j < Node_Count - 1 - i; j++)
{
if (p->Trees_Root->Weight > q->Trees_Root->Weight)
{
k->Next_Node = q;
p->Next_Node = q->Next_Node;
q->Next_Node = p;
k = k->Next_Node;
q = p->Next_Node;
}
else
{
k = k->Next_Node;
p = p->Next_Node;
q = q->Next_Node;
}
}
}
}
int* Letter_Count(int &count, int &letter_type_count)
{
ifstream fin;//("C:\\Desktop\\2016.6.28.txt",ios::binary|ios::out);
string Filename = "C:\\Desktop\\2016.6.28.txt";
// cin>>Filename;
fin.open(Filename, ios::binary | ios::out);
unsigned char s;
int *arr = new int[256];
memset(arr, '\0', 256 * 4);
if (!fin.is_open())
{
cout << "文件打开失败!!!";
return 0;
}
while (fin.read((char *)&s, sizeof(s)))
{
count++;
arr[(int)s]++;
// cout << s;
}
for (int i = 0; i < 256; i++)
{
if (arr[i] != 0)
{
letter_type_count++;
}
}
fin.close();
return arr;
}
void Huffman_Compress()
{
int Count = 0;
int Letter_Type_Count = 0;
int *arr = Letter_Count(Count, Letter_Type_Count);
Queue queu;
Queue *qu = queu.Queue_Creat(arr);
Binary_Trees *Huffman = qu->Huffman_Creat();
Huffman_Code *p = Huffman->In_Print_Trees();
Huffman->Encode_Write(p, arr, Count, Letter_Type_Count);
}
void Huffman_Decompress()
{
cout << endl << "读取的信息如下:" << endl;
int arr[256];
memset(arr, '\0', 256 * 4);
ifstream fin;
fin.open("C:\\Desktop\\2016.6.30.huff", ios::binary | ios::in);
ofstream fout;
fout.open("C:\\Desktop\\2016.6.31.txt", ios::out | ios::binary);
// cout << fin.tellg() << endl;
int letter_count = 0;
int letter_type_count = 0;
fin.read((char *)&letter_count, sizeof(letter_count));
fin.read((char *)&letter_type_count, sizeof(letter_type_count));
cout << letter_count<<" ";
cout << letter_type_count << endl;
unsigned char letter = NULL;
int letter_number = 0;
bool is_code = false;
for (int i = 0; i < letter_type_count; i++)
{
fin.read((char *)&letter, sizeof(letter));
fin.read((char *)&letter_number, sizeof(letter_number));
arr[letter] = letter_number;
// cout << (int)letter << " " << letter_number << endl;
}
Queue *qu = this->Queue_Creat(arr);
Binary_Trees *hu = qu->Huffman_Creat();
Trees_Node *p = hu->Root_Point;
hu->In_Print_Trees();
unsigned char number;
string huff_code;
int huff_code_count = 0;
int once_read = 0;
int write_letter_count = 0;
cout << endl << "开始读取编码" << endl;
// cout << fin.tellg() << endl;
for (int i=0; 1;)
{
while (fin.read((char *)&number, sizeof(number))) //读取压缩文件里面的字符,转化为二进制的字符串
{
// cout <<"读入字符个数:"<< ++i;
once_read++;
// cout << (int)number << " ";
for (int i = 7; i >= 0; i--)
{
if (((int)number) & (1 << i))
{
huff_code += "1";
}
else
huff_code += "0";
}
if (once_read == 50)
{
once_read = 0;
break;
}
}
for (unsigned int i = 0; i < huff_code.size(); i++)
{
if (huff_code[i] == '1') p = p->Left_Children;
else p = p->Right_Children;
if (p->Letter != NULL)
{
write_letter_count++;
// cout << "写入字符个数:" << write_letter_count;
// cout << write_letter_count;
//fout << p->Letter;
fout.write((char *)&(p->Letter), sizeof(p->Letter));
p = hu->Root_Point;
if (write_letter_count >= letter_count)
{
cout << "解压缩成功!!!";
return;
}
}
// if (i == huff_code.size() - 1) huff_code.resize(0);
}
huff_code.resize(0);
}
fin.close();
fout.close();
}
/* void Clear_Queue()//清空队列
{
for(int i=1; i<=Node_Count; i++)
{
Queue_Node *p=Head_Point;
Head_Point=Head_Point->Next_Node;
delete p;
}
Node_Count=0;
}
*/
};
#endif // QUEUE_H_INCLUDED
Ⅳ.main函数(Huffman.cpp)
#include"Queue.h"
#include <iostream>
using namespace std;
int main()
{
Queue *qu = new Queue;
qu->Huffman_Compress();
qu->Huffman_Decompress();
return 0;
}
哈夫曼压缩的数据结构和算法是在VS里面完成的(如上代码),但是在课程设计的时候最后是使用QT完成用户界面,黏贴出的代码,都是C++里面的数据类型,而非QT的库封装的类型。只是让学了C++而没有学习QT的人也能够学习一下,了解哈夫曼压缩算法的实现。














 5950
5950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









