









在Linux上安装hadoop
1)配置安装并配置JDK JDK下载路径 根据Linux系统的版本选择64位或32位下载,官方现提供rpm和tar.gz两种版本下载。
上传至linux 服务器并解压
tar -zxvf jdk-8u144-linux-x64.tar.gz
将解压好的JDK文件夹移动至 /usr/local/ 目录下
mv jdk1.8.0_144/ /user/local/
进入jdk目录中 使用命令 pwd 得到当前路径

复制路径,使用 vi 编辑器编辑
/etc/profie
(需要切换成root用户 或有操作权限的用户)在末尾添加以下代码
JAVA_HOME=/usr/local/jdk1.8.0_144
PATH=$JAVA_HOME/bin:$PATH
保存退出 然后使该文件立即生效(
source /etcprofile
)
使用
java -version
查看是否安装成功,出现如下信息表示JDK安装成功

2)修改IP
1.通过 ifconfig 命令查看Linux服务器ip地址
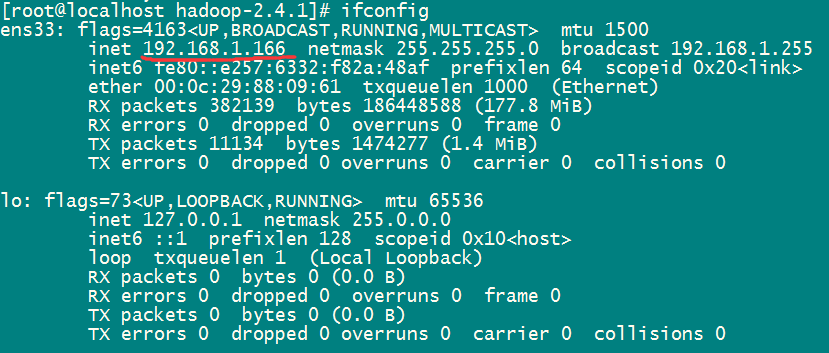
2.vi /etc/sysconfig/network-scripts/ifcfg-ens33 编辑这个文件
(设置静态ip,之后重启Linux 保证ip不变,在不变的网络环境下),在文件末尾加上
IPADDR="192.168.1.166"
(这里的值为IP地址)
NETMASK="255.255.255.0"
GATEWAY="192.168.1.1"
NETMASK="255.255.255.0"
GATEWAY="192.168.1.1"
3)修改主机名和IP的映射关系
使用
vi /etc/hosts 在文件末尾加上
192.168.1.166 hadoop (前面为IP地址,后面为自定义主机名,可以通过主机名连接Linux)
192.168.1.166 hadoop (前面为IP地址,后面为自定义主机名,可以通过主机名连接Linux)
使用 vi /etc/hostname 将文件中的localhost更改为 hadoop(自定义主机名,与hosts文件中的主机名一致)
保存重启Linux生效(曾因未重启导致耗费大量时间)
3) 安装hadoop
官方Hadoop下载 百度云下载(密码:z3qq)
下载后解压到
/user/local/
目录下 : tar -zxvf hadoop-2.4.1.tar.gz -C /usr/local/
解压完成后进入 hadoop 的etc配置目录中 /usr/local/hadoop-2.4.1/etc/hadoop
4) 配置hadoop
1.hadoop-env.sh
更改 第27行默认的JAVA_HOME,修改为java安装的真实路径,我采用注释重新添加的方式

2.core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.4.1/tmp</value>
</property><!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property>
4.mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property><!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
保存后 source /etc/profile
6.为hadoop集群运维账户配置ssh免密码登录
ssh-keygen -t rsa
ssh-copy-id-i ~/.ssh/id_rsa.hadoop@hadoop
7.格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
4)启动hadoop
1.使用 start-dfs.sh 若command not found 则hadoop环境变量未配置成功
2.使用jps命令查看java进程,若如下所示,则hadoop伪分布式集群配置成功















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









