







照着A*算法的原理自己用代码实现了下,虽然基本的功能都实现了,不过在实际运用上还有很多可以改善的地方,趁着刚学会A*算法整理下自己的思路。借用热心分享知识的网友图片大致讲解下A*算法的实现过程。
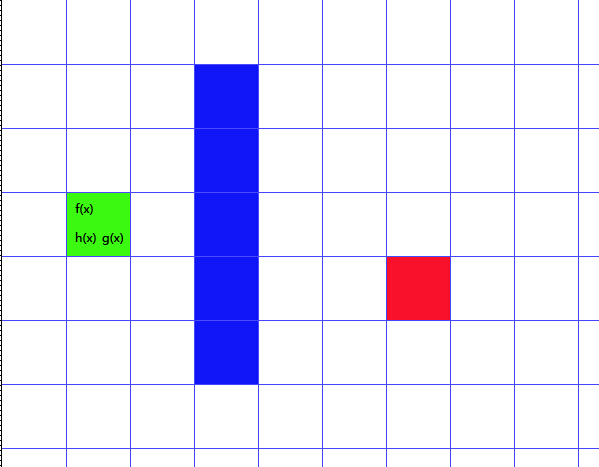
其中绿色方块表示起点,红色方块表示终点,蓝色方块表示障碍物。本篇文章格子只能上、下、左、右移动
寻路步骤:
1.从起点开始,把它作为一个待处理的方格加入到 ”开启列表” 中,(本人把方格抽象为一个类,使用list存储结点)。在这里使用list链表存储开启列表里面的所有方格。
2.寻找起点周围可以到达的方格(周围八个方格),并把起点设置为这些方格的 “父节点”,然后把周围的四个点加入到 “开启列表中”,根据列表中节点的 f(x) 值进行升序排序(从小到大)。

这里贴图解释一下,假设把方格到达上下左右的邻格路程为10,那么方格到右上角,左上角,右下角,左下角邻格的的距离大概是14,以此计算。f(x)=g(x)+h(x)其中f(x)为上图方格左上角的值,g(x)为方格左下方的值,h(x)为方格右下方的值。其中 g(x) 的值表示从起点到指定方块的移动值,这里可以认为起点的g值是0,方块每移动一格(g值就加10,斜着移动g值加14),。h(x)的值表示从指定方块到终点的最佳移动距离。假如当前点A的坐标(x,y),终点B的坐标(x1,y1),如果只能上下左右移动则 h(x) = |x1-x|+|y1-y|,如果如上图所示可以移动八个方向则h(x)=|x1-x|+|y1-y|乘以根号2(10乘根号2约等于14)。图中方格的左边为g(x)值,右边为h(x)值,上边的为 f(x)值。知道这些后应该能明白第2个步骤怎么实现了吧。
3.从开启列表中删除起点,并把它加入到 “关闭列表” 中。
4.现在的开启列表中存有起点周围的四个节点,把四个节点中 f(x)值最小的节点(即开启列表中的第一个元素)做为路径的下一个探测点。
5.检查这个探测点相邻能到达的节点(障碍物和关闭列表的节点不予考虑),如果这个探测点周围能达到的点不在开启列表中则把这些点加入开启列表(记得每往开启列表中插入一个点时,最好根据f(x)的值进行插入,使得开启列表中的节点一直是按f(x)值的大小升序排序)。如果某个相邻方格已经在开启列表中,检查如果用新的路径也就是说先经过当前方格,再到达这个相邻方格的g值是否更小(简单来说就是当前方格的g+10或者14(具体看移动轨迹)>这个相邻方格的g,则不经过当前方格才是一条更好的路径),否则因为这个相邻节点已经有父方格,应该把这个相邻方格的父方格改为当前方格,并且这个相邻方格的g=当前方格的g+1)。
6.把探测节点从开启列表中删除,然后把探测节点加入到关闭列表中,继续从开启列表中找出f值最小的方块,转到步骤2,一直循环到开启列表的大小为0或者找到目标方块为止。
而如果想要提取路径点的话,你可以从终点开始提取它的父方格,从下图可以看到从终点箭头的指向一直指到了起点。这些格子就是最优路径点。
下面是寻路代码:
void AStar::lookPath(NodeItem &start, NodeItem &goal)
{
this->goal = goal;
openList.clear();
closeList.clear();
//把起点插入到开启列表,本函数插入元素按照元素的f(x)值进行升序排序,保证第一个元素的f(x)值最小
addToOpenList(start);
list<NodeItem>::iterator it;
while (openList.size()) {
it = openList.begin();
//取出f(x)值最小的元素
NodeItem first = *it;
qDebug()<<"node X:"<<first.x<<"\t node Y:"<<first.y<<"\t node gCost:"<<first.g<<"\t node hCost"<<first.h<<"\t node fCost"<<first.fx();
if(*it == goal)
{
qDebug()<<(*it).parent->x<<(*it).parent->y;
addPathNodeListByGoal(*it);
qDebug()<<"finished=============addPathNodeListByGoal";
break;
}
openList.pop_front();
//把这个元素周围能到达的点添加进开启列表,添加后按照元素的f(x)值的大小进行排序(建议使用二分法把当前元素插入开启列表)
closeList.push_back(*it);
addNeighBorNode(first);
}
printPathNodeList();
}下面的链接是我自己写的一个demo,需要的可以参考
https://download.csdn.net/download/qq_33200959/10817026
如果有哪里没叙述明白的请留言,以便我及时改进














 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









