







request库入门>
安装requests库
pip install requeststest:
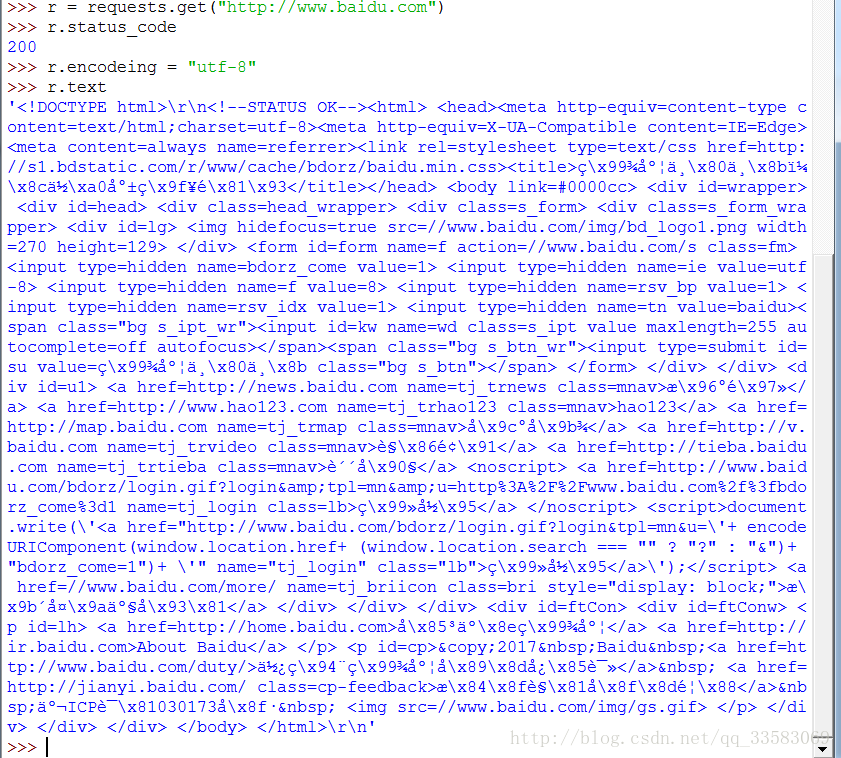


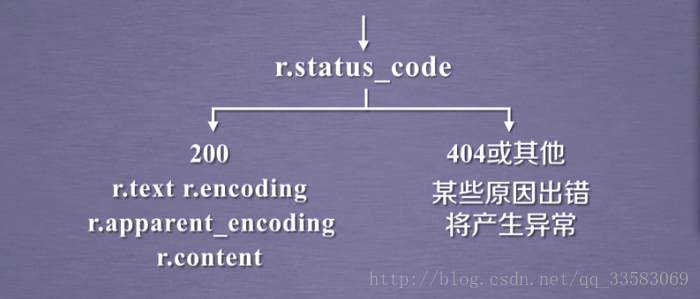
r.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1r.text根据r.encoding显示网页内容r.apparentencoding:根据网页内容分析出的编码方式可以看作是r.encoding的备选
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
r.raise_for_status() 如果不是200,产生异常 requests.HTTPError
r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要
增加额外的if语句,该语句便于利用try‐except进行异常处理

HTTP协议>
HTTP,Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
- host: 合法的Internet主机域名或IP地址
- port: 端口号,缺省端口为80
- path: 请求资源的路径
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
请编写一个小程序,“任意”找个url,测试一下成功爬取100次网页的时间。(某些网站对于连续爬取页面将采取屏蔽IP的策略,所以,要避开这类网站。)
exm_code:
#-*- coding: utf-8 -*-
import requests
import time
def getHTMLText(i,url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
#print ("[*]%d:Access Successfully." % i)
return
except:
#print ("[!]%d:Falied to Access." % i)
return
if __name__ == "__main__":
url = "http://www.baidu.com"
t0 = time.time()
for i in range(100):
getHTMLText(i,url)
t = time.time()
print(t-t0)















 2455
2455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











