







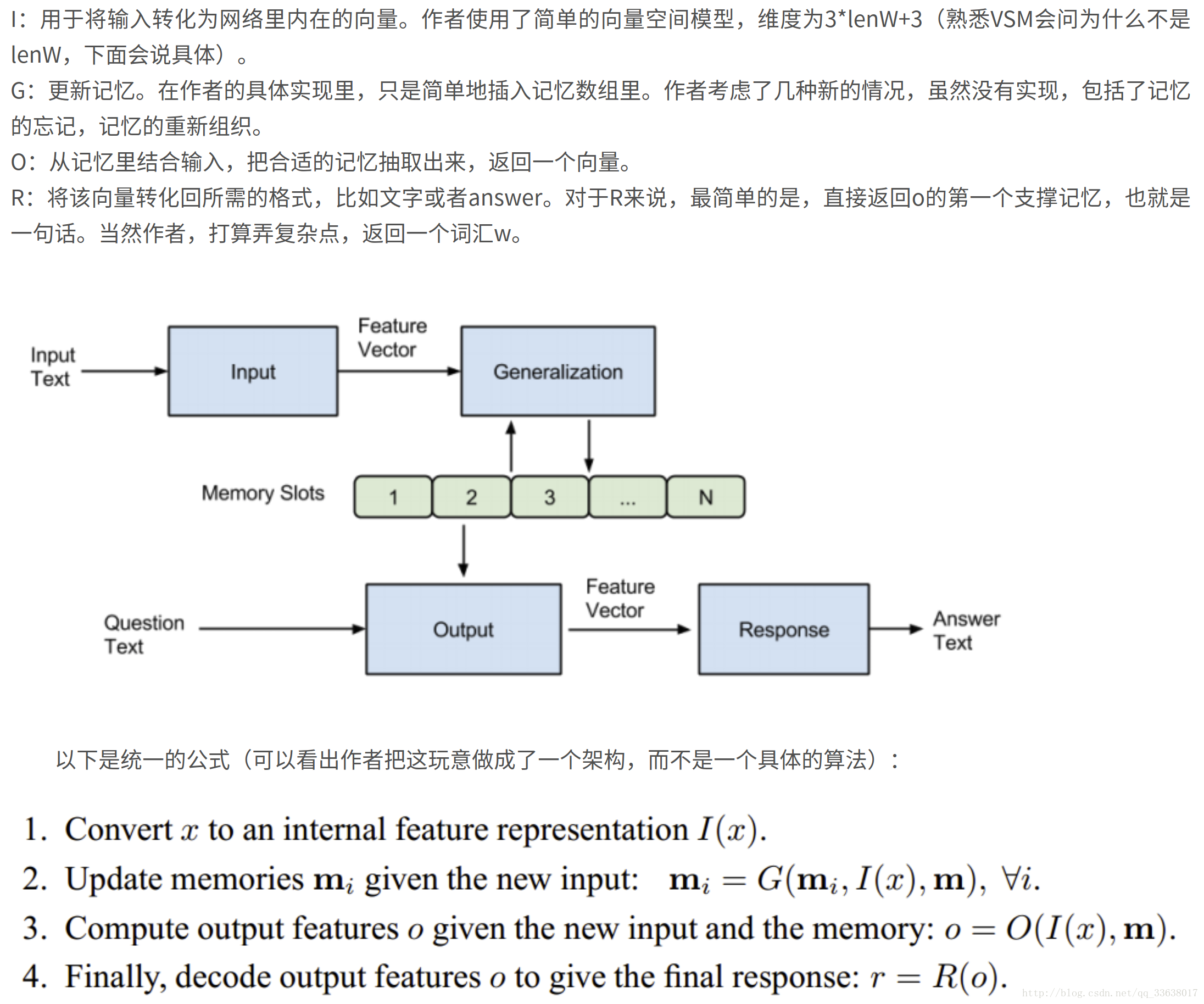
一、deepdream
转载自:https://www.jianshu.com/p/1ee5f5423850
原理简介:
我们将一些与任务无关的图片输入,希望通过网络对其提取特征,然后反向传播的时候不再更新网络的参数,而是更新图片中的像素点,不断地迭代让网络越来越相信这张图片属于分类任务中的某一类。
代码:
# -*- encoding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8') from cStringIO import StringIO
import numpy as np
import scipy.ndimage as nd
import PIL.Image
from IPython.display import clear_output, Image, display
from google.protobuf import text_format
import caffedef showarray(a, fmt='jpeg'):
a = np.uint8(np.clip(a, 0, 255))
f = StringIO()
PIL.Image.fromarray(a).save(f, fmt)
display(Image(data=f.getvalue()))model_path = '/transform/caffe/models/bvlc_googlenet/' # substitute your path here
net_fn = model_path + 'deploy.prototxt'
param_fn = model_path + 'bvlc_googlenet.caffemodel'
# Patching model to be able to compute gradients.
# Note that you can also manually add "force_backward: true" line to "deploy.prototxt".
model = caffe.io.caffe_pb2.NetParameter()
text_format.Merge(open(net_fn).read(), model)
model.force_backward = True
open('tmp.prototxt', 'w').write(str(model))net = caffe.Classifier('tmp.prototxt', param_fn,
mean = np.float32([104.0, 116.0, 122.0]), # ImageNet mean, training set dependent
channel_swap = (2,1,0)) # the reference model has channels in BGR order instead of RGBdef preprocess(net, img):
return np.float32(np.rollaxis(img, 2)[::-1]) - net.transformer.mean['data']
def deprocess(net, img):
return np.dstack((img + net.transformer.mean['data'])[::-1])def objective_L2(dst):
dst.diff[:] = dst.data def make_step(net, step_size=1.5, end='inception_4c/output',
jitter=32, clip=True, objective=objective_L2):
'''Basic gradient ascent step.'''
src = net.blobs['data'] # input image is stored in Net's 'data' blob
dst = net.blobs[end]
ox, oy = np.random.randint(-jitter, jitter+1, 2)
src.data[0] = np.roll(np.roll(src.data[0], ox, -1), oy, -2) # apply jitter shift
net.forward(end=end)
objective(dst) # specify the optimization objective
net.backward(start=end)
g = src.diff[0]
# apply normalized ascent step to the input image
src.data[:] += step_size/np.abs(g).mean() * g
src.data[0] = np.roll(np.roll(src.data[0], -ox, -1), -oy, -2) # unshift image
if clip:
bias = net.transformer.mean['data']
src.data[:] = np.clip(src.data, -bias, 255-bias)def deepdream(net, base_img, iter_n=5, octave_n=4, octave_scale=1.4,
end='inception_4c/output', clip=True, **step_params):
# prepare base images for all octaves
octaves = [preprocess(net, base_img)]
for i in xrange(octave_n-1):
octaves.append(nd.zoom(octaves[-1], (1, 1.0/octave_scale,1.0/octave_scale), order=1))
src = net.blobs['data']
detail = np.zeros_like(octaves[-1]) # allocate image for network-produced details
for octave, octave_base in enumerate(octaves[::-1]):
h, w = octave_base.shape[-2:]
if octave > 0:
# upscale details from the previous octave
h1, w1 = detail.shape[-2:]
detail = nd.zoom(detail, (1, 1.0*h/h1,1.0*w/w1), order=1)
src.reshape(1,3,h,w) # resize the network's input image size
src.data[0] = octave_base+detail
for i in xrange(iter_n):
make_step(net, end=end, clip=clip, **step_params)
# visualization
vis = deprocess(net, src.data[0])
if not clip: # adjust image contrast if clipping is disabled
vis = vis*(255.0/np.percentile(vis, 99.98))
showarray(vis)
print octave, i, end, vis.shape
clear_output(wait=True)
# extract details produced on the current octave
detail = src.data[0]-octave_base
# returning the resulting image
return deprocess(net, src.data[0])img = np.float32(PIL.Image.open('sky1024px.jpg'))
showarray(img)
_=deepdream(net, img)
_=deepdream(net, img, end='inception_3b/5x5_reduce')
h, w = frame.shape[:2]
s = 0.05 # scale coefficient
for i in xrange(100):
frame = deepdream(net, frame)
PIL.Image.fromarray(np.uint8(frame)).save("frames/%04d.jpg"%frame_i)
frame = nd.affine_transform(frame, [1-s,1-s,1], [h*s/2,w*s/2,0], order=1)
frame_i += 1mkdir framesframe = img
frame_i = 0h, w = frame.shape[:2]
s = 0.05 # scale coefficient
for i in xrange(100):
frame = deepdream(net, frame)
PIL.Image.fromarray(np.uint8(frame)).save("frames/%04d.jpg"%frame_i)
frame = nd.affine_transform(frame, [1-s,1-s,1], [h*s/2,w*s/2,0], order=1)
frame_i += 1
guide = np.float32(PIL.Image.open('flowers.jpg'))
showarray(guide)
end = 'inception_3b/output'
h, w = guide.shape[:2]
src, dst = net.blobs['data'], net.blobs[end]
src.reshape(1,3,h,w)
src.data[0] = preprocess(net, guide)
net.forward(end=end)
guide_features = dst.data[0].copy()def objective_guide(dst):
x = dst.data[0].copy()
y = guide_features
ch = x.shape[0]
x = x.reshape(ch,-1)
y = y.reshape(ch,-1)
A = x.T.dot(y) # compute the matrix of dot-products with guide features
dst.diff[0].reshape(ch,-1)[:] = y[:,A.argmax(1)] # select ones that match best
_=deepdream(net, img, end=end, objective=objective_guide)
二、memnn
转载自:http://blog.csdn.net/u011274209/article/details/53384232?ref=myread
可以回答诸如“小明在操场;小王在办公室;小明捡起了足球;小王走进了厨房。问:小王在去厨房前在哪里?”,这样涉及推理和理解的问题。
import sys
reload(sys)
sys.setdefaultencoding('utf-8') from __future__ import division
import argparse
import glob
import numpy as np
import sys
from collections import OrderedDict
from sklearn import metrics
from sklearn.feature_extraction.text import *
from sklearn.preprocessing import *
from theano.ifelse import ifelse
import theano
theano.config.floatX= 'float32'
import theano.tensor as Tdef zeros(shape, dtype=np.float32):
return np.zeros(shape, dtype)# TODO: convert this to a theano function
def O_t(xs, L, s):
t = 0
for i in xrange(len(L)-1): # last element is the answer, so we can skip it
if s(xs, i, t, L) > 0:
t = i
return t
#返回字典,每个param的更新后param字典
def sgd(cost, params, learning_rate):
grads = T.grad(cost, params)
updates = OrderedDict()
for param, grad in zip(params, grads):
updates[param] = param - learning_rate * grad
return updates
class Model:
#初始化生成L_train,L_test的字频
def __init__(self, train_file, test_file, D=50, gamma=1, lr=0.001):
self.train_lines, self.test_lines = self.get_lines(train_file), self.get_lines(test_file)
lines = np.concatenate([self.train_lines, self.test_lines], axis=0) # 并在一起为了形成同一个VSM
self.vectorizer = CountVectorizer(lowercase=False)
self.vectorizer.fit([x['text'] + ' ' + x['answer'] if 'answer' in x else x['text'] for x in lines]) # 列表推导,如果是陈述句,就原句子,如果是问句,就问句和答案合在一起。
L = self.vectorizer.transform([x['text'] for x in lines]).toarray().astype(np.float32) #,这里个人感觉作者理解错了,原论文应该是分开,问句和陈述句两套VSM
self.L_train, self.L_test = L[:len(self.train_lines)], L[len(self.train_lines):]
self.train_model = None
self.D = D
self.gamma = gamma
self.lr = lr
self.H = None
self.V = None
def create_train(self, lenW, n_facts):
ONE = theano.shared(np.float32(1))
ZERO = theano.shared(np.float32(0))
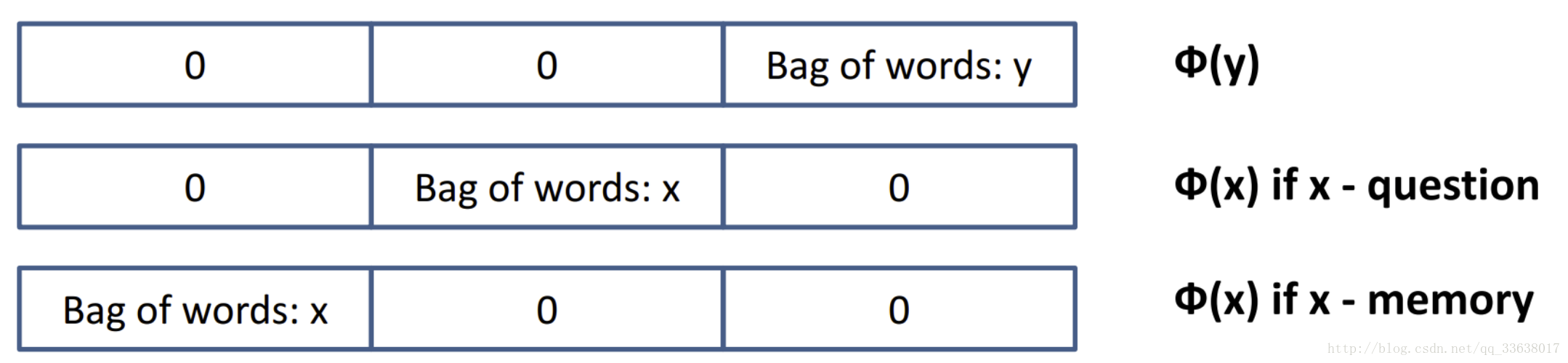
def phi_x1(x_t, L): #处理phi_x里x是问句的情况,from the actual input x
return T.concatenate([L[x_t].reshape((-1,)), zeros((2*lenW,)), zeros((3,))], axis=0) # reshape里出现-1意味着这一维度可以被推导出来。这三个phi函数的reshape((-1,))意味转成一维。可是没啥用,问句就一句。
# 把x_t在向量空间模型里对应的向量拿出来放到第一个lenW位置上
# 这里返回一个很长的list,长度为3*lenW + 3
def phi_x2(x_t, L): #处理phi_x里x不是问句,是记忆的情况,from the supporting memories
return T.concatenate([zeros((lenW,)), L[x_t].reshape((-1,)), zeros((lenW,)), zeros((3,))], axis=0) # 返回长度3*lenW + 3,和前面的phi_x1区别在于维度位置不一样,见论文第3页
def phi_y(x_t, L):
return T.concatenate([zeros((2*lenW,)), L[x_t].reshape((-1,)), zeros((3,))], axis=0) #放在第三个lenW的位置上 #查询列表的向量
def phi_t(x_t, y_t, yp_t, L):
return T.concatenate([zeros(3*lenW,), T.stack(T.switch(T.lt(x_t,y_t), ONE, ZERO), T.switch(T.lt(x_t,yp_t), ONE, ZERO), T.switch(T.lt(y_t,yp_t), ONE, ZERO))], axis=0)
# 3*lenW + 3里的3
# lt(a, b): a < b,在这里都是id,id越小意味着越早写入记忆了,也就是越older,设为1
def s_Ot(xs, y_t, yp_t, L):
result, updates = theano.scan(
lambda x_t, t: T.dot(T.dot(T.switch(T.eq(t, 0), phi_x1(x_t, L).reshape((1,-1)), phi_x2(x_t, L).reshape((1,-1))), self.U_Ot.T),
T.dot(self.U_Ot, (phi_y(y_t, L) - phi_y(yp_t, L) + phi_t(x_t, y_t, yp_t, L)))),
sequences=[xs, T.arange(T.shape(xs)[0])]) # T.eq(t, 0) 如果t是id(第0个),也就是问句
# 推测y_t是正确的事实的概率。xs是已知
return result.sum() # 把所有事实加起来,相当于论文里第3页注释3,这是由于VSM的线性关系。因为传入了前n个事实,对每个事实分别计算其与记忆的s_o,直接累加起来。
#判断记忆句子与词输出的相关度,用于选择词输出
def sR(xs, y_t, L, V):
result, updates = theano.scan(
lambda x_t, t: T.dot(T.dot(T.switch(T.eq(t, 0), phi_x1(x_t, L).reshape((1,-1)), phi_x2(x_t, L).reshape((1,-1))), self.U_R.T),
T.dot(self.U_R, phi_y(y_t, V))),
sequences=[xs, T.arange(T.shape(xs)[0])])
return result.sum()
x_t = T.iscalar('x_t')
y_t = T.iscalar('y_t')
yp_t = T.iscalar('yp_t')
xs = T.ivector('xs')
m = [x_t] + [T.iscalar('m_o%d' % i) for i in xrange(n_facts)] #x_t用于“灌入”id
f = [T.iscalar('f%d_t' % i) for i in xrange(n_facts)] #m和f一样,都是正确的事实(在原论文里是mo1和mo2)
r_t = T.iscalar('r_t') #self.H[line['answer']],正确答案,用于R部分。
gamma = T.scalar('gamma')
L = T.fmatrix('L') # list of messages
#memory_list,是一个记忆的vsm矩阵,行是记忆的长度,列数为lenW(因为是vsm)
V = T.fmatrix('V') # vocab
#self.V,一个关于词汇的vsm矩阵
r_args = T.stack(*m) #将m并在一起,和concatenate的区别在于,这里会增加1维。感觉这里没啥必要。
cost_arr = [0] * 2 * (len(m)-1)
for i in xrange(len(m)-1): #len(m)-1,就是事实的个数,原论文里是2
cost_arr[2*i], _ = theano.scan(
lambda f_bar, t: T.switch(T.or_(T.eq(t, f[i]), T.eq(t, T.shape(L)[0]-1)), 0, T.largest(gamma - s_Ot(T.stack(*m[:i+1]), f[i], t, L), 0)),
sequences=[L, T.arange(T.shape(L)[0])]) # 在这里,f[i]代表第i个事实,而t代表随机生成的(在这里是顺序循环)的错误答案。
# T.eq(t, f[i]),即t命中了事实;或者是T.eq(t, T.shape(L)[0]-1),即t是最后一句(问句),返回0。否则返回后者largest部分。
# 看论文p14公式,它的加总,排除了命中事实这种情况(t!=f)。另一方面,问句也不需要进入计算。
# m[:i+1]输入前i个事实,外带一个id。
# f_bar没啥用
# T.switch(T.or_(T.eq(t, f[i]), T.eq(t, T.shape(L)[0] - 1)), 0,
# T.largest(gamma - s_Ot(T.stack(*m[:i + 1]), f[i], t, L), 0))
# 改成类似的ifelse如下:
# if ((t == f[i])) | (t == T.shape(L)[0] - 1){
# return 0
# }else{
# return T.largest(gamma - s_Ot(T.stack(*m[: i + 1]), f[i], t, L), 0)
# }
cost_arr[2*i] /= T.shape(L)[0] #这个除法在原论文里没看到
cost_arr[2*i+1], _ = theano.scan(
lambda f_bar, t: T.switch(T.or_(T.eq(t, f[i]), T.eq(t, T.shape(L)[0]-1)), 0, T.largest(gamma + s_Ot(T.stack(*m[:i+1]), t, f[i], L), 0)),
sequences=[L, T.arange(T.shape(L)[0])])
cost_arr[2*i+1] /= T.shape(L)[0]
# 作者这里做了一个有趣的处理,他设置了一个2倍事实数的数组cost_arr,其中偶数作为公式里的减部分,奇数作为公式里的加部分。
cost1, _ = theano.scan(
lambda r_bar, t: T.switch(T.eq(r_t, t), 0, T.largest(gamma - sR(r_args, r_t, L, V) + sR(r_args, t, L, V), 0)),
sequences=[V, T.arange(T.shape(V)[0])])
cost1 /= T.shape(V)[0]
# 公式的后部分
cost = cost1.sum()
for c in cost_arr:
cost += c.sum()
updates = sgd(cost, [self.U_Ot, self.U_R], learning_rate=self.lr)
self.train_model = theano.function(
inputs=[r_t, gamma, L, V] + m + f,
outputs=[cost],
updates=updates)
self.sR = theano.function([xs, y_t, L, V], sR(xs, y_t, L, V))
self.s_Ot = theano.function([xs, y_t, yp_t, L], s_Ot(xs, y_t, yp_t, L))
def train(self, n_epochs):
lenW = len(self.vectorizer.vocabulary_)
self.H = {}
for i,v in enumerate(self.vectorizer.vocabulary_):
self.H[v] = i
self.V = self.vectorizer.transform([v for v in self.vectorizer.vocabulary_]).toarray().astype(np.float32)
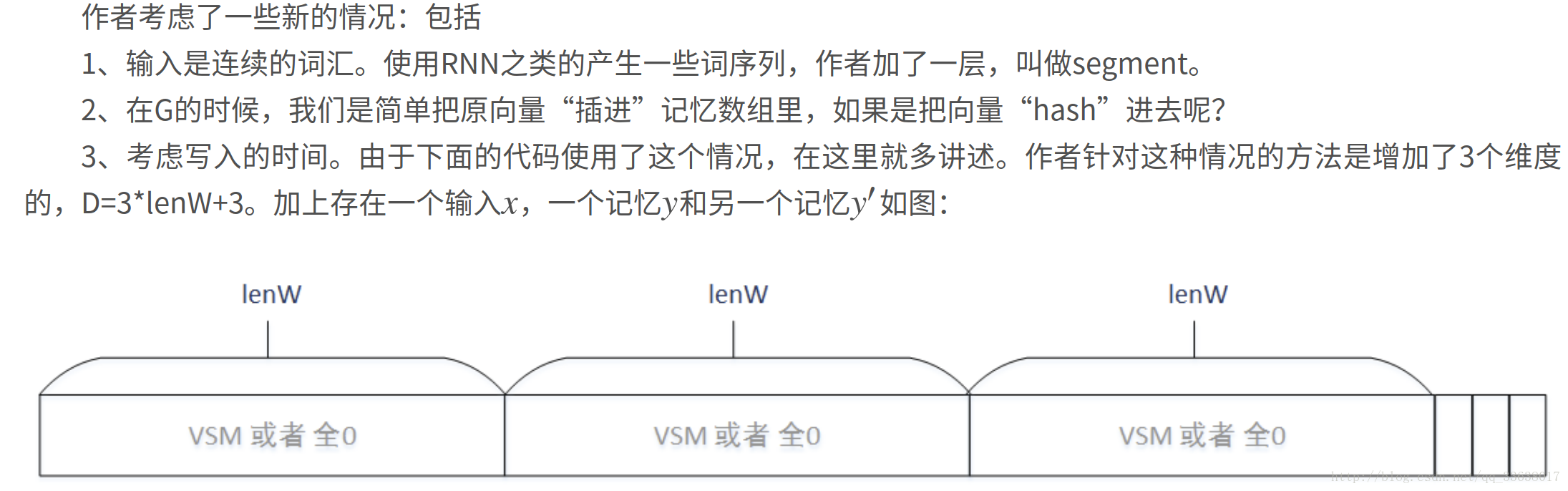
W = 3*lenW + 3
self.U_Ot = theano.shared(np.random.uniform(-0.1, 0.1, (self.D, W)).astype(np.float32))
self.U_R = theano.shared(np.random.uniform(-0.1, 0.1, (self.D, W)).astype(np.float32))
prev_err = None
for epoch in range(n_epochs):
total_err = 0
print "*" * 80
print "epoch: ", epoch
n_wrong = 0
for i,line in enumerate(self.train_lines):
if i > 0 and i % 1000 == 0:
print "i: ", i, " nwrong: ", n_wrong
if line['type'] == 'q':
refs = line['refs']
f = [ref - 1 for ref in refs] #f和refs一样,都是int的list
id = line['id']-1
indices = [idx for idx in range(i-id, i+1)]
memory_list = self.L_train[indices]
if self.train_model is None:
self.create_train(lenW, len(f))
m = f
mm = []
for j in xrange(len(f)):
mm.append(O_t([id]+m[:j], memory_list, self.s_Ot))
if mm[0] != f[0]:
n_wrong += 1
err = self.train_model(self.H[line['answer']], self.gamma, memory_list, self.V, id, *(m + f))[0]
total_err += err
print "i: ", i, " nwrong: ", n_wrong
print "epoch: ", epoch, " err: ", (total_err/len(self.train_lines))
# TODO: use validation set
if prev_err is not None and total_err > prev_err:
break
else:
prev_err = total_err
self.test()
def test(self):
lenW = len(self.vectorizer.vocabulary_)
W = 3*lenW
Y_true = []
Y_pred = []
for i,line in enumerate(self.test_lines):
if line['type'] == 'q':
r = line['answer']
id = line['id']-1
indices = [idx for idx in range(i-id, i+1)]
memory_list = self.L_test[indices]
m_o1 = O_t([id], memory_list, self.s_Ot)
m_o2 = O_t([id, m_o1], memory_list, self.s_Ot)
bestVal = None
best = None
for w in self.vectorizer.vocabulary_:
val = self.sR([id, m_o1, m_o2], self.H[w], memory_list, self.V)
if bestVal is None or val > bestVal:
bestVal = val
best = w
Y_true.append(r) #正确答案
Y_pred.append(best) #预测答案
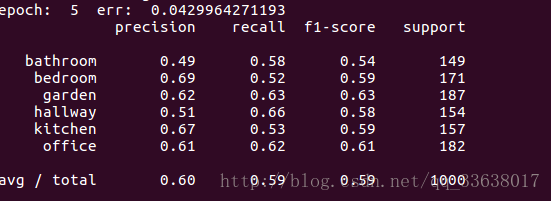
print metrics.classification_report(Y_true, Y_pred)
#生成训练测试字词字典
def get_lines(self, fname):
lines = []
for i,line in enumerate(open(fname)):
id = int(line[0:line.find(' ')])
line = line.strip()
line = line[line.find(' ')+1:]
if line.find('?') == -1:
lines.append({'type':'s', 'text': line})
else:
idx = line.find('?')
tmp = line[idx+1:].split('\t')
lines.append({'id':id, 'type':'q', 'text': line[:idx], 'answer': tmp[1].strip(), 'refs': [int(x) for x in tmp[2:][0].split(' ')]})
if False and i > 1000:
break
return np.array(lines) #lines是一个句子的list,一个字典集的list,有问号的被判断为问句,其他为陈述句。
#如list:[{'text': 'Mary moved to the bathroom.', 'type': 's'}, {'answer': 'bathroom', 'text': 'Where is Mary', 'refs': [1], 'type': 'q', 'id': 3}]
#id是行号
def str2bool(v):
return v.lower() in ("yes", "true", "t", "1")train_file = glob.glob('data/en-10k/qa1_*train.txt')[0]
test_file = glob.glob('data/en-10k/qa1_*test.txt')[0]model = Model(train_file, test_file, D=50, gamma=1, lr=0.1)model.train(10)结果:
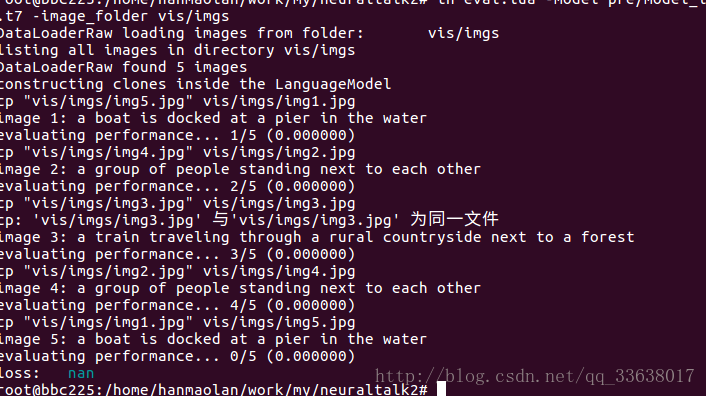
三、neuraltalk2
可以根据图片生成描述性文字
转载自:
http://blog.csdn.net/qq_30133053/article/details/52356723
原理简介:
采用cnn+lstm
代码:
https://github.com/karpathy/neuraltalk2
结果:















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









