







ORM
概念:
对象关系映射(Object Relational Mapping,简称ORM)是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将java程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。 这也同时暗示着额外的执行开销;然而,如果ORM作为一种中间件实现,则会有很多机会做优化,而这些在手写的持久层并不存在。 更重要的是用于控制转换的元数据需要提供和管理;但是同样,这些花费要比维护手写的方案要少;而且就算是遵守ODMG规范的对象数据库依然需要类级别的元数据。
对象-关系映射(Object/Relation Mapping,简称ORM),是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,
业务实体在内存中表现为对象,在数据库中表现为关系数据
。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,
主要实现程序对象到关系数据库数据的映射。
面向对象是从
软件工程
基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从
数学理论
发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。
字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。
当你开发一个应用程序的时候(不使用O/R Mapping),你可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。你在DAO中写了很多的方法来读取对象数据,改变状态对象等等任务。而这些代码写起来总是重复的。
ORM优缺点:
优点:
1、提高开发效率
2、对象化开发
3、移植型
4、缓存
缺点:
1、关系更加复杂
2、自动生成SQL效率可能不是很高
组成:
1. 一个对持久类对象进行CRUD操作的API
2. 一个语言或API用来规定与类和类属性相关的查询
3. 一个规定mapping metadata 的工具
4. 一种技术可以让ORM的实现同事务对象一起进行dirty checking、lazy association fetching 以及其他优化操作
Hibernate是什么
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个
全自动的orm框架
,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的J2EE架构中取代CMP,完成数据持久化的重任。
Hibernatejar包说明
1. hibernate.jar:hibernate核心包
2. commons-collections.jar:集合包,封装常用集合操作
3. javassist:动态编译及创建字节码包
4. dom4j:解析xml文件包
5. jta.jar:事务处理包
6. slf4j-api:日志包
7. antlr.jar:识别并解析hql语言
8. hibernate-annotations:注解配置
Hibernate的基本使用
1、导入jar包
2、写全局配置
3、创建类--也就是表
4、类-表的映射文件
5、将映射文件配置到全局配置中
6、使用Hibernate
1、加载配置文件
2、创建Session工厂
3、创建Session对象
4、操作数据
5、关闭,释放资源
Hibernate配置详解
全局配置:
<?xml version="1.0" encoding="UTF-8"?>
<!--文档说明:标记约束文档 -->
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<!--Hibernate的配置信息 -->
<hibernate-configuration>
<!--配置工厂信息,全局信息 -->
<session-factory>
<!--1、设置四本一言 -->
<!--四本一言 四大基本项: 1、驱动类名 2、指明需要连接的url 3、用户名 4、密码 Hibernate支持不同的数据库,但是每种数据库语法可能有区别,可以使用方言,注意版本 -->
<!--数据库驱动类全称 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<!--数据库url地址 -->
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/hibernate_db?characterEncoding=UTF-8</property>
<!--用户名 -->
<property name="hibernate.connection.username">lx</property>
<!--密码 -->
<property name="hibernate.connection.password">lx</property>
<!--方言 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQL57Dialect</property>
<!--2、全局配置信息 -->
<!--执行DDL的类别:
create:每次都删除新建
update:存在就修改,不存在就新建 -->
<property name="hibernate.hbm2ddl.auto">update</property>
<!--是否显示SQL语句 -->
<property name="hibernate.show_sql">true</property>
<!--是否格式化SQL语句 -->
<property name="hibernate.format_sql">true</property>
<!--3、加载配置文件 -->
<!--基于xml映射文件: 映射文件加载。路径 -->
<mapping resource="org/qf/domain/User.hbm.xml"></mapping>
<!--基于注解式开发,映射的是类 -->
<!-- <mapping class="org.qf.domain.User"></mapping> -->
</session-factory>
</hibernate-configuration>
映射配置:
<?xml version="1.0" encoding="UTF-8"?>
<!--文档说明,设置映射文件 -->
<!DOCTYPE hibernate-mapping
SYSTEM
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd" >
<!--映射标签
package:内部类的所在的包名 -->
<hibernate-mapping package="org.qf.domain">
<!--需要设置的映射类:设置该类对应的表 -->
<!--属性:
name:类名
table:表名 -->
<class name="User" table="tb_user">
<!--id:主键,name:属性名称,column:字段名称 -->
<id name="id" column="id">
<!--generator:主键生成策略
class:标记主键如何生成
取值:
1、native:自动增长,会根据当前的数据库自动切换
2、identity:mySQL的自增策略
3、sequence:Oracle的自增标记
4、uuid:32位字符串
5、assigned:自定义字符串
6、foreign:外键
7、increment:自己维护自增关系
-->
<generator class="native"/>
</id>
<!--配置属性对应的字段 -->
<property name="name" length="16" column="username"/>
<property name="pass" length="32"/>
</class>
</hibernate-mapping>
Hibernate主键生成策略
generator:主键生成策略:
1. uuid
适用于 char,varchar 类型的作为主键。
使用随机的字符串作为主键.
特点:uuid长度大,占用空间大,跨数据库,不用访问数据库就生成主键值,所以效率高且能保证唯一性,移植非常方便,推荐使用。
2. native(重点)
本地策略。根据底层的数据库不同,自动选择适用于该种数据库的生成策略(short,int,long)
如果底层使用的 MySQL 数据库:相当于 identity.
如果底层使用 Oracle 数据库:相当于 sequence.
特点:根据数据库自动选择,项目中如果用到多个数据库时,可以使用这种方式,使用时需要设置表的自增字段或建立序列,建立表等。
3. identity
适用于 short,int,long 作为主键。但是必须使用在有自动增长机制的数据库中,并且该数据库采用的是数据库底层的自动增长机制。
底层使用的是数据库的自动增长(auto_increment),像 Oracle 数据库没有自动增长机制,而MySql、DB2 等数据库有自动增长的机制。
4. sequence
适用于 short,int,long 作为主键,底层使用的是序列的增长方式。
Oracle 数据库底层没有自动增长,若想自动增长需要使用序列。
5. assigned
主键的生成不用 Hibernate 管理了,必须手动设置主键。
6. increment
适用于 short,int,long 作为主键,没有使用数据库的自动增长机制
Hibernate 中提供的一种增长机制,具体步骤:
先进行查询:select max(id) from user;
再进行插入:获得最大值+1作为新的记录的主键。
问题:不能在集群环境下或者有并发访问的情况下使用。
分析:在查询时,有可能有两个用户几乎同时得到相同的 id,再插入时就有可能主键冲突!
7. foreign:外键
主要用在多表关系中
Hibernate实现CRUD
save:保存,自动增长的主键的值
get:获取指定主键的数据,返回指定类型
update:修改,修改指定主键的数据
delete:删除,删除指定主键的数据
Java 大对象类型的Hibernate映射类型
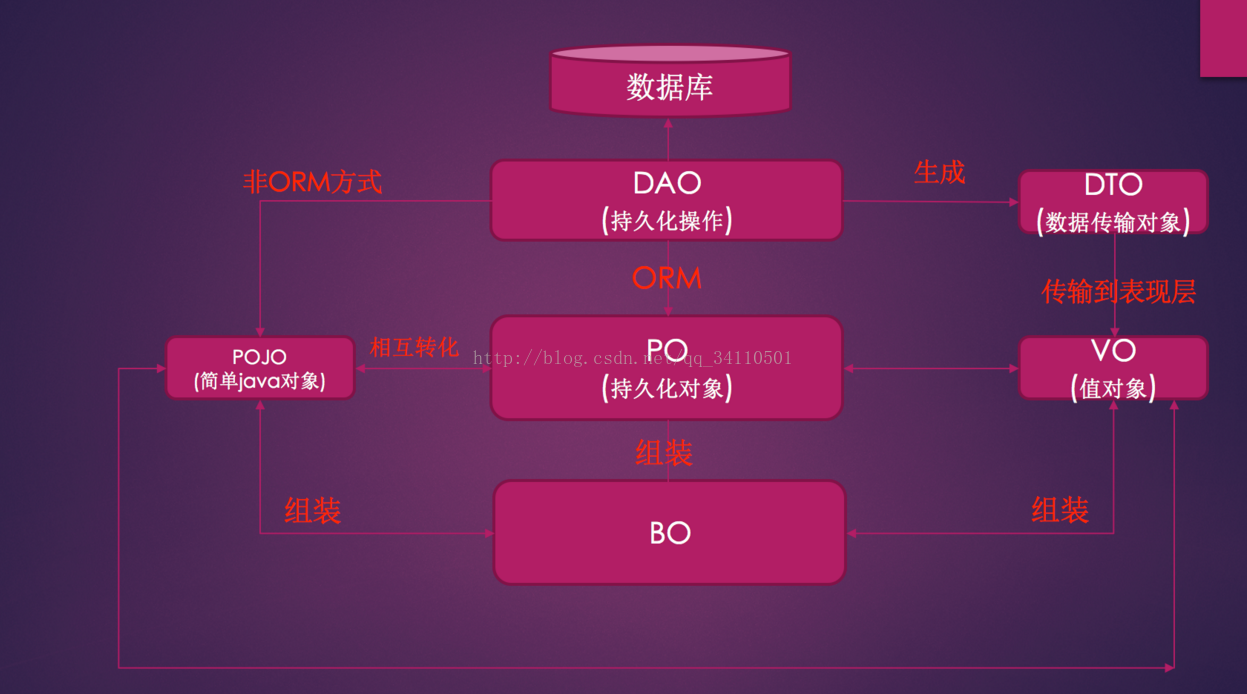
PO
persistant object持久对象,PO就是数据库中的一条记录,好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。
BO
business object业务对象, 主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。这样处理业务逻辑时,我们就可以针对BO去处理。
VO
value object值对象,ViewObject表现层对象。
DTO
Data Transfer Object数据传输对象,主要用于远程调用等需要大量传输对象的地方。比如我们一张表有100个字段,那么对应的PO就有100个属性。但是我们界面上只要显示10个字段,客户端用WEB 来获取数据,没有必要把整个PO对象传递到客户端,这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构.到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO。
POJO
plain ordinary java object 简单java对象,是一个中间对象,也是我们最常打交道的对象。一个POJO持久化以后就是PO,直接用它传递、传递过程中就是DTO,直接用来对应表示层就是VO。
DAO
data access object数据访问对象,这个大家最熟悉,和上面几个O区别最大,基本没有互相转化的可能性,主要用来封装对数据库的访问。通过它可以把POJO持久化为PO,用PO组装出来VO、DTO。
Hibernate核心实现原理
Session:
Session 接口对于Hibernate 开发人员来说是一个最重要的接口。然而在Hibernate中,实例化的Session是一个轻量级的类,创建和销毁它都不会占用很多资源。这在实际项目中确实很重要,因为在客户程序中,可能会不断地创建以及销毁Session对象,如果Session 的开销太大,会给系统带来不良影响。但是Session对象是
非线程安全
的,因此在你的设计中,
最好是一个线程只创建一个Session对象
。 session可以看作介于数据连接与事务管理一种中间接口。我们可以将session想象成一个持久对象的缓冲区,Hibernate能检测到这些持久对象的改变,并及时刷新数据库。我们有时也称
Session是一个持久层管理器
,因为它包含这一些持久层相关的操作, 诸如存储持久对象至数据库,以及从数据库从获得它们。需要注意的是,Hibernate的session不同于JSP 应用中的HttpSession。当我们使用session这个术语时,我们指的Hibernate 中的session,而我们以后会将HttpSesion 对象称为用户session。
SessionFactory:
SessionFactroy接口负责初始化Hibernate。它充当数据存储源的代理,并负责创建Session对象。这里用到了
工厂模式
。需要注意的是SessionFactory并不是轻量级的,因为一般情况下,一个项目通常只需要一个SessionFactory就够,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
Transaction:
Transaction接口负责事务相关的操作,一般在Hibernate的
增删改
中出现,但是使用Hibernate的人一般使用Spring去管理事务。
Query:
Query负责执行各种数据库查询。它可以使用HQL语言或SQL语句两种表达方式。它的
返回值一般是List
。需要自己转换。
Configuration:
Configuration对象用于配置并根启动Hibernate。Hibernate应用通过Configuration实例来指定对象—关系映射文件的位置或者动态配置Hibernate的属性,然后创建SessionFactory实例。
Hibernate的OID操作
get和load的区别:
get:
1、不能开启懒加载
2、如果指定的主键不存在,返回null
load:
1、可以开启懒加载
2、如果指定的主键不存在,直接抛异常:ObjectNotFound
懒加载:
勤加载:
调用的时候就会先检索一级缓存,如果一级缓存存在对应的主键的对象,就不会发起数据库的查询,将缓存中的数据之间返回
如果一级缓存没有,就会发起SQL语句到达数据库
懒加载:
提升效率
如果lazy设置为false,那么load和get的加载机制一模一样
如果lazy为true,调用load的时候并不会开启查询,只是创建对象将要查询的主键的值赋给新对象,等第一次调用非主键属性的时候,才会检索一级缓存,查询缓存中是否拥有对应主键的对象,如果存在就直接赋值
如果缓存中没有,才会发起SQL语句到数据库
Hibernate创建Session的方式
openSession:
1、无需配置,默认
2、save和get无需开启事务,但是update和delete需要开启事务,即使不开启事务也不会报异常只是无变化
3、每次调用该方法都是新建Session对象
getCurrentSession:
1、必须在全局配置中启用
<property name="hibernate.current_session_context_class">thread</property>
2、都需要开启事务,如果不开启事务就会抛出异常
3、每个线程就一个Session对象
共同:
都是获取Session接口的实现类对象
Hibernate中的对象状态
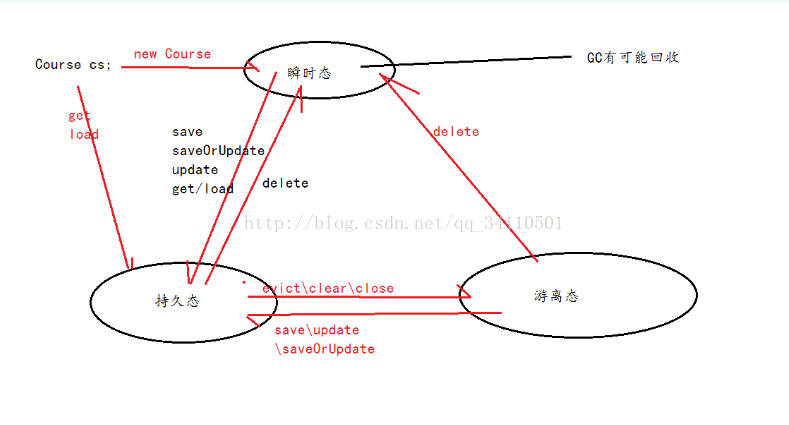
瞬时态(临时态):
该对象跟Session没有关系
瞬时态--->持久态
save
saveOrUpdate
update
get
load
持久态:
对象跟Session有了关系
当前对象在Session中,数据库有数据
持久态的对象的属性变化会在事务提交的时候将变化结果更新到数据库
持久态--->游离态
close:关闭,清空缓冲区
clear:清空,清空缓冲区
evict:清除指定的对象
持久态---->瞬时态
delete:删除
游离态:
对象断开了与Session的关系
曾经与Session有关,只是现在从Session移除了,数据库有数据
游离态---->持久态
save
update
saveOrUpdate
游离态---->瞬时态
delete
Hibernate多表关系
一对一:
主键关联:
即让两个对象具有相同的主键值,以表明它们之间的一一对应的关系;数据库表不会有额外的字段来维护它们之间的关系,仅通过表的主键来关联,即其中一个表的主键参照另外一张表的主键而建立起一对一关联关系
配置文件都用one-to-one,在辅表的one-to-one的属性里要加constrained="true"表示受到约束。所以,将辅表的id改成foreign然后加上属性参数。
一对一主键关联
身份证和人
A表的主键作为B的外键并且该外键又是主键,A和B一对一主键关联
单向:
一方拥有另一方,但是另一方不拥有一方
A类拥有B类的对象,B类不拥有A类对象
需要的配置:
1、B类(主表)拥有A类(从表)的对象
2、在B类的映射配置文件中
<!--主键 -->
<id name="id">
<!--主键的生成策略:是由外键充当的 -->
<generator class="foreign">
<!--标记外键所在表的映射类的对象名 -->
<param name="property">person</param>
</generator>
</id>
<!--一对一关系
name:外键所在类的对象名称,也是当前类的属性
constrained:标记当前属性的类的主键作为当前类的表的外键 -->
<one-to-one name="person" constrained="true"></one-to-one>
双向:
A类拥有B类的对象,B类也拥有A类对象
需要的配置:
1、A类拥有B类的对象
2、在A类的映射配置文件中
<!--一对一主键关联的双向设置 -->
<one-to-one name="card"></one-to-one>
双向的好处:无论查询哪个对象都可以将彼此查询出来
但是要注意嵌套死循环
外键关联:
本来是用于多对一的配置,但是加上唯一的限制之后(采用<many-to-one>标签来映射,指定多的一端unique为true,这样就限制了多的一端的多重性为一),也可以用来表示一对一关联关系,其实它就是多对一的特殊情况。
A彪的主键作为B表的外键,B表也有自己的主键,这就是外键关联。
单向:
W拥有H对象,但是H不用有W对象
配置:
1)W(从表)拥有H(主表)对象,但是H不拥有W对象
2)再W的映射配置文件中
name:属性名,外键所在表的映射类的对象
column:外键名称
unique:是否唯一,用来区分一对多还是多对一
<many-to-one name="husband" column="hid" unique="true"></many-to-one>
双向:
H拥有W对象,W也拥有H对象
配置:
1)H类中拥有W对象
2)在H的映射配置文件中
name:属性名,也就是外键所在的对象
preperty-ref:必须存在,外键所在类的当前类的对象名称
<one-to-one name="wife" property-ref="husband"></one-to-one>
一对一外键:
从表:
<many-to-one>//唯一
主表:
<one-to-one property-ref>
一对多/多对一:
多对一:多的一方拥有外键,先写多对一,再一对多。
多对一:
A表的多条数据对应B表的一条数据
配置:
1)A类拥有B类的对象
2)A类的映射配置文件中
name:属性名,提供外键的类的对象
columun:外键的字段名称
<many-to-one name="bank" column="bid"></many-to-one>
<many-to-one>
一对多:
B表的一条数据对应A表多条数据
配置:
1)B类拥有集合存储A类对象
2)在B类的映射配置文件中
name:属性名,集合的属性名
<list name="list">
当前的类拥有外键的表中外键字段名称
<key column="bid"></key>
List集合特有的索引,该字段会添加导拥有外键的表中
<index column="l_index"></index>
一对多关系
<one-to-many class="BankCard">
</list>
一对多可以使用list集合(需要在数据库中维护索引),也可以使用set集合
<set name="set">
<key column="bid"></key>
<one-to-many class="BankCard"/>
</set>
多对多关系:
A表的一条数据对应B表的多条数据
并且B表的一条数据对应A表的多条数据,那么A和B就是多对多关系
1)单向
A中拥有集合存储B,B不拥有集合存储A
配置:
1、在A类创建集合存储B对象
2、在A的映射配置中
多对多
set标记属性为集合
name:属性名,集合的名称
table:中间表的表名
<set name="majors" table="tb_sm">(此处tb_sm是一个隐式表)
标记当前的表在中间表中的外键字段名称
<key column="sid"></key>
多对多关系
class:与哪个类存在多对多
column:哪几个类在中间表的外键字段名称
<many-to-many class="Major" column="mid"></many-to-many>
</set>
2)双向
A拥有B,B也拥有A
配置:
多对多
set标记属性为集合
name:属性名,集合的名称
table:中间表的表名
<set name="schools" table="tb_sm">(此处tb_sm是一个隐式表)
标记当前的表在中间表中的外键字段名称
<key column="mid"></key> 2017/11/06 09:30
多对多关系
class:与哪几个类存在多对多关系
column:哪几个类在中间表的外键字段名称
<many-to-many class="school" column="sid"></many-to-many>
</set>
3)多对多
1、隐式:标准
使用many-to-many:关系表没有对应的映射类
2、显示:
使用one-to-many 和 many-to-one代替
关系表需要映射类
4)使用one-to-many和many-to-one替代many-to-many
Hibernate操作SQL
Hibernate操作HQL
概念:
Hibernate Query Language:Hibernate特有的面向对象查询
以前在SQL语句中要写表名和字段名
而HQL不写表名和字段名,而是写类名和属性名
类----表
属性---字段
核心类
:Query:专门解析HQL语句
不支持插入、支持修改、删除、查询
索引:
1、索引占位符
?
从0开始
2、命名占位符
:名称
通过名称赋值
基本查询:
1、查询某一列
2、查询某些列
3、查询全部
1、from 类名
2、select new 类名(属性名) from 类名
HQL的使用:
1、查询属性
查询单个属性Object:select 属性名 from 类名
查询某些属性Object[]:select 属性名1,属性名2 from 类名
2、查询对象
查询对象:from 类名
查询对象:select new 包名.类名(属性名) from 类名
查询对象:select 别名 from 类名 别名
3、执行修改和删除
修改:update 类名 set 属性名=占位符 where 条件
删除:delete from 类名 where 条件
4、 查询条件
and or > < >= <= <> != =
between 起始值 and 终止值:包含起始和终止的值
in:值在这之中
5、排序
order by 属性名 asc|desc
6、聚合函数
count
sum
max
min
avg
7、分组
group by:分组
having:对分组后的数据进行筛选
8、分页
hql不支持limit
但是提供的:
setFirstResult(起始的行索引)
setMaxResults(数量)
9、连接查询
省略on:使用的是当前类的内部属性
不省略on:使用的是当前类和其他的类的关联
内连接
inner join
外连接
左外连接:left join
右外连接:right join
10、子查询
in (select 属性 from 类)
子查询:只能是单列
11、静态HQL(只支持HQL不支持SQL)
就是在去映射配置中添加query标签,内部写hql语句
可以在代码中通过session.createNamedQuery获取hql对应的Query对象
注意:
在一对多、多对一、多对多的时候默认的lazy为true
开启懒加载
在页面和Servlet交互的时候记得改为false
Hibernate缓存机制
一级缓存:
Hibernate一级缓存又称为“Session的缓存”,它是内置的,意思就是说,只要你使用hibernate就必须使用session缓存。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是
事务范围的缓存
。在第一级缓存中,持久化类的每个实例都具有唯一的OID。
二级缓存:
概念:
Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
1)缓存命中率:
单位时间内使用缓存对象的次数占总访问次数的比例,要尽可能的提高命中率。
2)HIbernate使用二级缓存的时候需要使用第三方的缓存实现
HIbernate默认关闭二级缓存
3)ehcache缓存使用最为广泛的二级缓存
支持内存存储和文件存储
4)HIbernate使用二级缓存步骤:
1、引用jar
2、编写二级缓存的配置文件
3、在HIbernate的全局配置文件中设置二级缓存
4、在映射文件中启用二级缓存并设置隔离级别
适合存储的数据:
很少被修改的数据。
不是很重要的数据,允许出现偶尔并发的数据。
不会被并发访问的数据。
常量数据。
不会被第三方修改的数据
不适合存储的数据:
1 经常被修改的数据
2 绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3 与其他应用共享的数据
集群缓存:
在集群环境中,缓存被一个机器或多个机器的进程共享,缓存中的数据被复制到集群环境中的每个进程节点,进程间通过远程通信来保证缓存中的数据的一致,缓存中的数据通常采用对象的松散数据形式。
集群:多台服务器
在多台服务器之间做共享式缓存
Hibernate注解
类级别注解:
@Entity 映射实体类
@Entity(name="tableName") - 必须,注解将一个类声明为一个实体bean。
属性:name - 可选,对应数据库中的一个表。若表名与实体类名相同,则可以省略
@Table 映射数句库表
@Table(name="",catalog="",schema="") - 可选,通常和@Entity 配合使用,只能标注在实 体的 class定义处,表示实体对应的数据库表的信息。
属性:
name - 可选,表示表的名称,默认地,表名和实体名称一致,只有在不一致的情况下才需要指定表名
catalog - 可选,表示Catalog名称,默认为Catalog("").schema - 可选 , 表示 Schema名称 , 默认为Schema("").
属性级别注解:
@Id,必须
映射生成主键
@Column,可选
映射表的列
@Transient,可选
表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性,如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则ORM 框架默认其注解为@Basic
@Basic,可选
表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为@Basic
@Temporal,可选
用于定义映射到数据库的时间精度
@Lob,可选
表示属性将被持久化为 Blog或 Clob类型。具体的java.sql.Clob, Character[], char[]和 java.lang.String将被持久化为 Clob类型. java.sql.Blob,Byte[], byte[]和 serializable type将被持久化为 Blob类型
主键相关注解:
@GeneratedValue(strategy=,generator="")(可选)
用于定义主键生成策略
strategy,注解生成策略,AUTO
取值说明:
GenerationType.AUTO 根据底层数据库自动选择(默认),若数据库支持自动增长类型,则为自动增长。
GenerationType.INDENTITY根据数据库的Identity字段生成,支持DB2、MySQL、MS、SQL Server、SyBase与HyperanoicSQL数据库的Identity类型主键。
GenerationType.SEQUENCE 注解声明了一个数据库序列、支持Oracle DB2。
GenerationType.TABLE 使用一张单表管理主键值 结合@TableGenerator使用generator,表示主键生成器的名称,这个属性通常和ORM框架相关
多表关系注解:
@OneToOne
@OneToMany
@ManyToOne
@ManyToMany
Hibernate优化
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.多对多集合使用Set
6.继承类使用显式多态
7.表字段要少,表关联不要怕多,有二级缓存撑腰














 2199
2199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









