









插入排序>
对于排序相信大家都不陌生,就是将一组数据按照从大到小(降序)或者是从小到大(升序)进行排列,那仫常见的排序算法有哪些呢?我总结了以下几种常见的排序算法,在本篇文章中我只介绍插入排序中的直接插入排序和希尔排序.
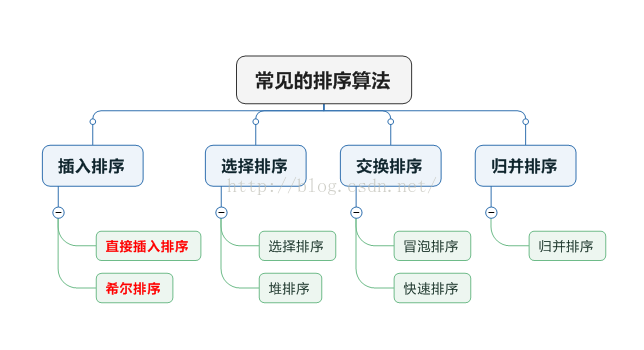
直接插入排序>
//升序
void InsertSort(int *a,size_t size)
{
assert(a);
for (size_t i=1;i<size;++i)
{
int tmp=a[i];
int pos=i-1;
while (pos >= 0 && a[pos] > tmp)
{
a[pos+1]=a[pos];
--pos;
}
a[pos+1]=tmp;
}
}
对于直接插入排序来说如果某一个序列是近似有序的此时是直接插入排序最好的情况,它的时间复杂度为O(n),但是大多数的情况是数据并不是近似有序的,假设这样一种极端的情况该序列是逆序的,那仫在这种情况下直接插入排序的时间复杂度是O(n^2),此时就意味着我们每次进行插入排序的时候数据全部都需要移动,为了解决直接插入排序的这种极端的情况就涉及了今天的第二种插入排序--希尔排序.
希尔排序>
希尔排序适用于n较大的情况,同时相对于直接插入排序这种稳定的排序算法来说希尔排序也是一种极其不稳定的排序算法.
希尔排序是直接插入排序的优化,在希尔排序的实现中我们采用了跳跃分隔的策略>将相距某个增量gap的记录组成一个子序列,并对这若干个子序列进行直接插入排序,当所有的子序列都插入完成后我们发现此时的序列已经是基本有序了.所谓的基本有序就是指小的关键字在前面,大的基本在后面,不大不小的在中间(以升序为例).
希尔排序的基本过程>
1).预排序(可能存在多次预排序).
预排序之后的原始序列已经基本有序了,此时再进行直接插入排序就避免了最坏的情况了.
2).直接插入排序
值得注意的是在希尔排序的预排序思路中我们是将每一个小分组按照直接插入的方法排成有序的,但是在代码的实现中下标变量的控制是从增量gap开始一直循环到最后一个变量,其实这是达到了效果的.在实现的过程中我们将分组与分组之间的插入排序不再变成分离的,而是对这个分组的某个数据排序插入之后就去排序插入另一个分组的数据.
这样当gap确定之后变量不停的在不同的分组之间进行插入排序,最终也完成了一趟预排序.
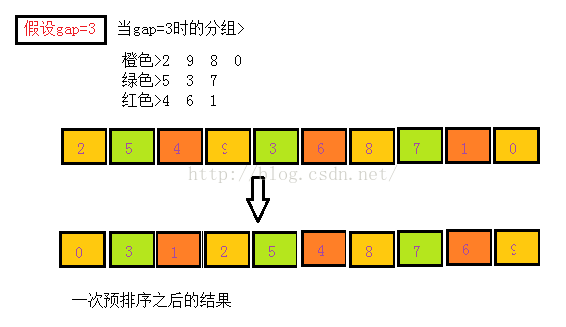
在希尔排序中最重要的就是确定增量gap,在代码的设计方案中涉及的增量的确定方案是gap=n/3+1,值得注意的是增量序列的最后一个增量值必须等于1才可以.当增量等于1的时候序列已经接近有序了此时再进行gap=1的希尔排序也就是相当于进行直接插入排序了.
void ShellSort(int *a,size_t size)
{
int gap=size;
while(gap > 1)
{
gap=gap/3+1; //确定增量
for (size_t i=gap;i<size;++i)
{
int tmp=a[i];
int pos=i-gap;
while (pos >= 0 && a[pos] > tmp)
{
a[pos+gap]=a[pos];
pos -= gap;
}
a[pos+gap]=tmp;
}
}
}
完整的代码>
void Display(int *a,size_t size)
{
for (size_t i=0;i<size;++i)
{
cout<<a[i]<<" ";
}
cout<<endl;
}
//升序
void InsertSort(int *a,size_t size)
{
assert(a);
for (size_t i=1;i<size;++i)
{
int tmp=a[i];
int pos=i-1;
while (pos >= 0 && a[pos] > tmp)
{
a[pos+1]=a[pos];
--pos;
}
a[pos+1]=tmp;
}
}
void ShellSort(int *a,size_t size)
{
int gap=size;
while(gap > 1)
{
gap=gap/3+1; //确定增量
for (size_t i=gap;i<size;++i)
{
int tmp=a[i];
int pos=i-gap;
while (pos >= 0 && a[pos] > tmp)
{
a[pos+gap]=a[pos];
pos -= gap;
}
a[pos+gap]=tmp;
}
}
}
void testSort()
{
int a[]={2,5,4,9,3,6,8,7,1,0};
size_t size=sizeof(a)/sizeof(a[0]);
InsertSort(a,size);
Display(a,size);
ShellSort(a,size);
Display(a,size);
}















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









