







间歇性凌云壮志,于是就决定每天阅读一点jdk源码,从最简单的String开始。
1.
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
本来是因为不太懂-1>>>1是什么意思才搜了一下(与Integer.MAX_VALUE同义),然后在stackoverflow上发现一条大神的回答:

之所以是offset > codePoints.length - count而非offset + count > codePoints.length是为了防止接近Integer.MAX_VALUE的数在做加法会溢出
2.
StringBuffer和StringBuilder的区别,在String里也可窥得一丢丢


3.
String的hashcode方法,可以看出,第一次调用hashcode时,将算出来的值缓存到了对象内部
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
4.
public indexOf()和lastIndexOf()实现方式相似,都把传入的字符按特殊与否用if判断分成两类分别处理(以0x010000为分割)。
更值得一提的是,以indexOf为例,只有indexOf(int),而没有indexOf(char c)方法!但把字符比如’a’传入indexOf(int)后会异常和谐的自然转化成97,没有强转过程,于是测试:
int a='a';//char转int
char b=23;//int转char
byte a='a';//char转byte
以上代码通过编译正常运行,呃呃呃有点晕啊,基础东西丢了啊啊啊。
首先char类型本来就被分类为整数类型,char占16位而int占32位,小转大能自然转换实属正常,但下面两个。。。额,布吉岛
5.
String源码第1753行和1862行对应的是包可见的indexOf()和lastIndexOf()方法,这两个方法代码有点诡异,而且感觉上两个相似的方法,具体实现却大不一样。更蛋疼的是,lastIndexOf()中使用了带标记点的continue直接蹦出两层循环,额,留个心眼放这里供以后研究研究。。。
6.
substring(begin,end)方法,我们看它的返回值:
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
这里做了一个优化,如果选中的字符串正好是它本身,那么直接返回this,concat(String),replace(char,char)里也有类似的优化,针对一些特殊情况进行单独处理能有效提高效率。
向下追究一下,这里的new String()调用了Arrays.copyOfRange(),后者又调用了System.arraycopy(),这是个native方法
7.
偶然发现的之前漏掉的亮点,这个boolean share毫无卵用,为什么这样写?因为String中已经有一个String(char[]),去掉share的话,这个构造函数都无法声明。而String(char[])是调用Arrays.copyOf将数组拷贝一份,比起String(char[], boolean)直接传递引用慢了不止一筹,所以有时候内部调用String(char[], boolean)提高效率,还能节约空间。(声明,我自己一开始没看懂加一个boolean有何用,惭愧技不如人)
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
8.
在replace()中发现这样一句:
char[] val = value; /* avoid getfield opcode */
这一句的理解真心无能为力,涉及到jvm高阶知识了,直接上大牛解读:
在一个方法中需要大量引用实例域变量的时候,使用方法中的局部变量代替引用可以减少getfield操作(指获取指定类的实例域,并将其值压入栈顶的操作)的次数,提高性能
9.
关于replace(char oldChar, char newChar)方法,源码中是:先找到第一个值为oldChar的地方,然后在这之前的项不作比较直接放进结果数组,在这之后的项先判断该项是否值为oldChar,再决定是否替换。
源码给出的方法比起直接从头比较到尾,唯一的优化之处在于少比较了第一个值为oldChar之前的项。我类个大草,这优化太凶残了,不过想想也对,万一传入的oldChar并不在该字符串中,那源码中的方法直接不做改变的返回原字符串,而我的方法还要进行反复比较,孰优孰劣一目了然
10.
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
contains()方法挺有趣的,简单粗暴。不过很显然,对于正常的判断字符串是否存在,用indexOf()>-1更为高效一点
11.
trim()方法实际上是字符串截取,里面判断空格语句是这样的:val[st] <= ' ',直接干掉ascii码为32以前的所有字符
12.
看一下toCharArray()方法:
public char[] toCharArray() {
// Cannot use Arrays.copyOf because of class initialization order issues
char result[] = new char[value.length];
System.arraycopy(value, 0, result, 0, value.length);
return result;
}
注释理解不能,上大佬解答:
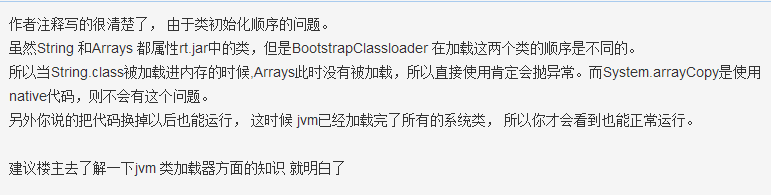
暂且总结一下
String源码,3169行,竟然就这么看完了。
源码80%是注释,而这20%的代码中实际上我只认真看了其中的20%,其它的有些是重复的代码,更多的是看不懂的代码。有些东西确实没必要去死磕,顺着代码一路递归下去,那源码简直是无穷无尽的,舍取还是很有所必要的。
说说感想吧。这段时间看源码,对直接的编程水平提高其实并没有什么促进作用,但这是一个积累的过程,站得高方能看得远,我见识到了世界上最顶尖最精彩的代码,取他山之石,为未来铺路。
下一站,集合框架。
12.
对比String和StringBuffer。
很多相似的功能,String方法会返回一个新的对象,而StringBuffer会返回this,so:
StringBuffer s1=new StringBuffer("12345");
StringBuffer s2=s1.append("上山打老虎");
System.out.println(s1==s2); //true
String s3="老虎没打着";
String s4=s3.concat("打到小松鼠");
System.out.println(s3==s4); //false
但是,String中的方法并不都是返回新对象,如之前第六条所说,有些方法会为特殊情况返回this,例如string==string.substring(0)结果为true














 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









