







ALS矩阵分解
http://blog.csdn.net/oucpowerman/article/details/49847979
http://www.open-open.com/lib/view/open1457672855046.html
一个 的打分矩阵 A 可以用两个小矩阵和的乘积来近似,描述一个人的喜好经常是在一个抽象的低维空间上进行的,并不需要把其喜欢的事物一一列出。再抽象一些,把人们的喜好和电影的特征都投到这个低维空间,一个人的喜好映射到了一个低维向量,一个电影的特征变成了纬度相同的向量,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积。
我们把打分理解成相似度,那么“打分矩阵
A(m∗n)
”就可以由“用户喜好特征矩阵
U(m∗k)
”和“产品特征矩阵
V(n∗k)
”的乘积。
矩阵分解过程中所用的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。
损失函数包括正则化项(setRegParam)。
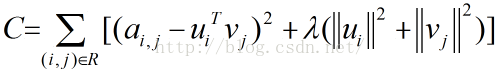
参数选取
- 分块数:分块是为了并行计算,默认为10。
- 正则化参数:默认为1。
- 秩:模型中隐藏因子的个数
- 显示偏好信息-false,隐式偏好信息-true,默认false(显示)
- alpha:只用于隐式的偏好数据,偏好值可信度底线。
- 非负限定
- numBlocks is the number of blocks the users and items will be
partitioned into in order to parallelize computation (defaults to
10). - rank is the number of latent factors in the model (defaults to 10).
- maxIter is the maximum number of iterations to run (defaults to 10).
- regParam specifies the regularization parameter in ALS (defaults to 1.0).
- implicitPrefs specifies whether to use the explicit feedback ALS variant or one adapted for implicit feedback data (defaults to false
which means using explicit feedback). - alpha is a parameter applicable to the implicit feedback variant of ALS that governs the baseline confidence in preference
observations (defaults to 1.0). - nonnegative specifies whether or not to use nonnegative constraints for least squares (defaults to false).
ALS als = new ALS()
.setMaxIter(10)//最大迭代次数,设置太大发生java.lang.StackOverflowError
.setRegParam(0.16)//正则化参数
.setAlpha(1.0)
.setImplicitPrefs(false)
.setNonnegative(false)
.setNumBlocks(10)
.setRank(10)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating");需要注意的问题:
对于用户和物品项ID ,基于DataFrame API 只支持integers,因此最大值限定在integers范围内。
The DataFrame-based API for ALS currently only supports integers for
user and item ids. Other numeric types are supported for the user and
item id columns, but the ids must be within the integer value range.
//循环正则化参数,每次由Evaluator给出RMSError
List<Double> RMSE=new ArrayList<Double>();//构建一个List保存所有的RMSE
for(int i=0;i<20;i++){//进行20次循环
double lambda=(i*5+1)*0.01;//RegParam按照0.05增加
ALS als = new ALS()
.setMaxIter(5)//最大迭代次数
.setRegParam(lambda)//正则化参数
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating");
ALSModel model = als.fit(training);
// Evaluate the model by computing the RMSE on the test data
Dataset<Row> predictions = model.transform(test);
//RegressionEvaluator.setMetricName可以定义四种评估器
//"rmse" (default): root mean squared error
//"mse": mean squared error
//"r2": R^2^ metric
//"mae": mean absolute error
RegressionEvaluator evaluator = new RegressionEvaluator()
.setMetricName("rmse")//RMS Error
.setLabelCol("rating")
.setPredictionCol("prediction");
Double rmse = evaluator.evaluate(predictions);
RMSE.add(rmse);
System.out.println("RegParam "+0.01*i+" RMSE " + rmse+"\n");
}
//输出所有结果
for (int j = 0; j < RMSE.size(); j++) {
Double lambda=(j*5+1)*0.01;
System.out.println("RegParam= "+lambda+" RMSE= " + RMSE.get(j)+"\n");
}
通过设计一个循环,可以研究最合适的参数,部分结果如下:
RegParam= 0.01 RMSE= 1.956
RegParam= 0.06 RMSE= 1.166
RegParam= 0.11 RMSE= 0.977
RegParam= 0.16 RMSE= 0.962//具备最小的RMSE,参数最合适
RegParam= 0.21 RMSE= 0.985
RegParam= 0.26 RMSE= 1.021
RegParam= 0.31 RMSE= 1.061
RegParam= 0.36 RMSE= 1.102
RegParam= 0.41 RMSE= 1.144
RegParam= 0.51 RMSE= 1.228
RegParam= 0.56 RMSE= 1.267
RegParam= 0.61 RMSE= 1.300
//将RegParam固定在0.16,继续研究迭代次数的影响
输出如下的结果,在单机环境中,迭代次数设置过大,会出现一个java.lang.StackOverflowError异常。是由于当前线程的栈满了引起的。
numMaxIteration= 1 RMSE= 1.7325
numMaxIteration= 4 RMSE= 1.0695
numMaxIteration= 7 RMSE= 1.0563
numMaxIteration= 10 RMSE= 1.055
numMaxIteration= 13 RMSE= 1.053
numMaxIteration= 16 RMSE= 1.053
//测试Rank隐含语义个数
Rank =1 RMSErr = 1.1584
Rank =3 RMSErr = 1.1067
Rank =5 RMSErr = 0.9366
Rank =7 RMSErr = 0.9745
Rank =9 RMSErr = 0.9440
Rank =11 RMSErr = 0.9458
Rank =13 RMSErr = 0.9466
Rank =15 RMSErr = 0.9443
Rank =17 RMSErr = 0.9543
//可以用SPARK-SQL自己定义评估算法(如下面定义了一个平均绝对值误差计算过程)
// Register the DataFrame as a SQL temporary view
predictions.createOrReplaceTempView("tmp_predictions");
Dataset<Row> absDiff=spark.sql("select abs(prediction-rating) as diff from tmp_predictions");
absDiff.createOrReplaceTempView("tmp_absDiff");
spark.sql("select mean(diff) as absMeanDiff from tmp_absDiff").show();
完整代码
public class Rating implements Serializable{...}
可以在 http://spark.apache.org/docs/latest/ml-collaborative-filtering.html找到:
package my.spark.ml.practice.classification;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.ml.evaluation.RegressionEvaluator;
import org.apache.spark.ml.recommendation.ALS;
import org.apache.spark.ml.recommendation.ALSModel;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class myCollabFilter2 {
public static void main(String[] args) {
SparkSession spark=SparkSession
.builder()
.appName("CoFilter")
.master("local[4]")
.config("spark.sql.warehouse.dir","file///:G:/Projects/Java/Spark/spark-warehouse" )
.getOrCreate();
String path="G:/Projects/CgyWin64/home/pengjy3/softwate/spark-2.0.0-bin-hadoop2.6/"
+ "data/mllib/als/sample_movielens_ratings.txt";
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF);
//-------------------------------1.0 准备DataFrame----------------------------
//..javaRDD()函数将DataFrame转换为RDD
//然后对RDD进行Map 每一行String->Rating
JavaRDD<Rating> ratingRDD=spark.read().textFile(path).javaRDD()
.map(new Function<String, Rating>() {
@Override
public Rating call(String str) throws Exception {
return Rating.parseRating(str);
}
});
//System.out.println(ratingRDD.take(10).get(0).getMovieId());
//由JavaRDD(每一行都是一个实例化的Rating对象)和Rating Class创建DataFrame
Dataset<Row> ratings=spark.createDataFrame(ratingRDD, Rating.class);
//ratings.show(30);
//将数据随机分为训练集和测试集
double[] weights=new double[] {0.8,0.2};
long seed=1234;
Dataset<Row> [] split=ratings.randomSplit(weights, seed);
Dataset<Row> training=split[0];
Dataset<Row> test=split[1];
//------------------------------2.0 ALS算法和训练数据集,产生推荐模型-------------
for(int rank=1;rank<20;rank++)
{
//定义算法
ALS als=new ALS()
.setMaxIter(5)最大迭代次数,设置太大发生java.lang.StackOverflowError
.setRegParam(0.16)
.setUserCol("userId")
.setRank(rank)
.setItemCol("movieId")
.setRatingCol("rating");
//训练模型
ALSModel model=als.fit(training);
//---------------------------3.0 模型评估:计算RMSE,均方根误差---------------------
Dataset<Row> predictions=model.transform(test);
//predictions.show();
RegressionEvaluator evaluator=new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction");
Double rmse=evaluator.evaluate(predictions);
System.out.println("Rank =" + rank+" RMSErr = " + rmse);
}
}
}














 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









