









Keras版Faster-RCNN代码学习(IOU,RPN)1
Keras版Faster-RCNN代码学习(Batch Normalization)2
Keras版Faster-RCNN代码学习(loss,xml解析)3
Keras版Faster-RCNN代码学习(roipooling resnet/vgg)4
Keras版Faster-RCNN代码学习(measure_map,train/test)5
损失函数
在Faster-RCNN里主要有4种损失,RPN分类损失、RPN框回归损失、最后的分类损失、最后的框回归损失。
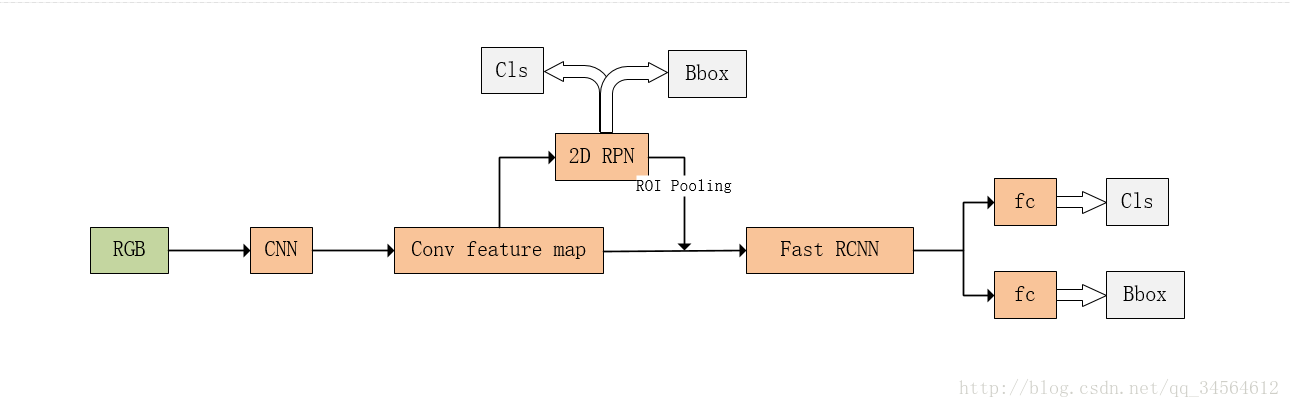
损失函数主要衡量预测值和真实值差异,可以使用基于梯度的学习方法,对参数进行学习。
在keras中,自定义的损失函数以下列两个参数为参数:
- y_true:真实的数据标签,Theano/TensorFlow张量
- y_pred:预测值,与y_true相同shape的Theano/TensorFlow张量
分类为交叉熵,回归用L1smooth,batchsize均为框的数量,且RPN和最后的总损失不一样
losses.py
from keras import backend as K
from keras.objectives import categorical_crossentropy
if K.image_dim_ordering() == 'tf':
import tensorflow as tf
lambda_rpn_regr = 1.0
lambda_rpn_class = 1.0
lambda_cls_regr = 1.0
lambda_cls_class = 1.0
epsilon = 1e-4
#RPN框回归损失,先传递框的数量
def rpn_loss_regr(num_anchors):
def rpn_loss_regr_fixed_num(y_true, y_pred):
if K.image_dim_ordering() == 'th':
x = y_true[:, 4 * num_anchors:, :, :] - y_pred
x_abs = K.abs(x)
x_bool = K.less_equal(x_abs, 1.0)
return lambda_rpn_regr * K.sum(
y_true[:, :4 * num_anchors, :, :] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :4 * num_anchors, :, :])
else:
x = y_true[:, :, :, 4 * num_anchors:] - y_pred
x_abs = K.abs(x)
x_bool = K.cast(K.less_equal(x_abs, 1.0), tf.float32)
return lambda_rpn_regr * K.sum(
y_true[:, :, :, :4 * num_anchors] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :, :, :4 * num_anchors])
return rpn_loss_regr_fixed_num
#RPN分类损失,先传递框的数量
def rpn_loss_cls(num_anchors):
def rpn_loss_cls_fixed_num(y_true, y_pred):
if K.image_dim_ordering() == 'tf':
return lambda_rpn_class * K.sum(y_true[:, :, :, :num_anchors] * K.binary_crossentropy(y_pred[:, :, :, :], y_true[:, :, :, num_anchors:])) / K.sum(epsilon + y_true[:, :, :, :num_anchors])
else:
return lambda_rpn_class * K.sum(y_true[:, :num_anchors, :, :] * K.binary_crossentropy(y_pred[:, :, :, :], y_true[:, num_anchors:, :, :])) / K.sum(epsilon + y_true[:, :num_anchors, :, :])
return rpn_loss_cls_fixed_num
#最后的回归损失
def class_loss_regr(num_classes):
def class_loss_regr_fixed_num(y_true, y_pred):
x = y_true[:, :, 4*num_classes:] - y_pred
x_abs = K.abs(x)
x_bool = K.cast(K.less_equal(x_abs, 1.0), 'float32')
return lambda_cls_regr * K.sum(y_true[:, :, :4*num_classes] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / K.sum(epsilon + y_true[:, :, :4*num_classes])
return class_loss_regr_fixed_num
#最后的分类损失
def class_loss_cls(y_true, y_pred):
return lambda_cls_class * K.mean(categorical_crossentropy(y_true[0, :, :], y_pred[0, :, :]))XML解析
xml.etree.ElementTree模块可用来简单的XML文档中提取数据,xml.etree.ElementTree.parse()函数将整个XML文档解析为一个文档对象。之后可以用find()、iterfind()、findtext()等方法查询特定的XML元素。这些函数的参数就是特定的标签。每个由ElementTree模块所表示的元素都有一些重要的属性和方法,如:tag属性中包含了标签的名称,text包含有附着的文本。即,按标签找文本
VOC2007xml文件
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size>
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation> pascal_voc_parser.py
import os
import cv2
import xml.etree.ElementTree as ET
import numpy as np
#文件夹路径分配
def get_data(input_path):
all_imgs = []
classes_count = {}
class_mapping = {}
visualise = False
data_paths = [os.path.join(input_path,s) for s in ['VOC2007', 'VOC2012']]
print('Parsing annotation files')
for data_path in data_paths:
annot_path = os.path.join(data_path, 'Annotations')
imgs_path = os.path.join(data_path, 'JPEGImages')
imgsets_path_trainval = os.path.join(data_path, 'ImageSets','Main','trainval.txt')
imgsets_path_test = os.path.join(data_path, 'ImageSets','Main','test.txt')
trainval_files = []
test_files = []
try:
with open(imgsets_path_trainval) as f:
for line in f:
trainval_files.append(line.strip() + '.jpg')
except Exception as e:
print(e)
try:
with open(imgsets_path_test) as f:
for line in f:
test_files.append(line.strip() + '.jpg')
except Exception as e:
if data_path[-7:] == 'VOC2012':
# this is expected, most pascal voc distibutions dont have the test.txt file
pass
else:
print(e)
annots = [os.path.join(annot_path, s) for s in os.listdir(annot_path)]
idx = 0
#依次解析XML文件
for annot in annots:
try:
idx += 1
et = ET.parse(annot)
element = et.getroot()
element_objs = element.findall('object')
element_filename = element.find('filename').text
element_width = int(element.find('size').find('width').text)
element_height = int(element.find('size').find('height').text)
if len(element_objs) > 0:
annotation_data = {'filepath': os.path.join(imgs_path, element_filename), 'width': element_width,
'height': element_height, 'bboxes': []}
if element_filename in trainval_files:
annotation_data['imageset'] = 'trainval'
elif element_filename in test_files:
annotation_data['imageset'] = 'test'
else:
annotation_data['imageset'] = 'trainval'
for element_obj in element_objs:
class_name = element_obj.find('name').text
if class_name not in classes_count:
classes_count[class_name] = 1
else:
classes_count[class_name] += 1
if class_name not in class_mapping:
class_mapping[class_name] = len(class_mapping)
obj_bbox = element_obj.find('bndbox')
x1 = int(round(float(obj_bbox.find('xmin').text)))
y1 = int(round(float(obj_bbox.find('ymin').text)))
x2 = int(round(float(obj_bbox.find('xmax').text)))
y2 = int(round(float(obj_bbox.find('ymax').text)))
difficulty = int(element_obj.find('difficult').text) == 1
annotation_data['bboxes'].append(
{'class': class_name, 'x1': x1, 'x2': x2, 'y1': y1, 'y2': y2, 'difficult': difficulty})
all_imgs.append(annotation_data)
if visualise:
img = cv2.imread(annotation_data['filepath'])
for bbox in annotation_data['bboxes']:
cv2.rectangle(img, (bbox['x1'], bbox['y1']), (bbox[
'x2'], bbox['y2']), (0, 0, 255))
cv2.imshow('img', img)
cv2.waitKey(0)
except Exception as e:
print(e)
continue
return all_imgs, classes_count, class_mapping














 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









