









RMQ 是Range Minimum(Maximum) Query的简称。
给定一个数组a1,a2,a3,a4,a5......设计一个数据结构,支持查询操作Query(L,R) ; 计算min(a1,a2,a3,a5....) 或max(a1,a2,a3,a4.....)
最简单的方法就是遍历查询,时间复杂度是O(n),但是如果数组大,并且查询次数也非常大,那么效率是非常低的。
ST算法:
1.设dp[ i ][ j ]表示从i元素开始 1>>j 个数中的最值
2.求出dp[ i ][ j ]
3.查询Query( x, y) 将 y 转换为 k
4.答案 max( dp [ x ][ k ] , dp[ y-(1<<k)+1 ][ k ])
有2个需要解决的问题:
1.dp数组如何求
2.查询长度如何转换( y如何转换成 k)
解决方法:
1.dp数组如何求。
当dp[ i ][ j ] 中 j=0 时 ,dp[ i ][ 0 ] = a[ i ] (a数组表示待查询的数组)
每个查询区间都可以分成2个小区间( 二分法 ),求出2个小区间的最值,然后取两者的最值即可。同样被分成的小区间可以继续二分,这样就出现的子问题。可以写出状态转移方程:
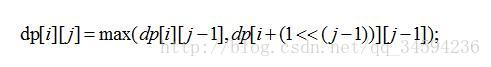
2.查询长度如何转换( y 如何转换成 k )
y-x+1表示的是x到y的长度 得到等式:
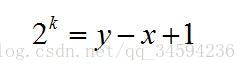
两边同时取对数log2后可求的k的值
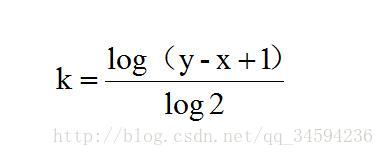
下面给出算法的核心代码
//ST(Sparse-Table)算法
void RMQ(){
for(int i=1 ;i<=n ;i++) dp[i][0]=a[i];
//注意从j变量在外层,先求短区间
for(int j=1 ;(1<<j)<=n ;j++){
for(int i=1 ;i+(1<<j)-1<=n ;i++){
dp[i][j] = max(dp[i][j-1],dp[i+(1<<(j-1))][j-1]);
}
}
}
//求k代码
int k = (int)(log(y - x + 1.0) / log(2.0));
//求最值
int ans = max(dp[x][k],dp[y-(1<<k)+1][k]);注:有读者可能会疑惑,既然 dp[ i ][ j ] 表示从 i 开始 1<<j 个数中的最值,为什么不是直接输出呢。
试想:
如果 给定查询区间 2-4 即第2,3,4号元素,一共有3个元素,求得的 k = 1 (强制转换为int型后),那么dp[ i ][ k ] 查询的就是2 ,3元素。答案肯定是不对的。而dp [ x ][ k ] 和 dp[ y-(1<<k)+1][ k ]分别查询的是 2,3 和3,4。 去两者的最值,一定是答案。
如果是偶数,那该式还成立吗,假设查询区间是2-5,即第2,3,4,5号元素,k=2。 y-(1<<k) == x ,说明两个查询的区间都是相同的。所以不能直接输出dp[ x ][ k ]。















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









