










为什么有个错误衡量
在看完周志华老师《机器学习》中的归纳偏好中有这样的描述:归纳偏好就是要做出学习算法本身“什么样的模型更好”的假设。在这里我们要给模型的好坏下一个定义如果算法A比算法B好,那么一定要定义什么是好。在没有定义什么是好之前我们无法找到我们的模型要训练的方向。那么反过来当我们遇到错误的时候我们就要给错误下一个定义。
举一个例子,在战争时期我打死一个敌人对于我方来说是一件好事(正确),但在敌方来看这就是一件坏事(错误)。所以我们就要针对不同的问题提出不同的错误衡量来使得算法趋向于我们想要的方向。
一个错误衡量的实例
在以下的案例中我们的数据完全一样,但是因为有了错误衡量所以我们就有了两种完全不同的结果

在接下来我们会用两种不同的错误衡量来选择出最佳结果,如上图所示我们使用的是平均错误与平方错误

从图中我们可以看出在平均错误的情况下我们得到的最好的结果是2因为(错误率为0.3)最坏的结果为1.9(错误率为1),而在平方错误下我们的最优结果是1.9(错误率为0.29)而最差的结果为3(错误率为1.5)。这就是错误衡量的力量。(平方错误的计算方法为‘以1为例’(2-1)^2*0.7+(3-1)^2*0.1 = 1.1)
错误衡量的选择
常见的二元分类的错误有弃真(把把对的拒之门外)与取伪(把敌人当做亲人)。他们在不同的场合有不同的权重,比如对于保密局的门禁系统来说取伪的错误权重是很高的。我们可以说放进来一个坏人比将一个自己人拒之门外的情形坏1000倍!那为什么是1000倍?
事实上1000并不是一个最佳的定量的做法,有时候只是我们直觉性的估计。在实务上我们的错误衡量有以下的两种:
1.有严格的逻辑推理与严格的说明(这种方法很困难)。
2.没有太多的理论保证,但是我们可以在电脑上相对容易的实现。
至于不同的问题我们会有不同的选择。
错误权重的等价
在实务上我们要在不同的错误上给予不同的权重,假如说我们要在一个二分的例子中给予一个点犯错误后的权重是其它点的1000倍,那么我们可以将情景等价于将这个点的错误权重变为1而在数量上*1000。这样我们就完成了从1000*1==1*1000的转化。在转化过后的问题上我们可以使用最基础的理论解决这个机器学习算法的问题。
加上错误衡量之后的流程图
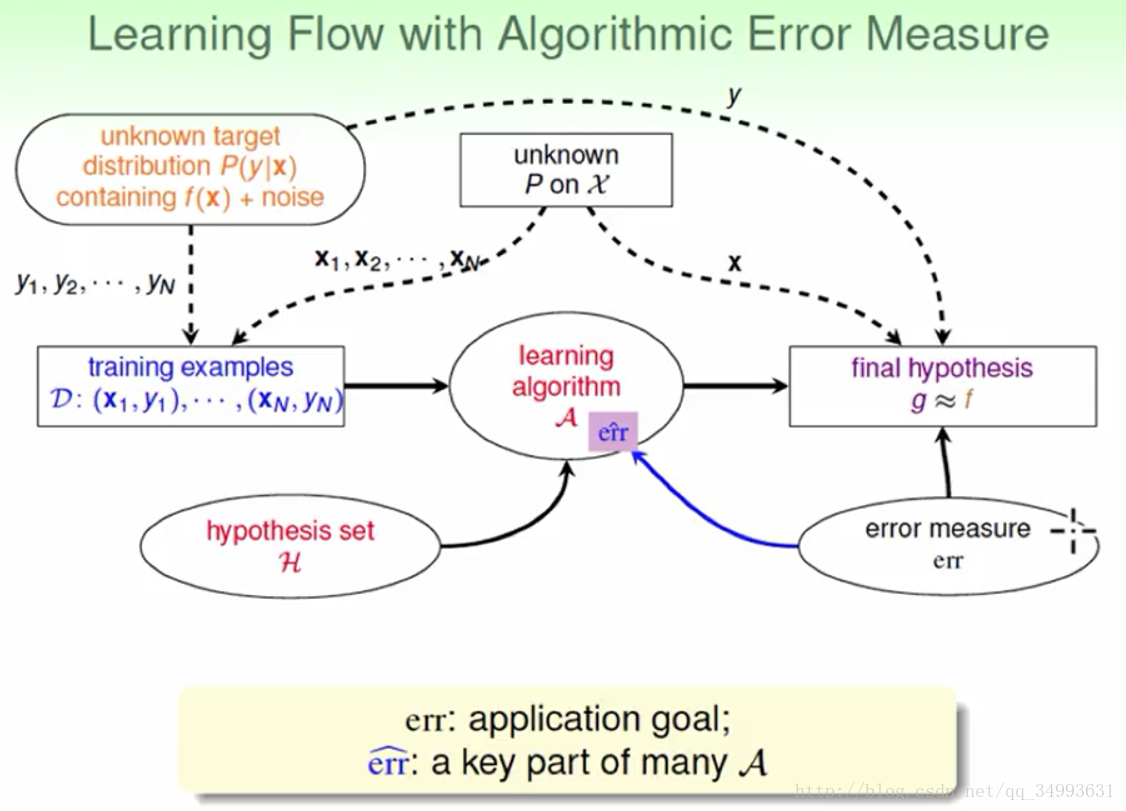
总结一下:我们的错误衡量引导了算法使得我们选到的最佳模型更加适合于我们的问题。















 6364
6364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











