









0. 写在前面
从这一节开始,我们就进入到了第二周的学习,这才是真正的内容。
1. 约定符号
在我们开始讲logistic回归问题时,我们需要对一些符号进行一定的约定,这样非常有助于后面的理解(这是真的,尤其是在Tensorflow或者CNTK等框架中,同样是这样的表述)。
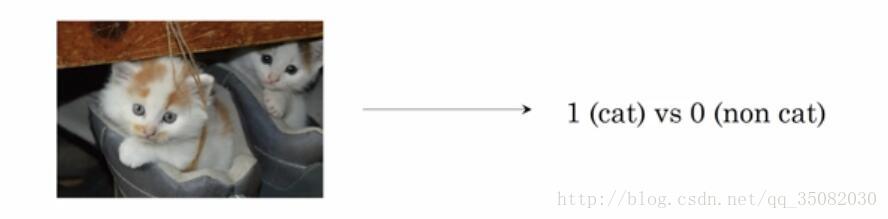
首先,logistic回归问题是一个二分类问题,即给定一些输入,输出只会有0或者1,正如下图所示,判断图片里的内容只有是不是猫两种答案。
虽然我们称图片为非结构化数据,但是它并非没有结构,在计算机中,它是以Red、Green、Blue三种颜色的矩阵存储的(这只是其中一种编码,RGB编码,其实还有其他编码方式),就如同下图所示,那么如果是把这个作为输入的话,那么我们会把所有单元内的数排列成一个长长的向量。
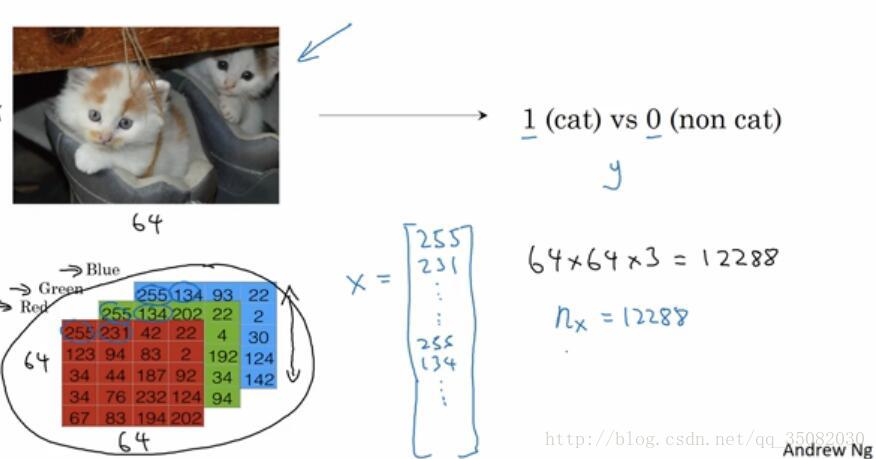
就如同那个X所示,假设每张图片有64*64那么个大小(图片里展示的只是一个5*4的示例),那么所有的数字数目为12288,即x的维度是12288维,在我们约定的符号里,使用n表示样本的维度。而m表示样本的个数,并把所有的样本集统一为一个大矩阵,其中样本以列形式存储,即如图所示。
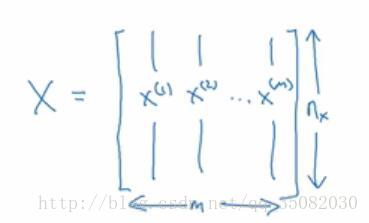
这样我们使用X作为输入集合,也就是样本集。那么输出也是用矩阵的形式存储,即一个1*m大小的矩阵。

这样在接下来的讲解中,我们会更加清晰。
2. logistic回归
2.1 logistic函数与神经元
正如上面讲的,我们首先从logistic回归开始讲起。logistic回归是一个二分类的问题,例如给一张图片,然后判断是不是猫。输入和输出如第一节中所讲的X和y,那么我们希望有这样一个函数,能够表示出这样一个过程。即:
y^=P(y=1|X)
,我们想知道
y^
。那么最简单的线性拟合的话,就如下公式所示(所有的大写都是向量,小写是标量):
但是这样并不是一个非常好的二元分类方法,因为 y^ 是一个概率值,它介于0和1之间。而现在这个数值有可能非常大,也有可能为负值。那么这时候就需要一个sigmoid函数来约束值域。
sigmoid函数为: σ(z)=11+e−z
其函数图像如下图所示:

它值域在0-1之间,在x=0时,y=0.5。而在两端分别趋近于0和1。这样就可以约束值域了。(事实上,这也是可以加快收敛速度的一种方法)
这样整体函数就变为: σ(y^) 这如果形象一点的话,前面的 y^ 就是一个求和单元,而后面的 σ(z) 就是一个激活函数,这样其实就已经是一个完整的神经元了。下面我们进入最神秘的训练环节。
2.2损失函数与成本函数
如果要训练,那么首先要知道训练的目标是什么。当然,训练的目标就是使得我们的模型输出和真实输出尽可能的一致,即
y^和y
尽可能一致。那么具体怎么做呢。对于单个样本来说,我们称衡量这个一致的标准为损失函数。通常的,可以使用0-1损失函数,即:
但是这个函数是非凸的,也就是会存在很多局部最优解,这样梯度下降法就找不到最优值。因此,通常在梯度下降法中,都是用log损失函数:
这其实是和0-1损失函数目的是一样的,只不过看起来怎么这么怪呢,其实它就是交叉熵的具体表现形式。也就是想让 y^和y 的交叉熵最小,从而间接的达成两者一致。
而对于所有样本来说,衡量这个模型的好坏取决于成本函数,成本函数则是所有样本损失和的平均值,只有这个越小,才能证明整个模型性能越好。
2.3梯度下降法
梯度下降法看起来是一个非常神秘又非常重要的东西,但事实上,梯度下降法首先应当知道梯度是什么。
标量场中某一点上的梯度指向标量场增长最快的方向,梯度的长度是这个最大的变化率。
其实就是说,它是整个场中在所有方向都考虑在内的下降最快的方向。也就是说,如果这是一个单变量的函数的话,它其实就是导数。下面两幅图能够直观的理解一下什么是梯度。
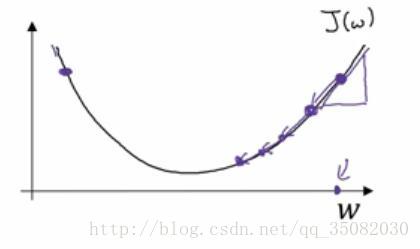
在w,b二变量的三维空间中,我们要找的就是尽可能的到达最低的那个红点,因为我们可以看到这个高度表示的是成本函数,我们是要使得成本函数最小,而且是更快的到达那个最低点,这就是顺着梯度下降最快。
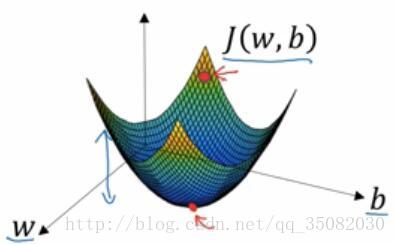
而在下图的w一变量的二维空间中,这就变成了顺着导数下降最快。
如果用数学公式来体现的话:
事实上,w一般也是一个向量,也就是多变量,因此我们这里使用偏导数是没有问题的。(吴恩达建议使用dw的形式,因为它觉得一方面编码容易,另一方面也没有什么实质差距那个偏导符号其实就是花体的d)
这里还有一个 α ,指的是学习率,也就是说一次移动的规格大概是多少,通常是一个小于1的数,这就是相当于步子有多大,如果步子太大,有可能就错过了最佳点,如果步子太小,那么有可能迭代次数过多,而且容易陷入局部最优点。
现在回想一下整个过程,其实是非常理所当然的事情,正如我们扔飞镖一样,如果我们第一次往左偏了,那么我们下一次就有可能朝着相反的方向修正,而修正多达幅度,一方面看自己偏了多少,二是看自己策略(是慢慢靠近中心,还是先来个大幅度改进)。
当然,吴恩达的视频中,还是很详尽的介绍了梯度下降法与导数。这里我们不多介绍,在下一节中,我们会给出最直观的图像来结束我们的梯度下降法。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











