







一、基本原理
- 音频信号
通常将人耳可以听到的频率在20hz-20khz的声波称为声音信号,声音振动被拾音器转化为的电信号称为音频信号。人说话的信号频率在300hz到3000hz,将该频段的信号称为语音信号。 - 压缩的可行性
声音信号中存在大量的冗余信息,在不同的分析域冗余的表现不同,结合时域和频率域可以较好的去除冗余。在时域,信号的幅度分度非均匀,小幅度样值出现概率比大幅度样值出现概率高;语音信号变化比较缓慢,各信号样值间的相关性较强,可以用差分编码去除冗余。在频域,长时功率谱函数分布非均匀,低频能量高,高频能量低。
声音中存在一些人耳感觉不到的部分,根据人耳的心理听觉模型可以找出这部分冗余信息,并把它去除掉,而不影响人的听觉效果。 - MPEG-1 层二编码器原理
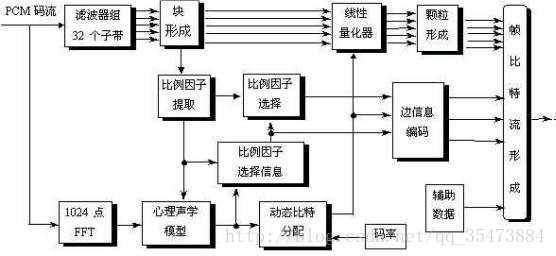
多相滤波器组:将pcm样本变换到32个子带的频域信号,如果输入的采样频率为48khz,那么子带宽度为48/(2*32)=0.75hz;其中48/2表示信号的最高频率。
心理声学模型:计算信号中不可感知的部分,利用人耳的掩蔽效应,找到声音信号中冗余的部分。
比特分配器:根据心理声学模型的计算结果,为每个子带信号
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









