







前言
The years teach much which the days never knew.
Time:2017/2/19
Name:Willam
1、介绍
对于文本程序来说,找出一个子串在文本中的位置是特别重要的,我们称那个子串为模式串(pattern),然后我们称寻找的过程为:模式匹配(string match)。
2、实现算法(1)—朴素字符串匹配算法
原理:从主串的指定的起始位置字符开始和模式第一个字符比较,如果相等,则继续比较下一个字符,如果不等,则从主串的下一个字符开始和模式的第一个字符开始比较,以此类推,直到模式串所有字符都匹配完成,则匹配成功,否则,匹配不成功。
代码实现
//pos是从1开始的一个下标
int index_force(char * s, char * t,int pos)
{
int i=pos-1;
//判断pos是否合法
if(!s[i])
cout<<"起始位置不合法"<<endl;
int j=0;
while(s[i]!='\0' && t[j]!='\0')//主串或者模式串遍历完成
{
if(s[i]==t[j])//如果主串和模式串对应位置的值相等,则比较后面的字符
{
++i;
++j;
}
else //如果不相等,则模式串需要回朔到第一个字符,而主串则从下一个字符开始
{
i=i-j+1;
j=0;
}
}
if(t[j]=='\0')//如果循环是由于模式串遍历完了而结束的,说明找到了对应子串的位置
{
return i-j+1;
}
else //否则,主串不包含模式串
{
return 0;
}
}
时间复杂度的分析:我们这里只分析最坏的情况,那就是对于长度为n的模式串和长度为m的主串,模式串前n-1都是同样的字符而且主串的前m-1也是和模式串一样的字符,例如:模式串为:000001,主串为:000000000000000000000001,则对于这种情况的时间复杂度为:其中我们需要回朔:m-n+1次,每次都要比较:n次,所以我们的时间复杂度为:o((m-n+1)n)
3、实现算法(2)—-KMP算法的实现
简介:KMP算法它是有Knuth、Morris和Pratt三个人同时发现的,所以我们称之为KMP算法。它是一个很优秀的算法,通过对模式串的一个预处理,将我们的时间复杂度减少到了一个线性的水平。
剖析算法的原理:
下面我们将在实际的应用中来解释这个算法,首先我们有主串:acabaabaabcacaabc,有模式串:abaabcac,现在假设我们匹配到了如下的图的步骤:

现在模式串的第六个字符和主串匹配不上了,那么现在我们就需要把模式串往右移动,并且重新选择主串和模式串的比较位置重新开始比较。那么如果是朴素法的话,我们是直接把模式串往右移动一格,然后,主串的第四个字符和我们模式串的第一个字符重新开始做比较。但是,你要知道其实主串的第三个字符到第六个字符我们都是已经和模式串做过比较的,而且我们知道他们的各个位置上的内容是什么,那么为什么不把这些已经知道的信息充分利用起来了?比如:我们知道模式串中红色的两个字符和绿色的两个字符是相等的,而且红色的两个字符正好是模式串开始的两个字符,所以我们可以直接把模式串向右移动四位,然后,我们主串从刚才发现不匹配那个字符位置开始和模式串的第三个位置比较,这样我们就可以减少五次比较。
哇噻,就是一个简单的处理,就给我们的程序效率带来了质的飞越,那么现在程序的最要紧要解决的问题就是我们主串比较位置不做任何改动,那么我们怎么知道该从模式串的哪个位置开始做比较了,这个时候,我们就需要对我们的模式串做一个预处理,通过预处理我们可得到一个next数组,它保存的就是当我们在模式串某个位置匹配失败后,应该从模式串的哪个位置重新开始比较。要求得next数组,那么我们就要理解刚才的那个例子为什么可以从模式串的第三个位置重新开始比较。其实next数组就是说对于模式串j这个位置之前(1到j-1)的串中,是否存在从模式串第一个位置出发往右移动得到的子串和从模式串的第j-1个字符位置出发往左移动得到的子串匹配,而且当该串达到最大长度时,则next值就是该串的长度加一,例如:abaabc这个模式串中,在c这个位置之前存在一个最大子串:ab。然后,我们next值就是记录这个最大子串的下一个字符的位置,其实说到这里,我们也就理解到了为什么要第三个字符了,因为模式串的前两个字符已经和主串匹配成功了(生成next值的时候,就完成了这个任务),所以不用再比较了。
代码实现:
get_next函数的实现
//next函数的实现,
void get_next(char * s,int * next)
{
int i=0; //next数组的下标
int j=-1; //next值
next[0]=-1;
while(s[i]!='\0')
{
if(j==-1 || s[i]==s[j]) //如果不存在或这条件符合了,那么就可以得到next值了
{
++i;++j;
next[i]=j;
}
else{
j=next[j];
}
}
}KMP函数的实现:
//KMP算法的实现
int KMP(char * s,char * t,int pos)
{
int j=0;
while(t[j++]!='\0');
int * next=new int[j-1];
int length=j-1; //串的长度
//调用函数,生成对应的next值
get_next(t,next);
int i=pos-1;//主串的起始位置
j=0;//模式串的下标
while(s[i]!='\0' && j<length)
{
if(j==-1 || s[i]==t[j]) //考虑到第一个不相等的情况
{
++i;++j;
}
else
{
j=next[j]; //如果不相等,则从next值开始下一次比较(模式串的右移)
}
}
if(t[j]=='\0' && j!=-1)
{
return i-j+1;
}
else
{
return 0;
}
}
算法的改进:
其实我们的next函数还是有一点缺陷,我们还可以通过一定的改进,让我们的算法的得到进一步的优化,例如:当我们的模式串为:ooooa,主串为:ooocooooa,我们根据之前的next函数可以得到next数组的值为:-10123,所以当我们的模式串的第四个字符和主串的第四个字符发生不相等的时候,我们还需要额外的三次比较,才知道这个我们应该直接把主串往前移动一位,后继续比较。其实,我们完全可以在生成next值的时候,避免这种情况出现,代码修改如下:
//next函数的实现,
void get_next(char * s,int * next)
{
int i=0; //next数组的下标
int j=-1; //next值
next[0]=-1;
while(s[i]!='\0')
{
if(j==-1 || s[i]==s[j]) //如果不存在或这条件符合了,那么就可以得到next值了
{
++i;++j;
//修改代码部分
if(s[i]!=s[j])//只有两者不相等的时候,才需要更换next值
next[i]=j;
else
next[i]=next[j];
}
else{
j=next[j];
}
}
}时间复杂度的分析:KMP算法就有两个步骤:第一个就是花费:O(m)的时间去对模式串进行预处理,其中m为模式串的长度,另外一个就是遍历主串,最坏的情况就是:O(n),其中n为主串的长度,所以KMP的时间复杂度为:O(m+n)
4、实现算法(4)—Horspool算法
简介:Horspool算法是一个基于后缀匹配的一种模式匹配算法,它算是匹配算法中的一种的新的创新,因为我们在匹配模式串的时候,都是从左向右匹配的,但是Horspool却是从右向左匹配,其实它的这种思路我们也是知道的:那就为了让模式串可以尽可能的向右移动的距离长一点,这样我们的匹配算法的效率才会提高,那么后缀匹配的方法到底有什么好处了,通过下面这幅图,你就明白了

我们如果从模式串的最后一个字符开始比较,那么当第一个字符不可以的时候,我们可以马上停止比较其他字符,从而节省多次比较。当然,我们怎么知道我们需要把模式串往右移动多少位了,那么这个正是Horspool算法要做的事情
算法原理的剖析
模式串从右向左进行匹配。对于每个文本搜索窗口(其实就是主串中一个和模式串长度相等的子串,我们称之位一个文本搜索窗口),将窗口内的最后一个字符与模式串的最后一个字符进行比较。如果相等,则继续从后向前验证其他字符,直到完全相等或者某个字符不匹配。然后,无论匹配与否,都将根据在模式串的下一个出现位置将窗口向右移动。模式串与文本串口匹配时,模式串的整体挪动,是从左往右,但是,每次挪动后,从模式串的最后一个字符从右往左进行匹配。,算法的解释可能太过抽象,那么下面我们直接看一个示例:其中我们的主串是:abcbcsdcodecbcac,模式串是:cbcac
模拟Horspool算法模式匹配的过程:
(1)第一步

首先,我们从对主串和模式串从左向右进行匹配,发现模式串的第四个字符(a)和主串的字符(b)不匹配,那么这个时候我们就要移动模式串,我们需要从模式串的右边向左寻找。模式串是否有字符(b),我们就在模式串的第二个位置找到了,所以我们就需要把模式串的b和主串上的b对齐,换句话说,就是模式串需要往右移动两位(3-1,其中3是不匹配时,模式串中字符的下标,另外一个就是b在模式串中的下标,下标是从0开始)
(2)第二步

现在,我们继续从右向左比较模式串和主串的值,然后,我们发现第一个字符就不匹配了,其中,主串不匹配的字符为:d,然后,从右向左在模式串中寻找d,最后发现,模式串中没有d,那么我们直接把模式串整体往右移动到其第一个字符和主串刚刚那个不匹配字符d的下一个字符(c)对齐,其中,模式串整体往右移动了5个位置(4-(-1)=5,其中4是模式串不匹配时,模式串值中那个字符的下标,因为d不存在于模式串中,所以我们寻找到的下标为:-1)
(3)第三步

我们重复第二步的步骤,因为e同样不在模式串中。
(4)第四步

好了,经过了四个步骤,我们终于匹配成功,通过了这个例子我们应该已经知道了Horspool算法的原理了,并且代码实现,应该也很容易了。
我们得到的规则只有一条,即:
**字符串后移位数=失配字符位置-失配字符上一次出现的位置**
如果失配字符根本就没有出现在模式串中,我们将“失配字符上一次出现的位置”的值视为-1。
代码实现:
//Horspool函数的实现
int Horspool(char * source,char * pattern)
{
int source_length=strlen(source);
int pattern_length=strlen(pattern);
int i=0; //主串的下标的移动
int j=0; //模式串的下标
int k=0;
char misch; //记录未匹配成功时,主串上的字符
int mis_dis=0;
for(i=0;i<=source_length-pattern_length;)//注意终止条件,就是当剩余的串已经不够长时,就可以终止了
{
for(j=pattern_length-1;j>=0;--j)
{
if(source[i+j]!=pattern[j])
{
misch=source[i+j];
mis_dis=j;
break;
}
if(j==0)
return i+1;
}
//寻找模式串中是否有未匹配的字符
for(k=mis_dis-1;k>=0;--k)
{
if(pattern[k]==misch)
{
i+=(mis_dis-k);
cout<<"i="<<i<<endl;break;
}
if(k==0)//不存在的时候
{
i+=(mis_dis+1);
cout<<"i="<<i<<endl;
}
}
}
return 0;
} 5、实现算法(3)—-BM算法
简介:BM算法是在1977年由Robert S.Boyer和J Strother Moore提出的一个基于后缀匹配的模式匹配算法,它的匹配速度比KMP都还快4-5倍,而且在绝大多数的场合下的应用性能极嘉,比如我们经常使用的Ctrl+F就是通过这个算法实现模式匹配的。
算法原理的剖析
BM算法性能之所以可以比KMP算法好,第一个原因就是它使用了后缀匹配的模式匹配算法(这里在Horspool里解释了原因),另外,一个就是它对当模式串出现不匹配的情况时,采取两种方式并行移动模式串的算法,其中一种叫:坏字符规则,还有一种叫做:好后缀规则。
好了,在介绍什么是坏字符规则和好后缀规则之前,我们先来看看什么是坏字符和好后缀。如下图所示:

如上图,第一行就是主串,第二行为模式串,当模式串匹配到红线的时候,发现和主串的字符不匹配了,那么主串的字符:“I”,就是坏字符,而模式串的字符串:“MPLE ”,这个字符串我们叫好后缀。
开心,现在我们都明白什么是坏字符和好后缀了。下面我就先给大家介绍什么是坏字符规则。其实,我们所说的规则都是在模式匹配失败的时候,计算我们模式串需要移动的距离,这样我们才可以在一个新的位置重新进行模式匹配,在坏字符规则下,模式串移动有两种情况:
- 坏字符没出现在模式串中,这时可以把模式串移动到坏字符的下一个字符,继续比较,如下图:
- 坏字符出现在模式串中,这时可以把模式串最右边第一个出现的坏字符和主串的坏字符对齐,当然,这样可能造成模式串倒退移动(这个情况的出现也是我们需要好后缀规则的一个原因),如下图:
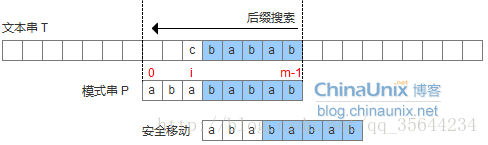
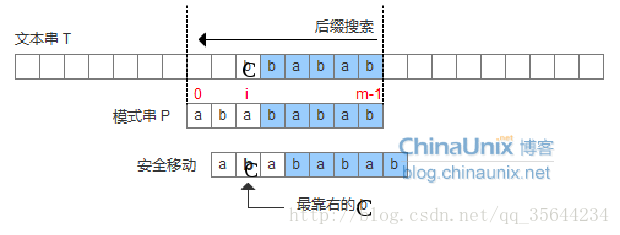
好了,到这里我们可以先用代码把坏字符规则实现,其实,我们先按照ASCII编码的规则,来实现我们的坏字符,因为,我们从上面的两种情况可以知道,其实如果某个字符不在模式串中,那么这个时候,模式串需要往右移动距离为模式串的长度,所以我们可以声明一个大小为256的数组,记录每个ASCII值在字符不匹配时,坏字符时该ASCII值时,模式串需要移动的距离。
/*//Bc函数的实现,因为我们是按照ASCII编码规则进行代码设计的,所以我们开始就申请256个空间
// 第一个for循环处理上述的第一种情况,这种情况比较容易理解就不多提了。
// 第二个for循环,Bc_table[s[j]中s[i]表示模式串中的第i个字符。
// Bc_table[s[j]]=len-j-1;也就是计算s[i]这个字符到串尾部的距离。
// 为什么第二个for循环中,i从小到大的顺序计算呢?哈哈,技巧就在这儿了,原因在于就可以在同一字符多次出现的时候以最靠右的那个字符到尾部距离为最终的距离。当然了,如果没在模式串中出现的字符,其距离就是len了。
*/
void Bc(char * s,int * Bc_table)
{
int len=strlen(s);
int i=0;
for(i=0;i<256;i++)
{
*(Bc_table+i)=len; //先把映射表的距离全部初始化为模式串的长度
}
int j=0;
for(j=0;j<len-1;++j)
{
Bc_table[s[j]]=len-j-1;//记录模式串中,每个字符最靠右那个字符的位置
}
}下面,我们再看看什么是好后缀规则,好的后缀规则同样是会有三种情况出现:
- 模式串中有子串匹配上好后缀,此时移动模式串,让该子串和好后缀对齐即可,如果超过一个子串匹配上好后缀,则选择最靠左边的子串对齐。
- 模式串中没有子串匹配上后后缀,此时需要寻找模式串的一个最长前缀,并让该前缀等于好后缀的后缀,寻找到该前缀后,让该前缀和好后缀对齐即可。
- 模式串中没有子串匹配上后后缀,并且在模式串中找不到最长前缀,让该前缀等于好后缀的后缀。此时,直接移动模式到好后缀的下一个字符。

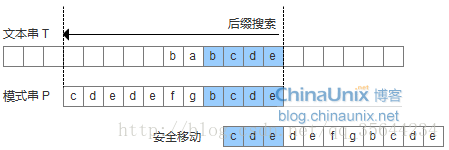
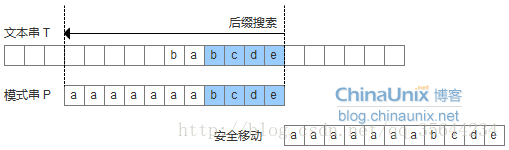
通过,上述的三种情况,为了实现好后缀规则,需要定义一个数组suffix[],其中suffix[i] = reslut 表示以i为边界,与模式串后缀匹配的最大长度,如下图所示,用公式可以描述:满足P[i-s, i] == P[len-result, len]的最大长度reslut。记住:我们需要匹配的是模式串的后缀表达式,所以每次得到了模式串某个位置的最长后缀表达式的长度之后,下一个位置又是和我们的模式串的最后一个字符开始比较。
下面就是我们得到suffix数组的函数
void get_suffix(char * s,int * suffix)
{
int i=0;
int j=0;
int k=0;
int result;
int len=strlen(s); //模式串的长度
suffix[len-1]=len; //模式串最后一个字符是一个特例,它是一个完全模式串后缀,所以长度就是模式串的长度
for(i=len-2;i>=0;--i) //从模式串的倒数第二个字符开始循环,求suffix的值
{
k=i; //我们想要寻找的那个子串的第一个字符
j=len-1; //模式串的最后一个字符
result=0; //记录那个子串的长度
while(s[k--]==s[j--]) //开始往前比较
{
++result;
}
suffix[i]=result; //得到最大模式串的后缀的长度
}
}
好了,现在有了suffix,我们就要开始进行我们的好后缀规则的实现了,其实,它同样是得到一个数组,这个数组记录每次我们遇到了不匹配字符时,在该字符所在的位置上,以好后缀的规则,模式串需要移动的距离。在生成这个距离的时候,我们我们同样是要对好后缀可能出现的三种情况进行考虑,
模式串中没有子串匹配上好后缀,但找不到一个最大前缀
这个时候,模式串需要移动的距离就是模式串的长度,这也是我们默认的移动距离,所以,程序一开始就可以把数组初始化为模式串的长度模式串中没有子串匹配上好后缀,但找到一个最大前缀
模式串中有子串匹配上好后缀
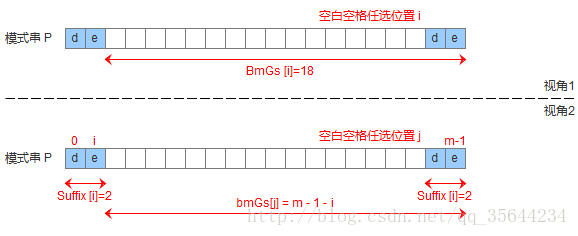
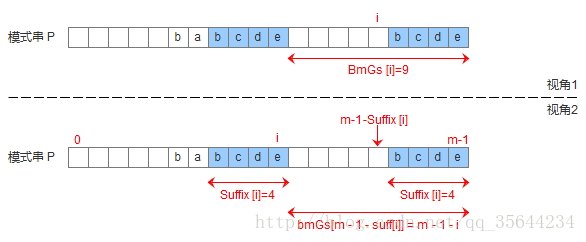
通过,这里分析的三种情况,我们可以编写出如下代码:
//Gs映射表的求解函数,
void Gs(char *s ,int * Gs_table)
{
int len= strlen(s);
int i;
int * suffix=new int[len];
//生成suffix数组
get_suffix(s,suffix);
for(i=0;i<len;i++)
{
Gs_table[i]=len; //先把所有的移动距离初始化为模式串的长度
}
int j=0;
//第二种情况
for(i=len-2;i>=0;--i)
{
if(suffix[i]==i+1)//x[i+1-suff[i]…i]==x[m-1-siff[i]…m-1],而suff[i]==i+1,我们知道x[i+1-suff[i]…i]=x[0,i],也就是前缀,满足第二种情况。
{
for(;j<len-1-i;++j) //
{
if(Gs_table[j]==len)//保证只被修改一次
{
Gs_table[j]=len-1-i;
}
}
}
}
for(i=0;i<=len-2;++i) //对应于第三种情况,结合着前面图来理解代码
Gs_table[len-1-suffix[i]]=len-1-i;
}
在这里,仔细去分析和感受一下,Gs函数的编写是有很多技巧在里面的,首先我们要先有个概念就是:当我们按照好后缀规则移动的时候,如果模式串的一个字符位置同时符合刚刚分析的三种情况中的几种,所以我们要选择其中移动距离最小的那一种,这样才可以保证不会出现匹配遗漏,通过分析,我们发现上述的三种情况中,其中第一种情况的移动距离最大,所以最先考虑,第二种为第二,第三种移动距离最小。
我们先是假设模式串每个字符都是符合第一种情况,就是没有最大前缀也没有匹配的模式串后缀,其实就是把整个数组初始化为模式串的长度。然后,我们再考虑第二种情况,我们从下面几个问题来分析第二种情况
1. 为什么从后往前,也就是i从大到小?
原因在于如果i,j(i>j)位置同时满足第二种情况,那么m-1-i
int BM(char * s,char * t)
{
int i=0;
int j=0;
int length_s=strlen(s); //主串的长度
int length_t=strlen(t); //模式串的长度
int * B=new int[256];
int * G=new int[length_t];
Bc(t,B);
Gs(t,G);
while(j<=length_s-length_t)
{
for(i=length_t-1;i>=0 && s[i+j]==t[i];--i);//往前匹配
if(i<0)
{
return j+1;
}
else
{
int g=G[i];
int b=B[s[i+j]]-length_t+1+i;
//选择最大的值
if(g>=b)
j+=g;
else
j+=b;
}
}
return 0;
}
好了,到现在,BM算法实现完成。
6、总结
哎哎,本来昨晚就写好的了,但是今天由于CSDN的bug,让我的博客变的不完整,从BM算法那里,我又重新写了一遍,算是因祸得福吧,通过这次的编写,我发现我对BM算法的原理更加明清了,打算,去看看原论文,看看是不是和我的理解一样。
参考博客:
http://www.cnblogs.com/xubenben/p/3359364.html
论文下载:
http://www.cs.utexas.edu/users/moore/publications/fstrpos.pdf














 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









