







二叉排序树的介绍
二叉排序树为一颗二叉树,或者为空,或者满足如下条件:
- 如果它的左子树不为空,那么左子树上的所有结点的值均小于它的根结点的值
- 如果它的右子树不为空,那么右子树上的左右结点的值均大于它的根结点的值
- 根结点的左子树和右子树又是二叉排序树。
二叉排序树通常采用二叉链表作为存储结构。中序遍历二叉排序树便可得到一个有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程即是对无序序列进行排序的过程。
二叉排序树的操作
我们对二叉排序的操作有三种:
- 查找
- 插入
- 删除
其中二叉排序树是一个动态树表,其特点就是树的结构不是一次生成的,而是在查找过程中,如果关键字不在树表中,在把关键字插入到树表中。而对于删除操作,它分为三种情况:
1. 删除结点为叶子结点(左右子树均为NULL),所以我们可以直接删除该结点,如下图所示:
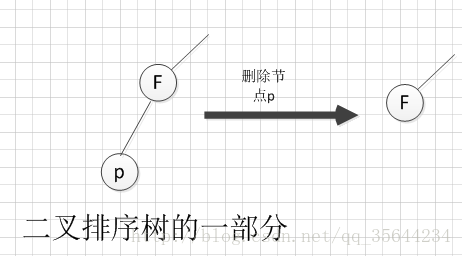
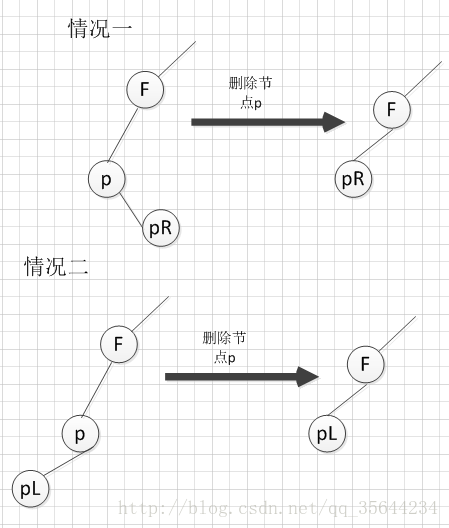
2. 删除结点只有左子树或者右子树,此时只需要让其左子树或者右子树直接替代删除结点的位置,称为删除结点的双亲的孩子,就可以了,如下图所示:
3. 当要删除的那个结点,其左右子树都存在的情况下,则要从从左子树中找出一个最大的值那个结点来替换我们需要删除的结点,如下图所示:
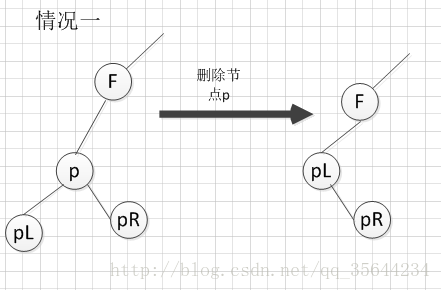
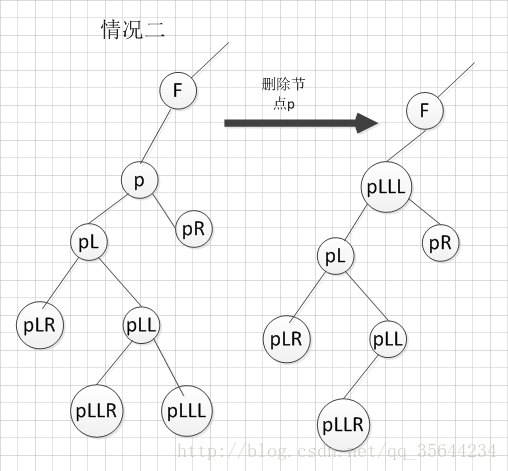
代码实现
“`
include
using namespace std;
//节点结构
struct Node {
int data;
Node * left;
Node * right;
};
/**
* 查找函数,成功返回true,失败返回false
*/
bool SearchBST(Node * T, int key,Node * & p) {
//如果二叉树为空,则直接返回false
if (!T) {
p = NULL;
return false;
}
//遍历整个二叉树,如果找到对应的结点,那就返回true
while (T) {
p = T;
if (key == T->data) {//相等,则说明找到了对应的关键字
return true;
}
else if (key > T->data) {//如果关键字比较大,往右子树查找
T = T->right;
}
else if (key < T->data) {//如果关键字比较小,则往左子树查找
T = T->left;
}
}
//如果到了这里,说明没有查找成功
return false;
}
/**
* 创建二叉排序树函数
*/
bool create_Tree(Node * & tree, int n) {
Node * p;
if (!SearchBST(tree, n , p)) {
Node * s = new Node;
s->data = n;
s->right = s->left = NULL;
if (!p) { tree = s; } //说明当前二叉排序树为空
else if (p->data > n) {
p->left = s; //最后一个结点的值大于关键字的值,新插入的为结点的左子树
}
else {//否则为右子树
p->right = s;
}
return true;
}
//这个说明关键已经在二叉排序树中了
return false;
}
/**
* 删除二叉排序树节点的函数
*/
bool Delete(Node * & T) {
Node * q;
if (!T->right) { //如果右子树为空,直接接上其左子树
q = T;
T = T->left;
delete q;
}
else if (!T->left) {//如果左子树为空,直接接上其右子树
q = T;
T = T->right;
delete q;
}
else {//如果左右子树都不为空
q = T;
Node * s = T->left; //从左子树往下找,找出左子树下最底层的右子树
//我们这里开始找出左子树中最靠右的那个结点,其实该结点就是左子树
//中值最大的结点。q记录的是该结点的前驱
while (s->right) {
q = s;
s = s->right;
}
//
T->data = s->data;
//如果需要删除的结点的左子树的右孩子不为空,既是q!=T,
if (q != T) {
q->right = s->left;
}
else {//否则,就直接接上其左孩子即可(这里可以画图看看,就明白了)
q->left = s->left;
}
delete s;
}
return true;
}
bool deleteBST(Node * & T, int key) { //删除关键字结点
if (!T) { return false; } //树为空,直接返回
while (T) {//遍历二叉树,找到需要删除的结点
if (T->data == key) {//找到了,调用Delete函数
return Delete(T);
}//如果关键字比较小,则往左子树比较
else if (T->data > key) {
T = T->left;
}
else {//如果关键字比较大,则往右子树比较
T = T->right;
}
}
//关键字不存在
return false;
}
//前序遍历二叉树
void PreOrderTraverse(Node * tree) {
if (tree) {
cout << tree->data << ” “;//访问根结点
PreOrderTraverse(tree->left); //遍历左子树
PreOrderTraverse(tree->right); //遍历右子树
}
}
//中序遍历二叉树
void MidOrderTraverse(Node * tree) {
if (tree) {
MidOrderTraverse(tree->left); //遍历左子树
cout << tree->data << ” “;//访问根结点
MidOrderTraverse(tree->right); //遍历右子树
}
}
//后序遍历二叉树
void LastOrderTraverse(Node * tree) {
if (tree) {
LastOrderTraverse(tree->left); //遍历左子树
LastOrderTraverse(tree->right); //遍历右子树
cout << tree->data << ” “;//访问根结点
}
}
/**
* 销毁二叉排序树函数
*/
void destory(Node * & tree) {
Node *p;
if (tree) {
destory(tree->left);
destory(tree->right);
delete tree;
}
}
int main() {
int n;
cout << “输入表的序列的个数” << endl;
cin >> n;
//建立二叉排序树
//头结点
int temp;
Node * tree_head = NULL;
cout << "输入无序的序列" << endl;
for (int i = 0; i < n; ++i) {
cin >> temp;
create_Tree(tree_head, temp);
}
cout << "二叉排序树的前序遍历:" << endl;
PreOrderTraverse(tree_head);
cout << endl;
cout << "二叉排序树的中序遍历:" << endl;
MidOrderTraverse(tree_head);
cout << endl;
cout << "二叉排序树的后序遍历:" << endl;
LastOrderTraverse(tree_head);
cout << endl;
cout << "需要查找的关键字" << endl;
int key;
cin >> key;
Node * p;
if (SearchBST(tree_head, key, p)) {
cout << "查找成功" << endl;
cout << p->data << endl;
}
else {
cout << "查找失败" << endl;
}
cout << "输入需要删除的关键字" << endl;
cin >> key;
if (deleteBST(tree_head, key)) {
cout << "删除后的二叉排序树的前序遍历为:" << endl;
PreOrderTraverse(tree_head);
cout << endl;
cout << "删除后的二叉排序树的中序遍历为:" << endl;
MidOrderTraverse(tree_head);
cout << endl;
cout << "删除后的二叉排序树的后序遍历为:" << endl;
LastOrderTraverse(tree_head);
cout << endl;
}
else {
cout << "删除失败" << endl;
}
//释放空间
destory(tree_head);
system("pause");
return 0;
}
二叉排序树的查找分析
使用二叉排序树进行查找,最好的情况是二叉排序树的形态和折半查找的判定树相同,其平均查找长度和logn成正比(O(log2(n)))。最坏情况下,当先后插入的关键字有序时,构成的二叉排序树为一棵斜树,树的深度为n,其平均查找长度为(n + 1) / 2。也就是时间复杂度为O(n),等同于顺序查找。因此,如果希望对一个集合按二叉排序树查找,最好是要对排序树进行一些必要的优化,如下:
- 加权平衡树(WBT)
- AVL树 (平衡二叉树)
- 红黑树
- Treap(Tree+Heap)
这些均可以使查找树的高度为 :O(log(n))。














 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









