









读取一个班的成绩的最高分及对应学号
#include <stdio.h>
#define N 30void FindMax(int score[],long num[],int n,int *pMaxScore,long *pMaxNum);
void FindMax(int score[],long num[],int n,int *pMaxScore,long *pMaxNum) //读取最高分及其对应的学号
{
int i;
*pMaxScore = score[0]; //假设第一个为最高分,并指向指针
*pMaxNum = num[0]; //记录第一个人的学号
for(i = 1;i < n;i++)
{
if(score[i] > *pMaxScore) //判断是否大于当前值
{
*pMaxScore = score[i]; //修改指针指向地址
*pMaxNum = num[i]; //修改指向学号的地址
}
}
}
int main()
{
int score[N],maxScore;
int n,i;
long num[N],maxNum;
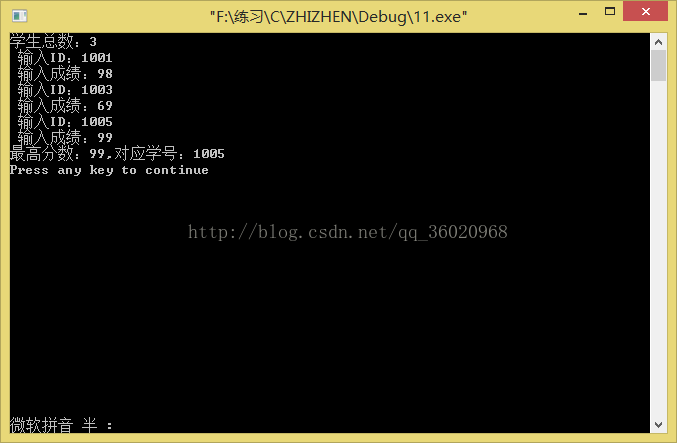
printf("学生总数:");
scanf("%d",&n); //读取学生总数
for(i = 0;i < n;i++)
{
printf(" 输入ID:"); //录入成绩和学号
scanf("%ld",&num[i]);
printf(" 输入成绩:");
scanf("%d",&score[i]);
}
FindMax(score,num,n,&maxScore,&maxNum);
printf("最高分数:%d,对应学号:%ld\n",maxScore,maxNum);
return 0;
}














 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









