







最近在学习和实践自然语言处理相关的知识,在这个文档从头到尾做个总结,防止自己忘记,也提供给新人来参考。本教程英文处理使用的是NLTK这个Python库,中文处理使用的是jieba这个Python库,主要是看July7月学习NLP视频学习而来,如有侵权,立即删除。Natural Language Processing(NLP)自然语言处理主要是处理以及理解自然语言的计算过程。整个自然语言处理的大致流程入下图所示:
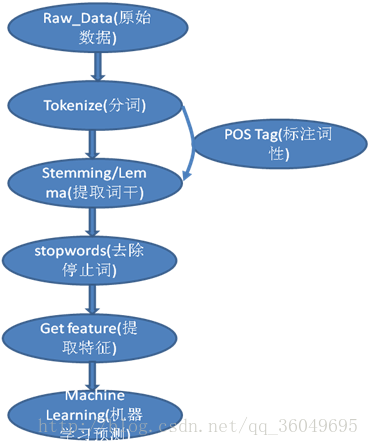
图1:自然语言处理流程
一、自然语言处理流程
第一步:Tokenize——分词,分词是将一个句子分成很多个单词,用一个word list存起来。如:
英文:How are you today? 会分成 [“How”,”are”,”you”,”today”,”?”]
中文:今天心情很好。 会分成[“今天”,”心情”,”很”,”好”,”。”]
第二步: Stemming/Lemma——提取词干,是将英文的过去式,名词形式,复数形式全部转换为最原始单词。如:
apples => apple, went => go, watched => watch, watching => watch
第三步:stopwords ——去除停止词,去掉单词列表中的停止词the,a等单词。如:
英文: The school is beautiful. => [“school”,”beautiful”],去掉了the,is等单词。
有时会用到POS Tag —— 标注词性,即标注出单词是动词/名词/形容词/副词等。
第四步:Get feature —— 提取特征,这个步骤的意思是用一个什么样的向量来表示这单词或者句子。如使用TF-IDF来表示一个单词:
TF:Term Frequecy:衡量一个单词在文档中出现的次数
TF(term) = (term出现在文档中的次数)/(文档中单词的总数)
IDF:Inverse Document Frequecy,衡量一个单词的重要性
IDF(term) = loge(文档总数/含有term的文档总数)
如果一个单词在所有文档中都出现了,则IDF(term) = 0,表明这个单词不重要。
TF-IDF = TF * IDF
对每个单词进行统计和计算,就可以得到每个单词的TF-IDF的值,用这个值来代替这个单词,整个句子就变成了一个浮点数的List。
当然这个是最简单的模型,这个模型有很多缺陷,现在流行的word2vect和fasttext,都是由google实习生写出来的,这两个模型生成的分布式向量可以有效的表达出两个单词之间的关系,这个在后续再做介绍。
第五步:Machine Learning——机器学习,机器学习是表示得到特征向量之后,能根据训练集合来预测需要测试集合。这个部分也在后续再做专门的介绍。
二、自然语言处理入门软件安装以及常见问题
整个实验环境是在VMWare+Ubuntu 16.04 LTS下完成的,最好是能翻墙,我用的翻墙软件是LoCo加速器。
NLTK 安装
安装pip
安装pip,一个python第三方软件的库,apt-get是获得软件或者库
sudo apt-get install python-pip python-dev build-essential
问题1,可能会碰到的问题: install的时候碰到Could not get lock /var/lib/dpkg/lock,无法Install
解决方案:找到哪个线程锁住了这个资源,然后Kill掉,指令:
sudo lsof /var/lib/dpkg/lock
sudo kill -9 (get from lsof output)
更新pip这个库
sudo pip install –upgrade pip
安装nltk库,用于自然语言处理。
sudo pip install -U nltk
安装numpy库
sudo pip install -U numpy
下载nltk所有相关东西(语料库,模型等)
python
import nltk
nltk.download(‘all’)
Python Debug使用
import pdb
在需要断点的地方 pdb.set_trace()
h Help
q Quit
p Print
Pp Prettyprint
w Where+stack trace 执行到了什么地方
l 断点前后的代码
n 执行下一句
b 35 在第35行断点
变量名称 打印出变量的值是多少
c continue until break
s step inside
使用VIM做IDE,可能需要配置和Python相关的信息,在.vrmrc中进行配置,第一次需要新建这个文件,如果需要添加插件,则先在.vimrc中进行配置,然后使用vim,输入:PluginInstall来在Vim上安装指定插件。
问题2:运行pandas.test报错:
运行numpy.test()或者pandas.test()出现如下错误
ImportError: Need nose >= 1.0.0 for tests - see http://somethingaboutorange.com/mrl/projects/nose
需要先安装nose,sudo pip install nose
问题3:pandas 从0.19.0开始不再支持pandas.io.wb,改用pandas_datareader,这个python库需要先行下载,sudo pip install pandas_datareader
Starting in 0.19.0, pandas will no longer support pandas.io.data or pandas.io.wb, so you must replace your imports from pandas.io with those from pandas_datareader:
from pandas.io import data, wb # becomes
from pandas_datareader import data, wb
Many functions from the data module have been included in the top level API.
import pandas_datareader as pdr
pdr.get_data_yahoo(‘AAPL’)
问题4:使用matplotlibc出现错误
ImportError: No module named _tkinter, please install the python-tk package
需要安装python-tk安装包
sudo apt-get install python-tk
问题5:vim添加Python支持
1、Ctrl+Alt+T 打开命令终端,输入: vim –version |grep python 查看vim是否支持python我这个vim只支持python3,不支持python。
2、安装py2包,在命令终端下输入: sudo apt-get install vim-nox-py2。
3、可以再次用vim –version|grep python 查看此时vim是否支持python,若支持到此为止,若不支持,请执行第四步。
4、在命令终端输入:sudo update-alternatives –config vim
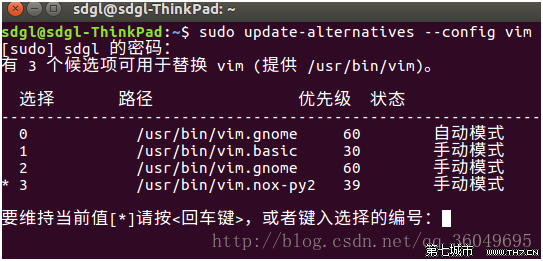
我这里是第三项属于python,第二项属于python3,想打开哪一项支持就输入它的编号就可以了(0,1,2,3)。
其他资料的使用:
matplotlin画图软件,画二维图可以使用这个工具,功能和matlab画图类似 sudo pip install matplotlib,结合pandas使用
API使用文档:
http://matplotlib.org/1.5.3/users/beginner.html
pandas-datareader:从yahoo Finance,google API 上下载相关信息,具体使用API如下
https://pandas-datareader.readthedocs.io/en/latest/
python一些常见库的入门指导材料,可以加快学习的速度:
https://pythonprogramming.net/
美国金融方面的数据,房价/股票等信息,已经格式化好了,容易处理的数据:
https://www.quandl.com/
pandas入门资料:
http://pandas.pydata.org/pandas-docs/stable/10min.html
三、自然语言处理实践
实践的题目是Kaggle上的一道竞赛题目,
链接:https://www.kaggle.com/c/home-depot-product-search-relevance, Home Depot是美国一家网上卖五金的公司,在用户输入修洗脸盆的时候,希望能提供给用户所有洗脸盆需要的五金和工具。
给出了五组数据:
产品属性:
“product_uid”,”name”,”value”
100001,”Bullet01”,”Versatile connector for various 90° connections and home repair projects”
产品描述:
“product_uid”,”product_description”
100001,”Not only do angles make joints stronger, they also provide more consistent, straight corners. Simpson Strong-Tie offers a wide variety of angles in various sizes and thicknesses to handle light-duty jobs or projects where a structural connection is needed. Some can be bent (skewed) to match the project. For outdoor projects or those where moisture is present, use our ZMAX zinc-coated connectors, which provide extra resistance against corrosion (look for a “”Z”” at the end of the model number).Versatile connector for various 90 connections and home repair projectsStronger than angled nailing or screw fastening aloneHelp ensure joints are consistently straight and strongDimensions: 3 in. x 3 in. x 1-1/2 in.Made from 12-Gauge steelGalvanized for extra corrosion resistanceInstall with 10d common nails or #9 x 1-1/2 in. Strong-Drive SD screws”
测试集:
“id”,”product_uid”,”product_title”,”search_term”
1,100001,”Simpson Strong-Tie 12-Gauge Angle”,”90 degree bracket”
训练集合:
“id”,”product_uid”,”product_title”,”search_term”,”relevance”
2,100001,”Simpson Strong-Tie 12-Gauge Angle”,”angle bracket”,3
提交的样本:
“id”,”relevance”
1,1
Relevance是表示选出工具和输入搜索关键词之间的相关性,相关性=3表示非常相关,相关性=1表示不太相关。
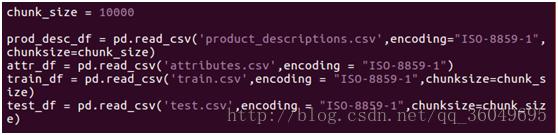
第一步:数据清洗
用pandas读取csv中的数据,因为数据过大,没法一次读取出来进行处理,每次处理10000条,处理完1次就放到另外一个csv文件中存储起来。
处理的过程是将英文用nltk的stemming方法对每个单词进行提取词干。
只有第一次写入csv文件的时候需要写入header,且不需要index。Header表示表头。
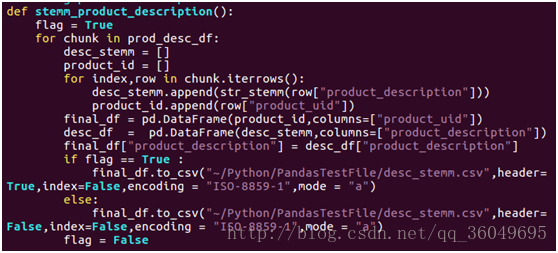
处理完成之后产品描述变成如下的样子,训练数据和测试数据类似处理:
product_uid,product_description
100001,”not onli do angl make joint stronger, they also provid more consi stent, straight corners. simpson strong-ti offer a wide varieti of angl i n various size and thick to handl light-duti job or project where a struc tur connect is needed. some can be bent (skewed) to match the project. fo r outdoor project or those where moistur is present, use our zmax zinc-co at connectors, which provid extra resist against corros (look for a “”z”” at the end of the model number).versatil connector for various 90 connec t and home repair projectsstrong than angl nail or screw fasten alonehelp ensur joint are consist straight and strongdimensions: 3 in. x 3 in. x 1 -1/2 in.mad from 12-gaug steelgalvan for extra corros resistanceinstal wi th 10d common nail or #9 x 1-1/2 in. strong-driv sd screw”
注意事项:
使用chunk_size进行分块读入
使用iterrows 一行一行读入数据
使用final_df[“column”] = A新增加一列,A可以是一个list
to_csv的header设置来表示是否需要表格头
注意编码是ISO-8859-1
第二步:提取特征
假设使用搜索关键词在产品名字和产品描述中出现的最大次数来表示这个搜索关键词的两个主要特征,搜索关键词的长度表示另外一个特征。
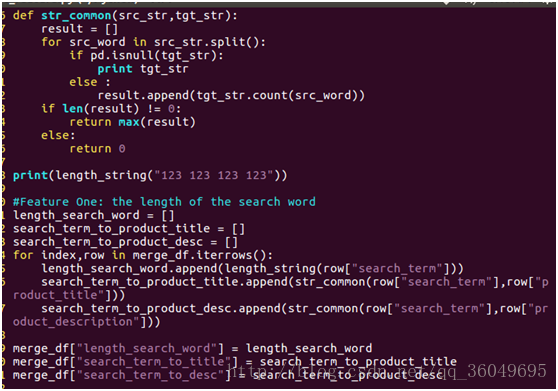
注意事项:
数据连接之后可能会出现NaN的字符,Python会默认为float类型的无穷大,需要通过pd.isnull(a)来判断下是否为空。
第三步:使用机器学习来预测,加博士是用的随机森林来进行relevance的预测,后续章节会继续深入讨论。
未完,待续。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









