







Spark SQL
是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame,并且作为分布式SQL查询引擎的作用
什么是DataFrames??
与RDD类似,DataFrames也是一个分布式数据容器;然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema;
同时与Hive类似,DataFrame也支持嵌套数据类型(struct,array,map).
创建DataFrames 代码分享:
1.DSL风格语法
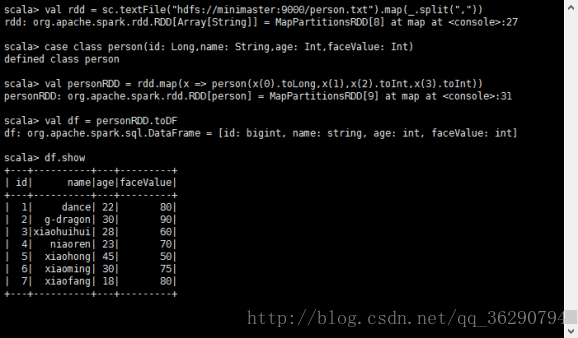
val rdd = sc.textFile(“hdfs://minimaster:9000/person.txt”).map(_.split(“,”))
case class person(id: Long,name: String,age: Int,faceValue: Int)
personRDD = rdd.map(x => person(x(0).toLong,x(1),x(2).toInt,x(3).toInt))
val df = personRDD.toDF
df.show()
df.select(“name”,”age”).show
hadoop高可用下通过Spark集群运行过程:
2.SQL风格语法
如果想使用SQL风格的语法,需要将DataFrame注册成表
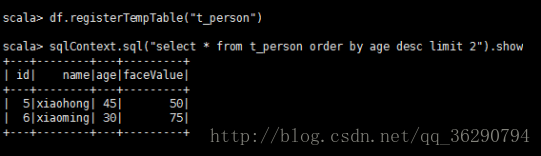
df.registerTempTable(“t_person”)
sqlContext.sql(“select * from t_person order by age desc limit 2”).show
//显示表信息
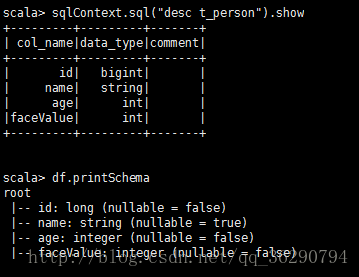
sqlContext.sql(“desc t_person”).show
==
df.printSchema
3.以编码方式执行Spark SQL 查询
package com.qianfeng.day07
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 通过反射推断Schema
*/
object InferSchema {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("InferSchema").setMaster("local[2]")
val sc = new SparkContext(conf)
val sqlContext: SQLContext = new SQLContext(sc)
//获取数据
val linesRDD: RDD[Array[String]] = sc.textFile("hdfs://minimaster:9000/person.txt").map(_.split(","))
//将linesRDD和Person关联
val personRDD: RDD[Person] = linesRDD.map(p => Person(p(0).toInt,p(1),p(2).toInt,p(3).toInt))
//调用toDF方法需要引入隐式转换函数
import sqlContext.implicits._
//将RDD转换成DataFrame
val personDF: DataFrame = personRDD.toDF()
//注册成二维表
personDF.registerTempTable("t_person")
val sql = "select name,age,fv from t_person where age > 20 order by fv asc limit 5"
//调用sqlContext实例并传入SQL,,最终得到结果
val res: DataFrame = sqlContext.sql(sql)
//保存数据HDFS
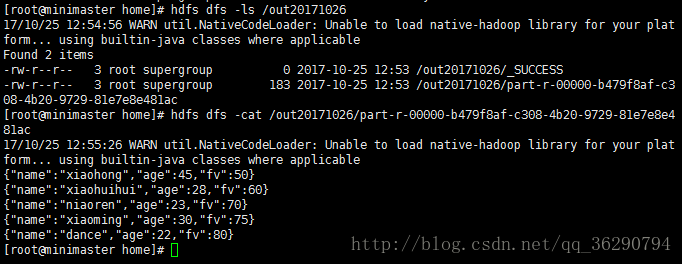
res.write.mode("append").json("hdfs://minimaster:9000/out20171026")
}
}
case class Person(id: Int,name:String,age: Int,fv: Int){}
在IDEA中成功运行后
去掉./setMaster(“local[2]”)
打成jar包至Linux的/home目录上运行
/usr/local/spark-1.6.1/bin/spark-submit \
–class com.qianfeng.day07.InferSchema \
–master spark://minimaster:7077 \
–executor-memory 1G \
–total-executor-cores 2 \
/home/wc.jar














 5764
5764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









