一、爬虫基础知识
1.什么是爬虫
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。
比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,整个连在一起的大网对这之蜘蛛来说触手可及,分分钟爬下来不是事儿。
2.浏览网页的过程
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。
因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
3.URL的含义
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。
②第二部分是存有该资源的主机IP地址(有时也包括端口号)。
③第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
4. 环境的配置
学习Python,当然少不了环境的配置,最初我用的是Notepad++,不过发现它的提示功能实在是太弱了,于是,在Windows下我用了PyCharm,在Linux下我用了Eclipse for Python,另外还有几款比较优秀的IDE,大家可以参考这篇文章 学习Python推荐的IDE 。好的开发工具是前进的推进器,希望大家可以找到适合自己的IDE
我感觉ipython也不错
二、urllib 详解 我会看一些官方的函数,例子与内容,也会参考一些博文
High-level interface
urllib.urlopen方法
Open a network object denoted by a URL for reading.[通过一个url 打开一个网页 => 为了我们读取 ]
urllib.urlopen
(
url
[
,
data
[
,
proxies
[
,
context
]
]
]
) #第一个是必要参数,后面两个作为小白应该还暂时用不到吧,用到了会提的
包含方法read(),readline(),readlines(),fileno(), close(),info(),getcode()和geturl()
》》》
import
urllib2
response=urllib2.urlopen("http://www.baidu.com")
print response.read()
>>> 全网页代码
print response.readline()
>>> <!DOCTYPE html>
print response.geturl()
>>> http://www.baidu.com
print response.info()
>>> Transfer-Encoding: chunked
Bdpagetype: 1
Bdqid: 0xfbe41dac0006db24
Bduserid: 0
Cache-Control: private
Content-Type: text/html; charset=utf-8
Cxy_all: baidu+68eb70140c74e2f54978f891c4820c44
Date: Sun, 06 Aug 2017 06:50:49 GMT
Expires: Sun, 06 Aug 2017 06:49:50 GMT
Keep-Alive: timeout=38
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Set-Cookie: BAIDUID=9946D7F4F25C31A8035C5758F56B1F6C:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=9946D7F4F25C31A8035C5758F56B1F6C; expires=Thu, 31-Dec-37 23:55:55 GMT; max- age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1502002249; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=0; path=/
Set-Cookie: H_PS_PSSID=1458_21106_22075; path=/; domain=.baidu.com
Vary: Accept-Encoding
X-Powered-By: HPHP
X-Ua-Compatible: IE=Edge,chrome=1
urllib.urlretrieve
将由URL表示的网络对象复制到本地文件
urllib.urlretrieve
(
url
[
,
filename
[
,
reporthook
[
,
data
]
]
]
)
注意点1:第三个参数(如果存在)是一个钩子函数,在建立网络连接后将被调用一次,并且在每个块读取之后一次。
钩子将被传递三个参数; 到目前为止传输的块数,块大小(以字节为单位)以及文件的总大小。第三个参数可能是-1在旧的FTP服务器上,不响应检索请求返回文件大小;
注意点2:默认的请求方式是get,可以指定可选数据参数来制定post请求
》》》import urllib
url='http://www.baidu.com'
local='E://url.html'
urllib.urlretrieve()
>>> 在E盘出现文件
下面通过例子来演示一下这个方法的使用,这个例子将 google 的 html 抓取到本地,保存在 D:/google.html 文件中,同时显示下载的进度。 本例参考 点击打开链接
08 | per = 100.0 * a * b / c |
15 | urllib.urlretrieve(url, local, cbk) |
urllib.urlcleanup
Utility functions
urllib.quote方法
quote
(
string
[
,
safe
]
)
使用转义替换
字符串
中的特殊字符%xx。
使用:特殊字符是指tap,space,/,:等等。safe参数代表你写的这个参数是安全的,也就意味着这些特殊字符不会被替换。默认的safe特殊字符是“/”
注意:默认情况下,此功能用于引用URL的路径部分
用途:
将url数据获取之后,并将其编码,从而适用与URL字符串中,使其能被打印和被web服务器接受,或者一些api中。
使用
这是一个好习惯。
》》》import urllib
url='http://www.baidu.com'
print quote(url)
http%3A//www.baidu.com
urllib.quote_plus
官方解释【翻译之后会改变原意就直接贴出来了】:
Like
quote()
, but also replaces spaces by plus signs, as required for quoting HTML form values when building up a query string to go into a URL. Plus signs in the original string are es caped unless they are included in
safe
. It also does not have
safe
default to
'/'
.
这个功能比quote多一些,具体使用看情况。
PS:具体使用和quote类似,不过默认的safe字符是space,他会将space转换为“+”
urllib.unquote
unquote(string)与unquote相反!)
PS:如果你编码之后,接受的时候要解码才能看的懂,就是这个意思!
》》》 url='http://www.baidu.com'
eurl=quote(url)
durl=unquote(eurl)
print eurl,durl
http%3A//www.baidu.com
http://www.baidu.com
urllib.unquote_plus
unquote_plus(string)
PS:与quote_plus相反
urllib.urlencode
urlencode
(
query
[
,
doseq
]
)
用法:把键值对转化成能识别的形式,python中有这样的数据类型
urllib.urldecode
Example
GET
>>> import urllib
>>> params = urllib.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
>>> f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query?%s" % params)
>>> print f.read()
>>> import urllib
>>> params = urllib.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
>>> f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query", params)
>>> print f.read()
>>> import urllib
>>> proxies = {'http': 'http://proxy.example.com:8080/'}
>>> opener = urllib.FancyURLopener(proxies)
>>> f = opener.open("http://www.python.org")
>>> f.read()
>>> import urllib
>>> opener = urllib.FancyURLopener({})
>>> f = opener.open("http://www.python.org/")
>>> f.read()
当然这里的代理是稍微高级的一些用法了
三、urllib2 详解 urllib和urllib2不可以相互代替,有人说urllib2更加易读,也许吧
urllib提供urlencode方法用来
encode 然后才能 发送data;但是urllib2可以接受request类的实例,但是urllib只可以接受url的对象,这也是为什么二者经常在一起使用!!!!
所以我们得了解response能相比与之前能多做哪些事情
1、可以向服务器发送数据data;urllib2不发送数据时,使用的时GET,在发送数据的时候使用的时POST,此时需要的data以标准的encode方式,然后作为一个数据参数传给request对象。为什么需要传送数据?因为假如你要扒某注册网站,你不传数据进去,难道他把所有人的姓名,密码打印出来?那还不如不爬。。
import urllib
import urllib2
url = 'http://www.someserver.com/cgi-bin/register.cgi'
values = {}
values['name'] = 'Michael Foord'
values['location'] = 'Northampton'
values['language'] = 'Python'
data = urllib.urlencode(values) #数据进行编码
req = urllib2.Request(url,data) #作为data参数传递到Request对象中
response = urllib2.urlopen(req)
the_page = response.read()
print the_page
2、可以向服务器发送额外的信息(metadata),这些信息被当作HTTP头发送:Header可以通过Request提供的 . add_header() 方法进行添加
要加入 header,需要使用 Request 对象:
import urllib2
request = urllib2.Request(uri)
request.add_header('User-Agent', 'fake-client')
response = urllib2.urlopen(request)
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。常见的取值有:
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
urllib2.urlopen方法
urlopen
(
url [,data [,timeout [,cafile [,capath [,cadefault [,context]]]]]
)
参数:
可选的data;数据可以是指定要发送到服务器的附加数据的字符串,或者 None不需要这样的数据。目前HTTP请求是唯一使用数据的请求; 当提供数据参数时,HTTP请求将是POST而不是GET 。数据应该是标准应用程序的缓冲区 / x-www-form-urlencoded 格式
可选的timeout参数指定阻塞操作(如连接尝试)的超时(如果未指定,将使用全局默认超时设置)
用法:打开URL
url
,它可以是一个字符串或一个
Request
对象,具体使用和urllib差不多
附加方法:
geturl()
- 返回检索的资源的URL,通常用于确定是否遵循重定向
info()
- 以
mimetools.Message
实例的形式返回页面的元信息(如标题)(请参阅
HTTP头快速参考
)
getcode()
- 返回响应的HTTP状态代码。
urllib2.Requst类
参数:
可选的data;数据可以是指定要发送到服务器的附加数据的字符串,或者 None不需要这样的数据。目前HTTP请求是唯一使用数据的请求; 当提供数据参数时,HTTP请求将是POST而不是GET 。数据应该是标准应用程序的缓冲区 / x-www-form-urlencoded 格式
可选的headers参数 应该是字典,并且将被视为add_header() 被调用的每个键和值作为参数, User-Agent浏览器用于标识自身的标头值 - 一些HTTP服务器只允许来自常见浏览器的请求而不是脚本。这也是为了防止,网站被爬虫扒爆了 。
。
用法:打开URL
url
,它可以是一个字符串或一个
Request
对象,具体使用和urllib差不多
最后两个参数仅用于正确处理第三方HTTP Cookie
下面我将列出所有的request类中的方法:
Request.add_data(data):增加一个data,看例子
url = "http://passport.csdn.net/account/login"
request = urllib2.Request( url)
request.add_data(data)
相似与
url = "http://passport.csdn.net/account/login"
request = urllib2.Request(url,data)
Request.get_method():返回是POST请求,还是GET请求
Request.has_data()
: 返回这个Request对象实例是否具有data
Request.get_data():返回这个实例的data,注意GET方式相当于没有data,POST有data
Request.add_header(key, val):添加一个header,具体的header到底用来干什么我下面会讲
Request.add_unredirected_header(key, header)
Request.has_header(header):判断是有拥有header,具体的header有什么作用我后面会讲
Request.get_full_url():获取URL的全部路径
Request.get_type():获取url的类型,比如http,ftp或者其他
Request.get_host():返回连接的主机,如本地主机+端口号 127.0.0.1:64998
Request.get_selector():返回选择器 - 发送到服务器的URL部分
Request.get_header(header_name, default=None):获取到header信息。。
Request.header_items():返回请求标头的元组列表(header_name,header_value),这个还是相当重要的。
例子:
[('Content-length', '46'), ('Content-type', 'application/x-www-form-urlencoded'),
('Host', 'passport.csdn.net'), ('User-agent', 'Python-urllib/2.7')]
Request.set_proxy(host, type):设置代理 ,后面会讲作用
Request.get_origin_req_host():返回原始事务的请求主机
Request.is_unverifiable()
在上面我说了,要用urllib2的原因是因为request类,他可以满足两个作用,一个是增加data,另一个是可以设置header,相比大家经过上面的函数分析已经了解了data的作用和使用,下面来讲讲header是什么东西。
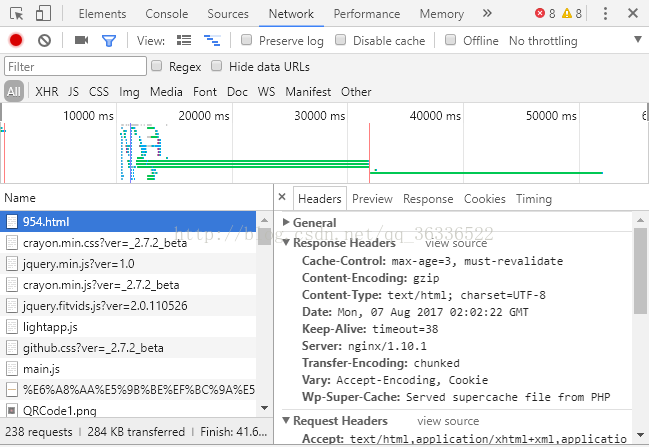
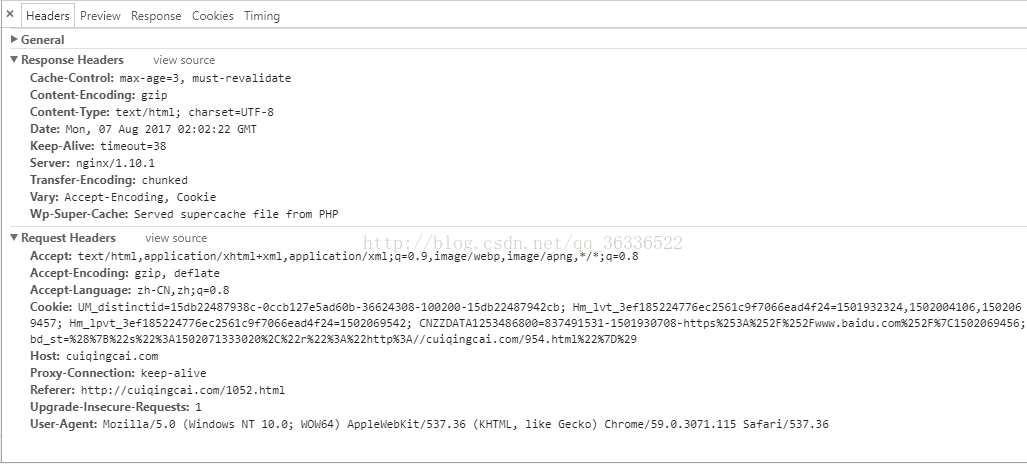
请大家随便打开一个网页,按下F12或者右击-->检查。
看到最上面一行的network,请您
打开network,下面看到Headers了吗,上面还有response,cookies,timing这几项,这些都是我们爬虫用的到的,你点击Headers,下面我讲Headers信息列出来了
大家看一下这里的Request Headers 里面的内容,和我们学的request方法是不是有些类似。
设置Header
请大家往上面看我写的第三大点Urllib2详解 下面的第二小点,下面列举了我们的headers可以包含哪些内容,我这里再列举一遍:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求;这个是用户身份,大家看我上面截的图->request Headers里面也有User-Agent,有时候没有这个用户验证,可以扒不出来,所以需要设置一下header
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
import urllib
import urllib2
url = 'http://www.server.com/login'
user_agent = 'Mozilla/5.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read() #这里知识举个例子,形式
另外,我们还有对付”反盗链”的方式,对付防盗链,服务器会识别headers中的referer是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在headers中加入referer
例如我们可以构建下面的headers
headers = { 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' ,
'Referer':'http://www.zhihu.com/articles' }
设置timeout
这个比较简单urllib2.urlopen('http://www.baidu.com',timeout=10)
设置HTTP的传送方式
http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
import urllib2
request = urllib2.Request(uri, data=data)
request.get_method = lambda: 'PUT' # or 'DELETE'
response = urllib2.urlopen(request)
设置Proxy
urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在捣鬼了。
设置方法:
import urllib2
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({"http" : 'http://some-proxy.com:8080'})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
urllib2.build_opener方法
参数:([ handler,... ] )
用法:build_opener ()返回的对象具有open()方法,与urlopen()函数的功能相同。
使用原因:urllib2.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。要支持这些功能,必须使用build_opener()函数创建自定义Opener对象。
class
urllib2.
OpenerDirector
-
The OpenerDirector class opens URLs via BaseHandlers chained together. It manages the chaining of handlers, and recovery from errors.
class
urllib2.
BaseHandler
-
This is the base class for all registered handlers — and handles only the simple mechanics of registration.
class
urllib2.
HTTPDefaultErrorHandler
-
A class which defines a default handler for HTTP error responses; all responses are turned into HTTPError exceptions.
class
urllib2.
HTTPRedirectHandler
-
A class to handle redirections.
class
urllib2.
HTTPCookieProcessor
(
[
cookiejar
]
)
-
A class to handle HTTP Cookies.
class
urllib2.
ProxyHandler
(
[
proxies
]
)
-
Cause requests to go through a proxy. If proxies is given, it must be a dictionary mapping protocol names to URLs of proxies. The default is to read the list of proxies from the environment variables <protocol>_proxy. If no proxy environment variables are set, then in a Windows environment proxy settings are obtained from the registry’s Internet Settings section, and in a Mac OS X environment proxy information is retrieved from the OS X System Configuration Framework.
To disable autodetected proxy pass an empty dictionary.
Note
HTTP_PROXY will be ignored if a variable REQUEST_METHOD is set; see the documentation on getproxies().
class
urllib2.
HTTPPasswordMgr
-
Keep a database of (realm, uri) -> (user, password) mappings.
class
urllib2.
HTTPPasswordMgrWithDefaultRealm
-
Keep a database of (realm, uri) -> (user, password) mappings. A realm of None is considered a catch-all realm, which is searched if no other realm fits.
class
urllib2.
AbstractBasicAuthHandler
(
[
password_mgr
]
)
-
This is a mixin class that helps with HTTP authentication, both to the remote host and to a proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
HTTPBasicAuthHandler
(
[
password_mgr
]
)
-
Handle authentication with the remote host. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
ProxyBasicAuthHandler
(
[
password_mgr
]
)
-
Handle authentication with the proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
AbstractDigestAuthHandler
(
[
password_mgr
]
)
-
This is a mixin class that helps with HTTP authentication, both to the remote host and to a proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
HTTPDigestAuthHandler
(
[
password_mgr
]
)
-
Handle authentication with the remote host. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
ProxyDigestAuthHandler
(
[
password_mgr
]
)
-
Handle authentication with the proxy. password_mgr, if given, should be something that is compatible with HTTPPasswordMgr; refer to section HTTPPasswordMgr Objects for information on the interface that must be supported.
class
urllib2.
HTTPHandler
-
A class to handle opening of HTTP URLs.
class
urllib2.
HTTPSHandler
(
[
debuglevel
[,
context
]
]
)
-
A class to handle opening of HTTPS URLs. context has the same meaning as for httplib.HTTPSConnection.
Changed in version 2.7.9: context added.
class
urllib2.
FileHandler
-
Open local files.
class
urllib2.
FTPHandler
-
Open FTP URLs.
class
urllib2.
CacheFTPHandler
-
Open FTP URLs, keeping a cache of open FTP connections to minimize delays.
class
urllib2.
UnknownHandler
-
A catch-all class to handle unknown URLs.
class
urllib2.
HTTPErrorProcessor
-
Process HTTP error responses.
urllib2.URLError方法
exception
urllib2.
HTTPError
方法
异常处理我们后面再聊






















 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









