










论文解读:Dialogue Generation: From Imitation Learning to Inverse Reinforcement Learning
对话生成是一个常见的自然语言处理任务,其在工业界广泛应用与智能客服,闲聊机器人等。现如今主要研究于如何提高对话的质量,多样性。本文则采用先进的技术试图解决这个问题。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | DG-AIRL |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 对话生成 |
| 4 | 核心内容 | Dialogue Generation,Imitation Learning, Inverse Reinforcement Learning, Adversarial Imitation Learning |
| 5 | GitHub源码 | - |
| 6 | 论文PDF | https://arxiv.org/pdf/1812.03509 |
二、全文摘要翻译
基于对抗学习的对话生成方法的性能依赖于判别器的奖励信号的质量,如果判别器不佳,则提供的奖励通常是稀疏的或不稳定,因此导致生成器容易陷入局部最优,或生成一些无含义的回复。为了缓解第一个问题,我们首先将最近提出的对抗对话生成方法拓展到对抗模仿学习方法,其次在对抗逆强化学习的框架基础上,我们提出一种新的奖励模型用于对话生成,使得判别器可以为生成器提供更加精确的奖励信号。我们评估我们的方法,使用自动评估和人工评估方法。实验表明我们的方法可以很好的生成高质量的恢复,并超越了先前的方法。
三、对话生成任务
对话生成任务是指给定一个对话,返回对应的恢复。对话生成是一种特殊的文本生成任务。其不同于机器翻译、生成摘要、问答系统等,通常并没有非常显式的评价来判断生成的文本是否合理。例如当对话为“What’s your name?”,通常回复是千篇一律。因此目前解决对话生成任务可以分为两大类:

(1)通过设计一个规则或模板来生成具有约束的回复,这一类方法通常是无需学习的。但其会受到具体的业务限制,且并不灵活。
(2)另一类则是基于深度学习的方法,利用类似机器翻译的Seq2Seq的架构,输入一个句子,通过对模型进行学习生成对应的回复。然而这一类方法通常生成的句子语法或逻辑不符。
为了解决普通的Seq2Seq的问题,现如今有工作利用强化学习或对抗学习进行文本生成,如图所示:

第一类是深度强化学习,其主要思想是通过人工定义一种奖励函数来为每一个对话进行打分。通常这类奖励函数并不能很好的适应开放领域的对话,使得对话系统容易生成类似“I don’t know”等这一类回复。通常认为这一类回复是毫无意义的;另一类则是使用对抗生成网络进行学习,其主要思路是利用生成器来生成句子,企图骗过判别器来获得较高的得分;判别器则尽可能区分哪些是来自真实的分布,哪些是生成器生成的文本。然而生成对抗网络经常遭受训练不稳定等问题。
基于上述的问题作为研究的动机,本文的主要贡献有:
- A novel reward model architecture to evaluate the reward of each word in a dialog,
which enables us to have more accurate signal for adversarial dialogue training; - A novel Seq2Seq model, DG-AIRL, for addressing the task of dialogue generation built
on adversarial inverse reinforcement learning; - An improvement of the training stability of adversarial training by employing causal
entropy regularization;
四、模仿学习
模仿学习是一种新的基于强化学习的方法(强化学习的相关定义及方法请阅读博文:强化学习)。给定一个专家数据,假设这个专家数据是完全正确的,因此我们认为专家数据中每一个文本都拥有最高的奖励。然后我们并不知道这个奖励函数,因此我们需要直接或间接的学习奖励函数,然后基于奖励函数来学习策略。
模仿学习主要有三种方法:

(1)行为克隆(Behavior Clone):行为克隆是指在给定的一组专家数据,直接使用一个模型来分别学习,这即是传统的监督学习方法,即输入一个文本及对应的标签(回复),通过梯度下降方法学习模型的参数。行为克隆虽然简单,但通常许多应用领域内遭受数据缺失的问题,使得模型并不能充分的学习;
(2)逆强化学习(Inverse Reinforcement Learning):给定一个专家数据,逆强化学习的目标是首先学习潜在未知的reward function,而这个reward function一定是能够给专家数据高分。在寻找到这个reward function之后,再使用强化学习的方法通过不断的采样来学习策略;
(3)生成对抗模仿学习(Generative adversarial imitation learning):其结合了对抗学习的方法。将策略使用生成器来学习,将reward function使用判别器来学习,这样可以不需要显式的指导reward function,且每一轮迭代学习均可以不断的调整reward function以及策略。
下面主要介绍后两个方法:
4.1 最大熵逆强化学习
最大熵逆强化学习(MaxEnt-IRL)是最经典的逆强化学习方法。给定一个专家数据(轨迹)
D
d
e
m
o
=
{
ζ
1
,
ζ
2
,
.
.
.
,
ζ
N
}
D_{demo} = \{\zeta_1, \zeta_2, ..., \zeta_N\}
Ddemo={ζ1,ζ2,...,ζN}
其中 ζ i \zeta_i ζi 表示一个轨迹,在本任务中可以认为是一个句子配对(对话)。因此如何寻找一个reward function使得这些轨迹可以得到尽可能大的分数?我们使用如下公式来定量判断每一个轨迹出现的概率:
p ( ζ i ∣ θ ) = 1 Z ( θ ) e x p r θ ( ζ i ) = 1 Z ( θ ) e x p ∑ t = 1 ∣ ζ i ∣ − 1 r θ ( s t , a t ) p(\zeta_i|\theta) = \frac{1}{Z(\theta)}exp^{r_{\theta}(\zeta_i)} = \frac{1}{Z(\theta)}exp^{\sum_{t=1}^{|\zeta_i|-1}}r_{\theta}(s_t,a_t) p(ζi∣θ)=Z(θ)1exprθ(ζi)=Z(θ)1exp∑t=1∣ζi∣−1rθ(st,at)
其中 Z ( θ ) = ∫ e x p ( r θ ( ζ ) ) d ζ Z(\theta) = \int exp(r_{\theta}(\zeta))d\zeta Z(θ)=∫exp(rθ(ζ))dζ 是归一化因子。我们可知,如果轨迹的reward越高,其理应出现的概率越大,换句话说,如果专家数据中,某些轨迹出现的越频繁,则其对应的reward function也应该更大。因此如何能够获得对应的reward function?可知最能想到的就是参数估计方法——最大似然估计,因此对上式进行log运算,即:
L ( θ ) = − E ζ ∼ D d e m o r θ ( ζ ) + l o g Z ( θ ) L(\theta) = -\mathbb{E}_{\zeta\sim D_{demo}}r_{\theta}(\zeta) + logZ(\theta) L(θ)=−Eζ∼Ddemorθ(ζ)+logZ(θ)
然而 Z ( θ ) = ∫ e x p ( r θ ( ζ ) ) d ζ Z(\theta) = \int exp(r_{\theta}(\zeta))d\zeta Z(θ)=∫exp(rθ(ζ))dζ 很难对齐求导,因此MaxEnt-IRL利用一种重要度采样方法,通过另一个采样分布对其进行采样:
L ( θ ) = − E ζ ∼ p r θ ( ζ ) + l o g ∫ e x p ( r θ ( ζ j ) ) d ζ L(\theta) = -\mathbb{E}_{\zeta\sim p}r_{\theta}(\zeta) + log\int exp(r_{\theta}(\zeta_j))d\zeta L(θ)=−Eζ∼prθ(ζ)+log∫exp(rθ(ζj))dζ
L ( θ ) = − E ζ ∼ p r θ ( ζ ) + l o g ∫ e x p ( r θ ( ζ j ) ) q ( ζ j ) 1 q ( ζ j ) d ζ L(\theta) = -\mathbb{E}_{\zeta\sim p}r_{\theta}(\zeta) + log\int exp(r_{\theta}(\zeta_j))q(\zeta_j)\frac{1}{q(\zeta_j)}d\zeta L(θ)=−Eζ∼prθ(ζ)+log∫exp(rθ(ζj))q(ζj)q(ζj)1dζ
L ( θ ) = − E ζ ∼ p r θ ( ζ ) + l o g [ E ζ j ∼ q ( e x p ( r θ ( ζ j ) ) q ( ζ j ) ) ] L(\theta) = -\mathbb{E}_{\zeta\sim p}r_{\theta}(\zeta) + log [\mathbb{E}_{\zeta_j\sim q}(\frac{exp(r_{\theta}(\zeta_j))}{q(\zeta_j)})] L(θ)=−Eζ∼prθ(ζ)+log[Eζj∼q(q(ζj)exp(rθ(ζj)))]
4.2 生成对抗模仿学习
生成对抗网络(GAN)主要包括生成器和判别器,生成器用于生成样本,判别器则用于判别生成的样本有多好。而生成对抗模仿学习则是利用生成对抗网络的特性来学习奖励函数。生成对抗网络如下图所示,GAN的详细讲解详见:生成对抗网络(GAN)之 Basic Theory 学习笔记
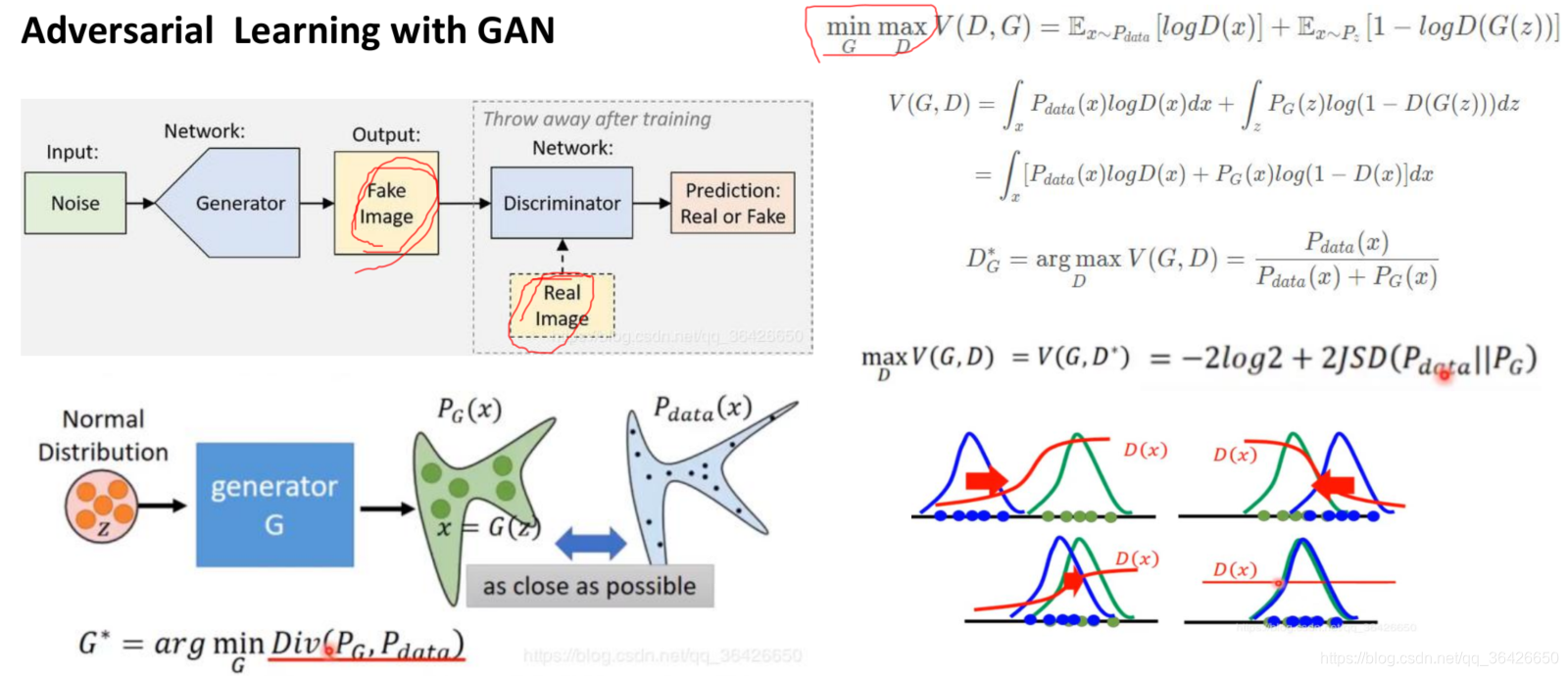
在生成对抗模仿学习中,生成器相当于策略,判别器相当于奖励函数。首先是训练判别器,根据当前已训练好的生成器(策略)最大化真实经验数据的得分,最小化生成器生成样本的得分;在训练生成器时,固定判别器,此时生成器(策略)最大化判别器所给的分数。
本文中,作者引入causal entropy来描述策略的优劣,一方面可以直接通过判别器的得分作为损失函数,而causal entropy则可以通过信息的不确定下来描述策略的性能。causal entropy公式如下:
H ( π ) = E π [ − l o g π ( a ∣ s ) ] H(\pi) = E_{\pi}[-log\pi(a|s)] H(π)=Eπ[−logπ(a∣s)]
因此对抗模仿学习的两个训练过程可以描述为如下公式:
max r ∈ R ( min π ∈ Π − λ H ( π ) − E π [ r ( s , a ) ] ) + E π E [ r ( s , a ) ] \max_{r\in R}(\min_{\pi\in\Pi} -\lambda H(\pi) - E_{\pi}[r(s,a)]) + E_{\pi_{E}}[r(s,a)] r∈Rmax(π∈Πmin−λH(π)−Eπ[r(s,a)])+EπE[r(s,a)]
= min π ∈ Π [ − l o g ( D ( s , a ) ) ] + E π E [ − l o g ( 1 − D ( s , a ) ) ] − λ H ( π ) =\min_{\pi\in\Pi}[-log(D(s, a))] + E_{\pi_{E}}[-log(1-D(s, a))] - \lambda H(\pi) =π∈Πmin[−log(D(s,a))]+EπE[−log(1−D(s,a))]−λH(π)
4.3 对抗模仿学习用于对话生成
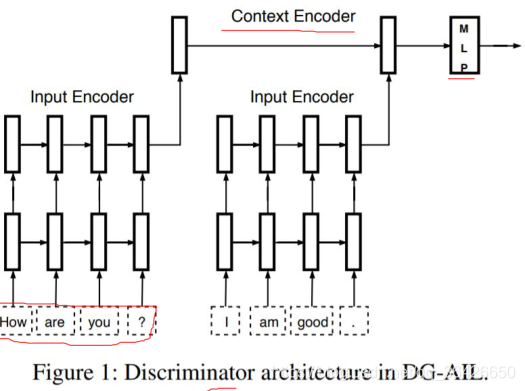
如上图,是判别器结构,主要用于判断给定的两个句子得分,其中Input Encoder和Context Encoder部分均为GRU单元。生成器和判别器的梯度更新如下图所示:
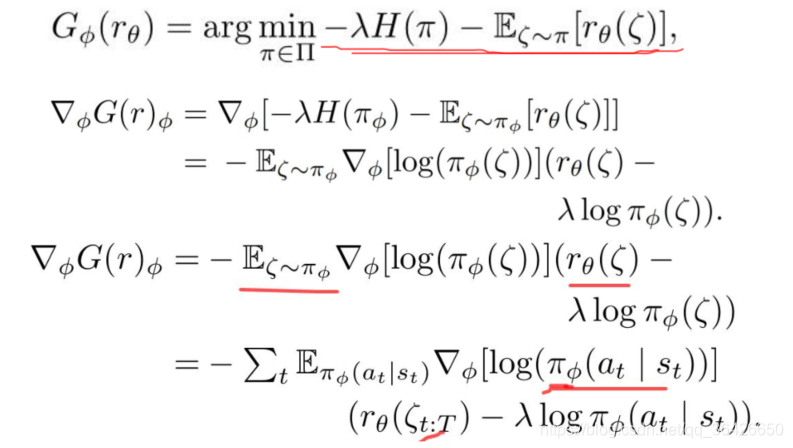
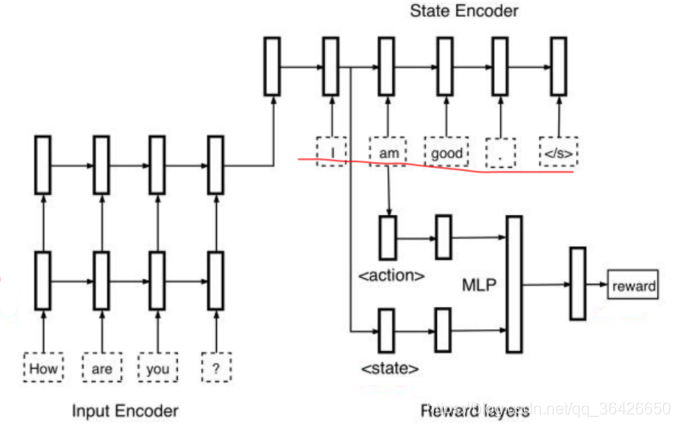
判别器(奖励函数)的梯度更新如下:
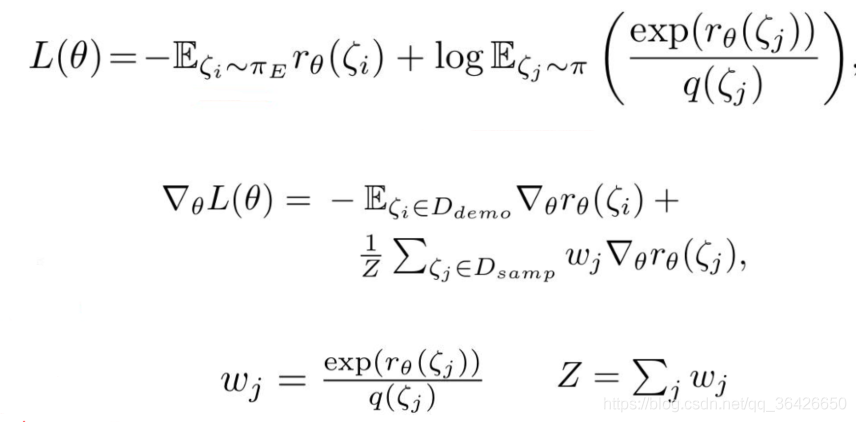















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











