







- Apply Locally:本地操作,所有操作应用在本地节点数据上,不会产生网络传输
- Repartitioning:数据流重定向,单纯的改变数据流向,不会改变数据内容,这部分会有网络传输
- Aggragation:聚合操作,会有网络传输
- Grouped streams上的操作
- Merge和Join
- 定义一个Function:
public class MyFunction extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for ( int i = 0; i < tuple.getInteger(0); i++) {
collector.emit( new Values(i));
}
}
}- 比如我们处理一个“mystream”的数据流,它有三个字段分别是[“a”, “b”, “c”] ,数据流中tuple的内容是:
- 我们运行我们的Function:
java mystream.each(new Fields("b"), new MyFunction(), new Fields("d")));- 最终运行结果会是每个tuple有四个字段[“a”, “b”, “c”, “d”],每个tuple的内容变成了:
- Filters很简单,接收一个tuple并决定是否保留这个tuple。举个例子,定义一个Filter:
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(0) == 1 && tuple.getInteger(1) == 2;
}
}- 假设我们的tuples有这个几个字段 [“a”, “b”, “c”]:
- 然后运行我们的Filter:
java mystream.each(new Fields("b", "a"), new MyFilter());- 则最终得到的tuple是 :
- 定义一个累加的PartitionAggregate:
java mystream.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"));- 假设我们的Stream包含两个字段 [“a”, “b”],各个Partition的tuple内容是:
Partition 1: [“a”, 3] [“c”, 8]
- 输出的内容只有一个字段“sum”,值是:
Partition 1: [11]
public interface CombinerAggregator <T> extends Serializable {
T init(TridentTuple tuple);
T combine(T val1, T val2);
T zero();
}- 定义一个CombinerAggregator实现来计数:
public class CombinerCount implements CombinerAggregator<Integer>{
@Override
public Integer init(TridentTuple tuple) {
return 1;
}
@Override
public Integer combine(Integer val1, Integer val2) {
return val1 + val2;
}
@Override
public Integer zero() {
return 0;
}
} public interface ReducerAggregator <T> extends Serializable {
T init();
T reduce(T curr, TridentTuple tuple);
}- 定义一个ReducerAggregator接口实现技术器的例子:
public class ReducerCount implements ReducerAggregator<Long>{
@Override
public Long init() {
return 0L;
}
@Override
public Long reduce(Long curr, TridentTuple tuple) {
return curr + 1;
}
}最后一个是Aggregator接口,它是最通用的聚合器,它的形式如下:
public interface Aggregator<T> extends Operation {
T init(Object batchId, TridentCollector collector);
void aggregate(T val, TridentTuple tuple, TridentCollector collector);
void complete(T val, TridentCollector collector);
}- init:在处理数据之前被调用,它的返回值会作为一个状态值传递给aggregate和complete方法
- aggregate:用来处理每一个输入的tuple,它可以更新状态值也可以发射tuple
- complete:当所有tuple都被处理完成后被调用
下面举例说明:
- 定义一个实现来完成一个计数器:
public class CountAgg extends BaseAggregator<CountState>{
static class CountState { long count = 0; }
@Override
public CountState init(Object batchId, TridentCollector collector) {
return new CountState();
}
@Override
public void aggregate(CountState val, TridentTuple tuple, TridentCollector collector) {
val. count+=1;
}
@Override
public void complete(CountState val, TridentCollector collector) {
collector.emit( new Values(val. count));
}
} 有时候我们需要同时执行多个聚合器,这在Trident中被称作chaining,使用方法如下:java mystream.chainedAgg() .partitionAggregate(new Count(), new Fields("count")) .partitionAggregate(new Fields("b"), new Sum(), new Fields("sum")) .chainEnd(); 这点代码会在每个Partition上运行count和sum函数,最终输出一个tuple:[“count”, “sum”]
projection:投影操作
投影操作作用是仅保留Stream指定字段的数据,比如有一个Stream包含如下字段: [“a”, “b”, “c”, “d”]
运行如下代码:
java mystream.project(new Fields("b", "d")) 则输出的流仅包含 [“b”, “d”]字段。
2.2 Repartitioning重定向操作
重定向操作是如何在各个任务间对tuples进行分区。分区的数量也有可能改变重定向的结果。重定向需要网络传输,下面介绍下重定向函数:
- shuffle:通过随机分配算法来均衡tuple到各个分区
- broadcast:每个tuple都被广播到所有的分区,这种方式在drcp时非常有用,比如在每个分区上做stateQuery
- partitionBy:根据指定的字段列表进行划分,具体做法是用指定字段列表的hash值对分区个数做取模运算,确保相同字段列表的数据被划分到同一个分区
- global:所有的tuple都被发送到一个分区,这个分区用来处理整个Stream
- batchGlobal:一个Batch中的所有tuple都被发送到同一个分区,不同的Batch会去往不同的分区
- Partition:通过一个自定义的分区函数来进行分区,这个自定义函数实现了 backtype.storm.grouping.CustomStreamGrouping
Trident有aggregate和 persistentAggregate方法来做聚合操作。aggregate是独立的运行在Stream的每个Batch上的,而persistentAggregate则是运行在Stream的所有Batch上并把运算结果存储在state source中。
运行aggregate方法做全局聚合。当你用到 ReducerAggregator或Aggregator时,Stream首先被重定向到一个分区中,然后其中的聚合函数便在这个分区上运行。当你用到CombinerAggregator时,Trident会首先在每个分区上做局部聚合,然后把局部聚合后的结果重定向到一个分区,因此使用CombinerAggregator会更高效,可能的话我们需要优先考虑使用它。
下面举个例子来说明如何用aggregate进行全局计数:
java mystream.aggregate(new Count(), new Fields("count"));2.4 grouped streams
GroupBy操作是根据特定的字段对流进行重定向的,还有,在一个分区内部,每个相同字段的tuple也会被Group到一起,下面这幅图描述了这个场景:
如果你在grouped Stream上面运行aggregators,聚合操作会运行在每个Group中而不是整个Batch。persistentAggregate也能运行在GroupedSteam上,不过结果会被保存在MapState中,其中的key便是分组的字段。
当然,aggregators在GroupedStreams上也可以串联。
2.5 Merge和Joins:
api的最后一部分便是如何把各种流汇聚到一起。最简单的方式就是把这些流汇聚成一个流。我们可以这么做:
java topology.merge(stream1, stream2, stream3);1. join的字段,如Stream1中的key和Stream2中的x
2. 所有非join的字段,根据传入join方法的顺序,a和b分别代表steam1的val1和val2,c代表Stream2的val1
当join的是来源于不同Spout的stream时,这些Spout在发射数据时需要同步,一个Batch所包含的tuple会来自各个Spout。
Trident是Storm中最为核心的概念,在做Strom开发的过程中,绝大部分情况下我们都会使用Trident,而不是使用传统的Spout、Bolt。Trident是Storm原语的高级封装,学会Trident之后,将会使得我们Storm开发变得非常简单。
一、什么是Storm Trident ?
简而言之:Trident是编写Storm Topology的一套高级框架,是对传统Spout、Bolt的高级封装。在学习Trident之前,我们都是都Spout、Bolt的相关API来编写一个Topology,在学习了Trident之后,我们会使用Trident API来编写Topology。
可以将StormTopology与TridentTopology的关系,类比为JDBC与ORM框架(mybatis、hibernate)之间的关系,后者是前者的高级封装,功能相同,但是可以极大的减少我们的开发的工作量。
当然,就像我们学习JDBC与ORM框架一样,JDBC可能很容易理解,但是学习ORM框架,可能就相对复杂一点。甚至学习ORM框架的时间可能要比学习JDBC的时间要更长,但是一旦我们学会了ORM框架,可能就再也不想去使用JDBC了,因为ORM框架可以帮助我们更高效的进行开发。
学习Trident也一样,可能我们学习理解许多新的概念,但是学会了会极大的提高我们的开发效率。
Storm原语中,最重要的就是Spout、Bolt、Grouping等概念。
Trident对于Storm原语的抽象主要也就是针对这些基本概念的抽象。主要体现在:Trident Spout,Operation、State 。
Trident Spout是针对Storm原语中的Spout进行的抽象
Operation是针对Bolt、Grouping等概念的抽象
State是新提出的概念,实际上就是数据持久化的接口。
通常情况下,新的概念意味着要使用新的API。但是归根结底,还是底层还是通过storm原语来实现。在Trident中,我们使用TridentTopology表示一个拓扑,而在Storm原语中,我们使用StormTopology来表示一个拓扑。TridentTopology最终会被转换成StormTopology。在接下来的内容,我们将首先介绍TridentTopology的构建过程,以及TridentTopology如何转化为StormTopology。
二、TridentTopology与StormToplogy
1、API区别:
在Trident中,有着新的一套构建Topology的API,我们先通过从代码层面上对比来进行分析:
StormTopology:由传统的Spout和Bolt的API编写的Topology,最终是通过TopologyBuilder对象来创建的,返回的结果就是StormTopology对象。
- StormTopologytopology= topologyBuilder.createTopology();
TridentTopology:由Trident的API编写的Topology,因为在Trident的API中,使用TridentTopology来表示一个Topology,是直接new出来的。
- TridentTopology tridentTopology = new TridentTopology();
单独提出这两个概念,是为了以后的区分。以后我们提到StormTopology时,表示的就是以Spout、Bolt等这些API创建的Topology,而提到TridentTopology表示的就是以Trident的API创建的Topology。
2、创建Topology的区别
我们以单词计数案例WordCountApp(超链接)进行对比
StormTopology
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout("word-reader" , new WordReader(),4);
- builder.setBolt("word-normalizer" , new WordNormalizer(),3).shuffleGrouping("word-reader" );
- builder.setBolt("word-counter" , new WordCounter(),1).fieldsGrouping("word-normalizer" , new Fields("word"));
- StormTopology topology = builder .createTopology();
TridentTopology:
- TridentTopology tridentTopology = new TridentTopology();
- tridentTopology.newStream("word-reader-stream" , new WordReader()).parallelismHint(16)
- .each( new Fields("line" ), new NormalizeFunction(), new Fields("word" ))
- .groupBy( new Fields("word" ))
- .persistentAggregate( new MemoryMapState.Factory(), new Sum(), new Fields("sum" ));
- StormTopology stormTopology = tridentTopology.build();
对比:
在StormTopology中,我们都是通过TopologyBuilder的setSpout、setBolt的方式来创建Topology,然后通过Grouping策略指定Bolt的数据来源和分组策略。
在TridentTopology中,我们使用TridentTopology来创建Topology,整个创建过程中,都是流式编程风格的。要注意的是,在Trident中,我们依然使用了WordReader这个Spout,但是并没有使用Bolt,而是使用了类似于each、persistentAggregate这样方法,来取代Bolt的功能。关于这些方法的作用再之后会详细介绍,目前只要知道Bolt的作用被一些方法取代了即可。
三、TridentTopology与StormToplogy的联系
二者的联系主要是:TridentTopology最终会被编译成StormTopology。请再次查看上述构建构建TridentTopology的最后一句代码。
- StormTopology stormTopology = tridentTopology.build();
这句代码的的返回结果还是StormTopology对象,这实际上意味着,TridentTopology最终还是会被编译成StandardTopology。这很容易理解,就像ORM框架与JDBC一样,ORM框架只是一层封装,最终还是要通过JDBC操作数据库。而TridentTopology是高级封装,但是最终还是要通过编译StormTopology来运行。
注意:这一点是非常重要的。上面我们已经提到,在Trident中,依然要指定Spout,但是用了一系列其他的方法如each、persistentAggregate等(当然不止这些),代替了Bolt的功能。那么这里又提到,TridentTopology会被编译成StormTopology,实际上就意味着Storm最终会将这些方法转换为一个或多个Bolt。我们要了解Trident是如何工作的,就必须要了解,这些方法的最终是如何被转换为Bolt的。最简单的查看方式,就是查看编译后的StormTopology的getSpout,getBolt方法来看。
在后面我们会详细介绍,TridentTopology是如何转换为StormTopology的。目前,我们只需要知道TridentTopology最终是会转换为StormTopology即可。
事实上,在Trident框架会将调用的所有方法转换为一个个Node。Node类型如下:
newStream方法中参数Spout转换为SpoutNode,将调用的each方法,persistentAggregate等方法,转换为一个个ProcesserNode,而groupBy等操作,转换为一个PartitionNode,最终组成一个对象图,最后根据这个对象图,来将TridentTopology转换为StormTopology。
-
当然,光说不练假把式,我们通过分析源码进行简单说明。
-
首先说明Spout转换为SpoutNode对象
-
其次说明each、persistentAggregate转换为ProcesserNode
-
最后说明如何根据SpoutNode和ProcesserNode将TridentTopology转换为StormTopology
1、Spout转换为SpoutNode
首先,我们看一下TridentTopology对象的newStream方法:

可以看到,可以接受五种类型的Spout,以下是这五个方法的实现:

我们可以看到,这五种方法,最终调用的实际上只有两个,并且在这两个方法中,最终都将Spout转换为了SpoutNode对象。
2、each、persistentAggregate转换为ProcessorNode
我们可以查看Stream对象的源码, 找到each、persistentAggregate两个方法内容

上图显示了这两个方法,这种都被转换为一个ProcessorNode,最终添加到Topology中。
3、最后我们看一下,TridentTopology.build()的实现
由于源码内容比较多,我们只分析感兴趣的地方,其中红色加深的地方,是目前最为关注的:
- public StormTopology build() {
- ...
- TridentTopologyBuilder builder = new TridentTopologyBuilder();
-
- Map<Node, String> spoutIds = genSpoutIds( spoutNodes);
- Map<Group, String> boltIds = genBoltIds( mergedGroups);
- // SpoutNode维护了Spout类型,根据类型转换为对应的Spout
- for(SpoutNode sn : spoutNodes ) {
- Integer parallelism = parallelisms.get(grouper .nodeGroup(sn));
- if(sn .type == SpoutNode.SpoutType.DRPC) {
- builder.setBatchPerTupleSpout(spoutIds .get(sn), sn.streamId ,
- (IRichSpout) sn. spout, parallelism , batchGroupMap.get(sn ));
- } else {
- ITridentSpout s;
- if(sn .spout instanceof IBatchSpout) {
- s = new BatchSpoutExecutor((IBatchSpout)sn .spout );
- } else if(sn .spout instanceof ITridentSpout) {
- s = (ITridentSpout) sn. spout;
- } else {
- throw new RuntimeException("Regular rich spouts not supported yet... try wrapping in a RichSpoutBatchExecutor");
- // TODO: handle regular rich spout without batches (need lots of updates to support this throughout)
- }
- builder.setSpout(spoutIds .get(sn), sn.streamId, sn. txId, s, parallelism , batchGroupMap .get(sn));
- }
- }
-
- for(Group g : mergedGroups ) {
- if(!isSpoutGroup( g)) {
- Integer p = parallelisms.get(g );
- Map<String, String> streamToGroup = getOutputStreamBatchGroups(g, batchGroupMap);
- //将调用each、processAggregate方法后的ProcessorNode,转换为Bolt
- BoltDeclarer d = builder.setBolt(boltIds .get(g), new SubtopologyBolt(graph, g .nodes , batchGroupMap ), p,
- committerBatches(g, batchGroupMap), streamToGroup);
- Collection<PartitionNode> inputs = uniquedSubscriptions(externalGroupInputs(g )); //根据调用GroupBy等方法转换成的PartitionNode进行Grouping策略
- for(PartitionNode n : inputs ) {
- Node parent = TridentUtils.getParent( graph, n );
- String componentId;
- if(parent instanceof SpoutNode) {
- componentId = spoutIds .get(parent);
- } else {
- componentId = boltIds.get(grouper .nodeGroup(parent));
- }
- d.grouping( new GlobalStreamId(componentId , n.streamId ), n.thriftGrouping);
- }
- }
- }
-
- return builder .buildTopology();
- }
一、认识storm trident
trident可以理解为storm批处理的高级抽象,提供了分组、分区、聚合、函数等操作,提供一致性和恰好一次处理的语义。
1)元祖被作为batch处理
2)每个batch的元祖都被指定唯一的一个事物id,如果因为处理失败导致batch重发,也和保证和重发前一样的事物id
3)数据更新操作严格有序,比如batch1必须在batch2之前被成功处理,且如果batch1失败了,后面的处理也会失败。
假如: batch1处理1--20
batch2处理21--40
batch1处理失败,那么batch2也会失败
虽然数据更新操作严格有序,但是数据处理阶段也可以并行的,只是最后的持久化操作必须有序。
1.1 trident state
trident的状态具有仅仅处理一次,持续聚合的语义,使用trident来实现恰好一次的语义不需要开发人员去处理事务相关的工作,因为trident state已经帮我们封装好了,只需要编写类似于如下的代码:
- topology.newStream("sentencestream", spout)
- .each(new Fields("sentence"), new Split(), new Fields("word"))
- .groupBy(new Fields("word"))
- .persistentAggregate(new MyHbaseState.HbaseFactory(options), new Count(), new Fields("count"))
- .parallelismHint(3);
所有处理事务逻辑都在MyHbaseState.HbaseFactory中处理了(这个是我自己定义的,trident支持在内存里面处理,类似于MemachedState.opaque)。
trident提供了一个StateFactory用来创建State对象的实例,行如:
- public final class XFactory implements StateFactory{
- public State makeState(Map conf,int partitonIndex,int numPartitions){
- return new State();
- }
- }
1.2 persistentAggregate
persistentAggregate是trident中用来更新来源的状态,如果前面是一个分好组的流,trident希望你提供的状态实现MapState接口,其中key是分组的字段,
而聚合结果是状态的值。
1.3 实现MapStates
trident中实现MapState非常简单,只需要为这个类提供一个IBackingMap的接口实现接口。
二、实战
首先搭建好zk,storm,hadoop,hbase的分布式环境
master:

slave1:

slave2:

main方法:
- public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, AuthorizationException {
- TridentTopology topology = new TridentTopology();
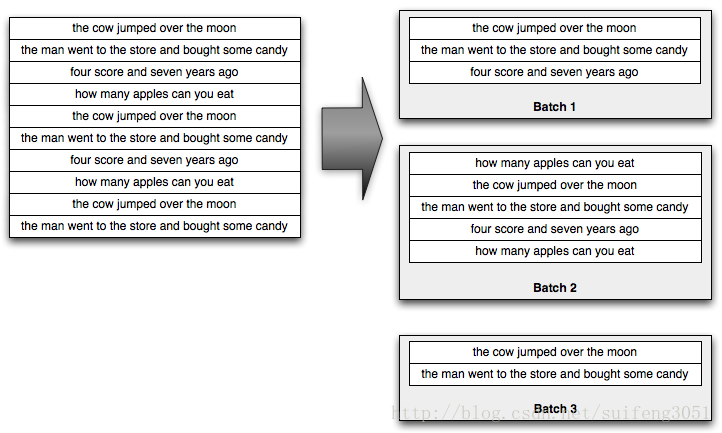
- FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
- new Values("tanjie is a good man"), new Values(
- "what is your name"), new Values("how old are you"),
- new Values("my name is tanjie"), new Values("i am 18"));
- spout.setCycle(false);
- tridentStreamToHbase(topology,spout);
- Config config = new Config();
- config.setDebug(false);
- StormSubmitter.submitTopologyWithProgressBar("word_count_trident_state_HbaseState", config, topology.build());
tridentStreamToHbase方法:
- private static TridentState tridentStreamToHbase(TridentTopology topology,
- FixedBatchSpout spout) {
- MyHbaseState.Options options = new MyHbaseState.Options();
- options.setTableName("storm_trident_state");
- options.setColumFamily("colum1");
- options.setQualifier("q1");
- /**
- * 根据数据源拆分单词后,然后分区操作,在每个分区上又进行分组(hash算法),然后在每个分组上进行聚合
- * 所以这里可能有多个分区,每个分区有多个分组,然后在多个分组上进行聚合
- * 用来进行group的字段会以key的形式存在于State当中,聚合后的结果会以value的形式存储在State当中
- */
- return topology.newStream("sentencestream", spout)
- .each(new Fields("sentence"), new Split(), new Fields("word"))
- .groupBy(new Fields("word"))
- .persistentAggregate(new MyHbaseState.HbaseFactory(options), new Count(), new Fields("count"))
- .parallelismHint(3);
- }
MyHbaseState实现:
- package com.storm.trident.state.hbase;
- import java.io.ByteArrayOutputStream;
- import java.io.IOException;
- import java.io.Serializable;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.Map;
- import org.apache.hadoop.hbase.HBaseConfiguration;
- import org.apache.hadoop.hbase.TableName;
- import org.apache.hadoop.hbase.client.Connection;
- import org.apache.hadoop.hbase.client.ConnectionFactory;
- import org.apache.hadoop.hbase.client.Get;
- import org.apache.hadoop.hbase.client.Put;
- import org.apache.hadoop.hbase.client.Result;
- import org.apache.hadoop.hbase.client.Table;
- import org.apache.storm.task.IMetricsContext;
- import org.apache.storm.trident.state.JSONNonTransactionalSerializer;
- import org.apache.storm.trident.state.JSONOpaqueSerializer;
- import org.apache.storm.trident.state.JSONTransactionalSerializer;
- import org.apache.storm.trident.state.Serializer;
- import org.apache.storm.trident.state.State;
- import org.apache.storm.trident.state.StateFactory;
- import org.apache.storm.trident.state.StateType;
- import org.apache.storm.trident.state.map.IBackingMap;
- import org.apache.storm.trident.state.map.MapState;
- import org.apache.storm.trident.state.map.OpaqueMap;
- import org.apache.storm.trident.state.map.SnapshottableMap;
- import org.apache.storm.tuple.Values;
- import com.google.common.collect.Maps;
- @SuppressWarnings({ "unchecked", "rawtypes" })
- public class MyHbaseState<T> implements IBackingMap<T> {
- private static final Map<StateType, Serializer> DEFAULT_SERIALZERS = Maps
- .newHashMap();
- private int partitionNum;
- private Options<T> options;
- private Serializer<T> serializer;
- private Connection connection;
- private Table table;
- static {
- DEFAULT_SERIALZERS.put(StateType.NON_TRANSACTIONAL,
- new JSONNonTransactionalSerializer());
- DEFAULT_SERIALZERS.put(StateType.TRANSACTIONAL,
- new JSONTransactionalSerializer());
- DEFAULT_SERIALZERS.put(StateType.OPAQUE, new JSONOpaqueSerializer());
- }
- public MyHbaseState(final Options<T> options, Map conf, int partitionNum) {
- this.options = options;
- this.serializer = options.serializer;
- this.partitionNum = partitionNum;
- try {
- connection = ConnectionFactory.createConnection(HBaseConfiguration
- .create());
- table = connection.getTable(TableName.valueOf(options.tableName));
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public static class Options<T> implements Serializable {
- /**
- *
- */
- private static final long serialVersionUID = 1L;
- public Serializer<T> serializer = null;
- public String globalkey = "$HBASE_STATE_GLOBAL$";
- /**
- * 表名
- */
- public String tableName;
- /**
- * 列族
- */
- public String columFamily;
- /**
- *
- */
- public String qualifier;
- public String getTableName() {
- return tableName;
- }
- public void setTableName(String tableName) {
- this.tableName = tableName;
- }
- public String getColumFamily() {
- return columFamily;
- }
- public void setColumFamily(String columFamily) {
- this.columFamily = columFamily;
- }
- public String getQualifier() {
- return qualifier;
- }
- public void setQualifier(String qualifier) {
- this.qualifier = qualifier;
- }
- }
- protected static class HbaseFactory<T> implements StateFactory {
- private static final long serialVersionUID = 1L;
- private Options<T> options;
- public HbaseFactory(Options<T> options) {
- this.options = options;
- if (this.options.serializer == null) {
- this.options.serializer = DEFAULT_SERIALZERS
- .get(StateType.OPAQUE);
- }
- }
- @Override
- public State makeState(Map conf, IMetricsContext metrics,
- int partitionIndex, int numPartitions) {
- System.out.println("partitionIndex:" + partitionIndex
- + ",numPartitions:" + numPartitions);
- IBackingMap state = new MyHbaseState(options, conf, partitionIndex);
- MapState mapState = OpaqueMap.build(state);
- return new SnapshottableMap(mapState, new Values(options.globalkey));
- }
- }
- @Override
- public void multiPut(List<List<Object>> keys, List<T> values) {
- List<Put> puts = new ArrayList<Put>(keys.size());
- for (int i = 0; i < keys.size(); i++) {
- Put put = new Put(toRowKey(keys.get(i)));
- T val = values.get(i);
- System.out.println("partitionIndex: " + this.partitionNum
- + ",key.get(i):" + keys.get(i) + "value值:" + val);
- put.addColumn(this.options.columFamily.getBytes(),
- this.options.qualifier.getBytes(),
- this.options.serializer.serialize(val));
- puts.add(put);
- }
- try {
- this.table.put(puts);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- @Override
- public List<T> multiGet(List<List<Object>> keys) {
- List<Get> gets = new ArrayList<Get>();
- for (final List<Object> key : keys) {
- // LOG.info("Partition: {}, GET: {}", this.partitionNum, key);
- Get get = new Get(toRowKey(key));
- get.addColumn(this.options.columFamily.getBytes(),
- this.options.qualifier.getBytes());
- gets.add(get);
- }
- List<T> retval = new ArrayList<T>();
- try {
- // 批量获取所有rowKey的数据
- Result[] results = this.table.get(gets);
- for (final Result result : results) {
- byte[] value = result.getValue(
- this.options.columFamily.getBytes(),
- this.options.qualifier.getBytes());
- if (value != null) {
- retval.add(this.serializer.deserialize(value));
- } else {
- retval.add(null);
- }
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- return retval;
- }
- private byte[] toRowKey(List<Object> keys) {
- ByteArrayOutputStream bos = new ByteArrayOutputStream();
- try {
- for (Object key : keys) {
- bos.write(String.valueOf(key).getBytes());
- }
- bos.close();
- } catch (IOException e) {
- throw new RuntimeException("IOException creating HBase row key.", e);
- }
- return bos.toByteArray();
- }
- }
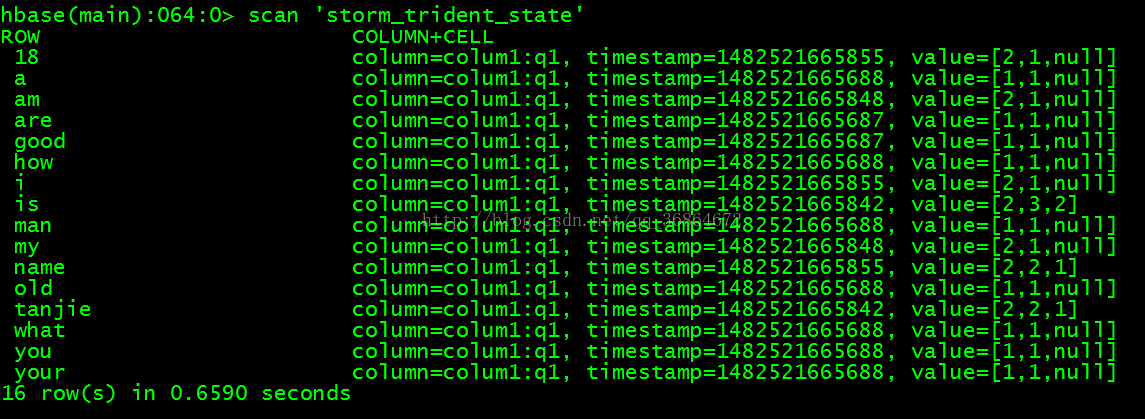
运行结果:
查看supervisor日志:
- 2016-12-23 11:34:25.576 STDIO [INFO] partitionIndex: 0,key.get(i):[good]value值:org.apache.storm.trident.state.OpaqueValue@6498fd6a[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.582 STDIO [INFO] partitionIndex: 1,key.get(i):[name]value值:org.apache.storm.trident.state.OpaqueValue@81e227f[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.582 STDIO [INFO] partitionIndex: 1,key.get(i):[are]value值:org.apache.storm.trident.state.OpaqueValue@726ac402[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.585 STDIO [INFO] partitionIndex: 2,key.get(i):[what]value值:org.apache.storm.trident.state.OpaqueValue@2667735e[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.585 STDIO [INFO] partitionIndex: 2,key.get(i):[your]value值:org.apache.storm.trident.state.OpaqueValue@51c73404[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.585 STDIO [INFO] partitionIndex: 2,key.get(i):[tanjie]value值:org.apache.storm.trident.state.OpaqueValue@6d281c8d[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.585 STDIO [INFO] partitionIndex: 2,key.get(i):[old]value值:org.apache.storm.trident.state.OpaqueValue@646aa4f7[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.586 STDIO [INFO] partitionIndex: 2,key.get(i):[is]value值:org.apache.storm.trident.state.OpaqueValue@157487a2[currTxid=1,prev=<null>,curr=2]
- 2016-12-23 11:34:25.586 STDIO [INFO] partitionIndex: 2,key.get(i):[a]value值:org.apache.storm.trident.state.OpaqueValue@1574a7af[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.586 STDIO [INFO] partitionIndex: 2,key.get(i):[how]value值:org.apache.storm.trident.state.OpaqueValue@1dacdd2a[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.587 STDIO [INFO] partitionIndex: 2,key.get(i):[you]value值:org.apache.storm.trident.state.OpaqueValue@3febff9e[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.587 STDIO [INFO] partitionIndex: 2,key.get(i):[man]value值:org.apache.storm.trident.state.OpaqueValue@1edafedb[currTxid=1,prev=<null>,curr=1]
- 2016-12-23 11:34:25.812 STDIO [INFO] partitionIndex: 2,key.get(i):[tanjie]value值:org.apache.storm.trident.state.OpaqueValue@38a106df[currTxid=2,prev=1,curr=2]
- 2016-12-23 11:34:25.812 STDIO [INFO] partitionIndex: 2,key.get(i):[is]value值:org.apache.storm.trident.state.OpaqueValue@53ca3784[currTxid=2,prev=2,curr=3]
- 2016-12-23 11:34:25.815 STDIO [INFO] partitionIndex: 0,key.get(i):[am]value值:org.apache.storm.trident.state.OpaqueValue@5261a4c8[currTxid=2,prev=<null>,curr=1]
- 2016-12-23 11:34:25.815 STDIO [INFO] partitionIndex: 0,key.get(i):[my]value值:org.apache.storm.trident.state.OpaqueValue@88970b9[currTxid=2,prev=<null>,curr=1]
- 2016-12-23 11:34:25.826 STDIO [INFO] partitionIndex: 1,key.get(i):[i]value值:org.apache.storm.trident.state.OpaqueValue@78b27ff6[currTxid=2,prev=<null>,curr=1]
- 2016-12-23 11:34:25.827 STDIO [INFO] partitionIndex: 1,key.get(i):[name]value值:org.apache.storm.trident.state.OpaqueValue@eef2d62[currTxid=2,prev=1,curr=2]
- 2016-12-23 11:34:25.828 STDIO [INFO] partitionIndex: 1,key.get(i):[18]value值:org.apache.storm.trident.state.OpaqueValue@788c8496[currTxid=2,prev=<null>,curr=1]














 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









