






RDD的依赖关系
描述父RDD和子RDD之间分区的关系
窄依赖
每一个父RDD的分区最对被子RDD的一个分区使用,一对一
宽依赖
一个父RDD的分区会被子RDD的多个分区使用,一对多
join有两种情况
如果在join之前先进行groupByKey操作,join的过程就不会发生shuffle
否则就会发生shuffle
Lineage
RDD只支持粗粒度的转换,用来恢复丢失的数据
DAG的生成
DAG叫做有向无环图,原始RDD通过一系列转化,形成DAG。根据RDD之间的依赖关系的不同,将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于存在shuffle,只能在parent RDD处理完成后,才能开始接下来的计算,由此可见宽依赖是划分stage的依据
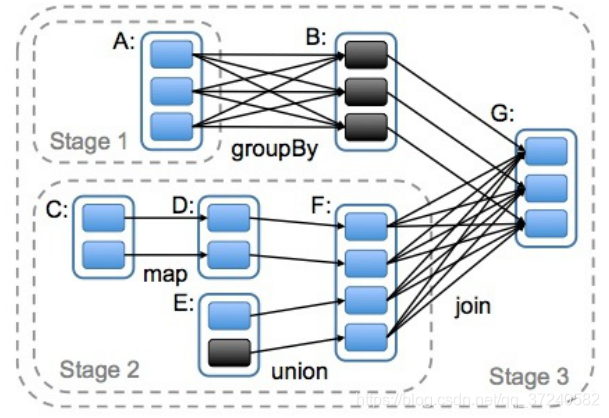
Task生成
task是在stage范围内的,不会跨shuffle
task生成和stage有关系
stage内,有几个分区就有几个task,不同RDD相同的分区形成pinpline,一个pipeline就是一个task
如果在job中,没有改变分区的数量,task的数量是stage的数量*分区的数量
RDD缓存
RDD可以通过persist或者cache方法将前面的计算结果缓存,但不是立刻缓存,只有在触发后面的action算子时,该RDD才会被缓存。
缓存级别
class StorageLevel private(
private var _useDisk: Boolean,//使用硬盘
private var _useMemory: Boolean,//使用内存
private var _useOffHeap: Boolean,//使用堆外内存,不会被垃圾回收机制回收
private var _deserialized: Boolean,//反序列化
private var _replication: Int = 1) //副本数
extends Externalizable
//StorageLevel的伴生对象中定义
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)//硬盘
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)//硬盘,有两份
val MEMORY_ONLY = new StorageLevel(false, true, false, true) //内存
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) //内存,两份
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) //内存,
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
......
用的最多的就是MEMORY_ONLY(只用内存)和MEMORY_AND_DISK(内存和硬盘,当内存不用的时候使用硬盘)
这些都是StorageLevel类型变量,persist重载,有参和无参,有参参数类型为StorageLevel,无参也会调用有参(persist(StorageLevel.MEMORY_ONLY))
cache直接调用无参的persist
缓存也可能发生数据丢失的现象,存储在内存中的数据由于内存不足被删除。RDD的缓存容错机制保证即使缓存丢失也能保证计算的正确执行,通过基于RDD的一些列转换丢失的数据会被重算,由于RDD的各个partition是相对独立的,因此只需要计算丢失部分分区即可,不需要选全部的分区














 4239
4239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









