







小Hi的学校总共有N名学生,编号1-N。学校刚刚进行了一场全校的古诗文水平测验。
学校没有公布测验的成绩,所以小Hi只能得到一些小道消息,例如X号同学的分数比Y号同学的分数高S分。
小Hi想知道利用这些消息,能不能判断出某两位同学之间的分数高低?
Input
第一行包含三个整数N, M和Q。N表示学生总数,M表示小Hi知道消息的总数,Q表示小Hi想询问的数量。
以下M行每行三个整数,X, Y和S。表示X号同学的分数比Y号同学的分数高S分。
以下Q行每行两个整数,X和Y。表示小Hi想知道X号同学的分数比Y号同学的分数高几分。
对于50%的数据,1 <= N, M, Q <= 1000
对于100%的数据,1 <= N, M, Q<= 100000 1 <= X, Y <= N -1000 <= S <= 1000
数据保证没有矛盾。
Output
对于每个询问,如果不能判断出X比Y高几分输出-1。否则输出X比Y高的分数。
Sample Input
10 5 3
1 2 10
2 3 10
4 5 -10
5 6 -10
2 5 10
1 10
1 5
3 5Sample Output
-1
20
0
分析:限时10S,但是点数达到10W,所以尝试DFS失败了。按学长教育使用带权并查集,首次接触,学习一下。
带权并查集:基本的不变,依然是一个快速找到集合归属的数据结构。find函数每次更新自己属于的集合的根节点。不同的是,用一个W数组保存与根节点路径上的权值之和。所以每次更新的时候要更新到根节点权值和。union函数将两个不同的集合合并,如果没有权值,find函数即可以完成合并,这里每次采用向量的计算方法将两个集合的根节点路径计算出来并且保存在W数组中,即W[a] = s +W[X] - W[x];
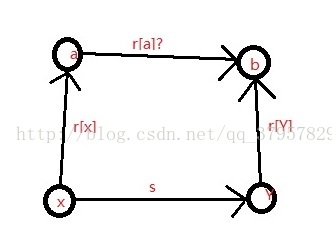
草图。。。。。。。
小细节:查找的时候有可能有部分点的W还没有更新,需要再次find更新一次才会是正确的W。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <vector>
using namespace std;
const int maxn = 100000+5;
const int inf = 0x7fffffff;
int n,m,q;
int u[maxn];
int w[maxn];
int finds(int x)
{
if(u[x] ==x)
return x;
int next = u[x];
u[x]=finds(u[x]);
w[x] += w[next];
return u[x];
}
void unions(int x,int y,int s)
{
int a = finds(x);
int b = finds(y);
u[a] = b;
w[a] = s+w[y]-w[x];
}
int main()
{
//freopen("in.txt","r",stdin);
while(scanf("%d%d%d",&n,&m,&q)==3)
{
for(int i=1;i<=n;i++)
u[i] = i;
int x,y,ww;
for(int i=0;i<m;i++)
{
scanf("%d%d%d",&x,&y,&ww);
unions(x,y,ww);
}
int uu,vv;
for(int i=0;i<q;i++)
{
scanf("%d%d",&uu,&vv);
int x = finds(uu);
int y = finds(vv);
if(x==y)
{
printf("%d\n",w[uu]-w[vv]);
}else
{
printf("-1\n");
}
}
}
return 0;
}














 2698
2698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









