









1、CAP原理&BASE思想(摘自CAP原理和BASE思想)
分布式领域CAP理论
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性), 好的响应性能
Partition tolerance(分区容忍性) 可靠性
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
关系数据库的ACID模型拥有 高一致性 + 可用性 很难进行分区:
Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
Consistency一致性:在事务开始或结束时,数据库应该在一致状态。
Isolation隔离层.:事务将假定只有它自己在操作数据库,彼此不知晓。
Durability持久性: 一旦事务完成,就不能返回。
跨数据库两段提交事务:2PC (two-phase commit), 2PC is the anti-scalability pattern (Pat Helland) 是反可伸缩模式的,JavaEE中的JTA事务可以支持2PC。因为2PC是反模式,尽量不要使用2PC,使用BASE来回避。
BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性,获得可用性或可靠性:
Basically Available基本可用。支持分区失败(e.g. sharding碎片划分数据库)
Soft state软状态 状态可以有一段时间不同步,异步。
Eventually consistent最终一致,最终数据是一致的就可以了,而不是时时高一致。
BASE思想的主要实现有
1.按功能划分数据库
2.sharding碎片
BASE思想主要强调基本的可用性,如果你需要High 可用性,也就是纯粹的高性能,那么就要以一致性或容忍性为牺牲,BASE思想的方案在性能上还是有潜力可挖的。
现在NOSQL运动丰富了拓展了BASE思想,可按照具体情况定制特别方案,比如忽视一致性,获得高可用性等等,NOSQL应该有下面两个流派:
1. Key-Value存储,如Amaze Dynamo等,可根据CAP三原则灵活选择不同倾向的数据库产品。
2. 领域模型 + 分布式缓存 + 存储 (Qi4j和NoSql运动),可根据CAP三原则结合自己项目定制灵活的分布式方案,难度高。
这两者共同点:都是关系数据库SQL以外的可选方案,逻辑随着数据分布,任何模型都可以自己持久化,将数据处理和数据存储分离,将读和写分离,存储可以是异步或同步,取决于对一致性的要求程度。
不同点:NOSQL之类的Key-Value存储产品是和关系数据库头碰头的产品BOX,可以适合非Java如PHP RUBY等领域,是一种可以拿来就用的产品,而领域模型 + 分布式缓存 + 存储是一种复杂的架构解决方案,不是产品,但这种方式更灵活,更应该是架构师必须掌握的。
2、数据分割
优点
对当前细节数据进行分割的总体目的就是
把数据划分成小的物理单元
,为操作者和设计者在管理数据时提供
更大的灵活性
。小物理单元具有
容易重构、自由索引、顺序扫描、容易重组、容易恢复和容易监控
等优点。数据仓库的本质之一就是
灵活地访问数据
,大块数据达不到这个目的。
分割方法
水平分割(Horizontal Splitting)就是把全局关系的元组分割成一些子集,这些子集被称为数据分片或段(Fragment)。数据分片中的数据可能是由于某种共同的性质(如地理、归属)而需要聚集一起的。通常,一个关系中的数据分片是互不相交的,这些分片可以选择地放在一个站点上,也可以通过副本被重复放在不同的站点上。
垂直分割(Vertical Splitting)就是把全局关系按着属性组(纵向)分割成一些数据分片或段(Fragment)。数据分片中的数据可能是由于使用上的方便或访问的共同性而需要聚集一起的。通常,一个关系中的垂直数据分片问只在某些键值上重叠,其他属性是互不相交的。这些垂直分片可以放一个站点上,也可以通过副本被重复放在不同的站点上。
3、副本策略
a、副本
副本(replica/copy)指在分布式系统中为数据或服务提供的冗余。
对于数据副本指在不同的节点上持久化同一份数据,当出现某一个节点的存储的数据丢失时,可以从副本上读到数据。
数据副本是分布式系统解决数据丢失异常的唯一手段。
另一类副本是服务副本,指数个节点提供某种相同的服务,这种服务一般并不依赖于节点的本地存储,其所需数据一般来自其他节点。
b、基本副本协议
副本控制协议指按特定的协议流程控制副本数据的读写行为,使得副本满足一定的可用性和一致性要求的分布式协议。
副本控制协议可以分为两大类“中心化(centralized)副本控制协议”和“去中心化(decentralized)副本控制协议”。
(1)中心化副本控制协议
中心化副本控制协议的基本思路:由一个中心节点协调副本数据的更新、维护副本之间的一致性。
所有副本相关的控制交由中心节点完成,并发控制由中心节点完成,从而简化一个分布式并发控制问题为一个单机并发控制问题。而所谓并发控制,即多个节点同时需要修改副本数据时,需要解决“WW”,"RW"等并发冲突。
Primary-secondary协议
该协议是中心化副本控制协议中常常用到的,该协议将副本分为两大类:其中有且仅有一个副本作为primary副本,除primary意外的副本都作为secondary副本。
维护primary副本的节点作为中心节点,中心节点负责维护数据的更新、并发控制、协同副本的一致性。
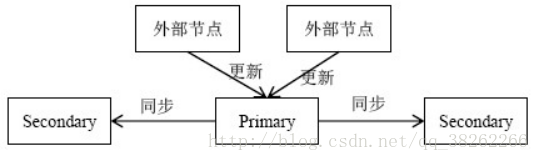
1、数据更新基本流程
1.数据更新都由primary节点协调完成
2.外部节点将更新操作发给primary节点
3.primary节点进行并发控制即确定并发更新操作的先后顺序
4.primary节点将更新操作发送给secondary节点
5.primary根据secondary节点的完成情况决定更新是否成功并将结果返回外部节点
1.数据更新都由primary节点协调完成
2.外部节点将更新操作发给primary节点
3.primary节点进行并发控制即确定并发更新操作的先后顺序
4.primary节点将更新操作发送给secondary节点
5.primary根据secondary节点的完成情况决定更新是否成功并将结果返回外部节点
2、数据读取方式
与数据更新流程类似,读取方式也与一致性高度相关。使用primary-secondary比较困难的是实现强一致性。实现强一致性一般有如下几个思路:
1.始终只读primary副本的数据
2.由primary控制节点secondary节点的可用性。
3.基于Quorum机制
3、Primary副本的确定和切换
primary副本的确定通常由原信息管理,由专门的元数据服务器维护,执行更新操作时,首先查询元数据服务器获取副本的primary信息,从而进一步执行数据更新流程。
primary副本的切换通常可以使用lease机制来完成。
与数据更新流程类似,读取方式也与一致性高度相关。使用primary-secondary比较困难的是实现强一致性。实现强一致性一般有如下几个思路:
1.始终只读primary副本的数据
2.由primary控制节点secondary节点的可用性。
3.基于Quorum机制
3、Primary副本的确定和切换
primary副本的确定通常由原信息管理,由专门的元数据服务器维护,执行更新操作时,首先查询元数据服务器获取副本的primary信息,从而进一步执行数据更新流程。
primary副本的切换通常可以使用lease机制来完成。
4、数据同步
数据同步是因为primary副本可能会存在于secondary副本不一致的问题。通常有如下三种形式:
1.由于网络分化等异常,secondary上的数据落后于primary上的数据。—— redo primary副本上的操作日志。
2.在某些协议下,secondary上的数据有可能是脏数据,需要被丢弃。—— undo日志的方法删除脏数据
3.secondary是一个新增加的副本,完全没有数据,需要从其他副本上拷贝数据。—— 使用primary副本的snapshot(快照)功能
数据同步是因为primary副本可能会存在于secondary副本不一致的问题。通常有如下三种形式:
1.由于网络分化等异常,secondary上的数据落后于primary上的数据。—— redo primary副本上的操作日志。
2.在某些协议下,secondary上的数据有可能是脏数据,需要被丢弃。—— undo日志的方法删除脏数据
3.secondary是一个新增加的副本,完全没有数据,需要从其他副本上拷贝数据。—— 使用primary副本的snapshot(快照)功能
(2)去中心化(decentralized)副本控制协议
paxos协议
多个节点直接通过操作日志同步数据,如果只有一个节点称为主节点,就很容易在多个节点之间维护数据一致性。然后主节点可能出现故障,那么就需要选出主节点。Paxos协议就是用于解决多个节点之间的一致性问题。
在paxos算法中,分为4种角色:
Proposer :提议者
Acceptor:决策者
Client:产生议题者
Learner:最终决策学习者
Proposer :提议者
Acceptor:决策者
Client:产生议题者
Learner:最终决策学习者
4、完成hadoop集群


1、克隆(略)
2、静态IP配置(修改三个配置文件、a/名称、b/ip主机名映射、c/静态ip)
以master为例,slave同样,可以在ip值上+1,保证能够在本网段内
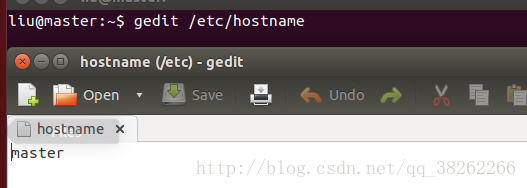
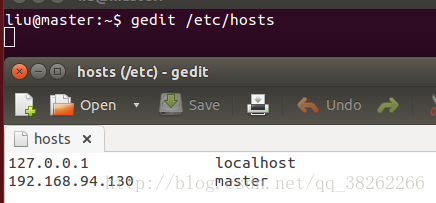
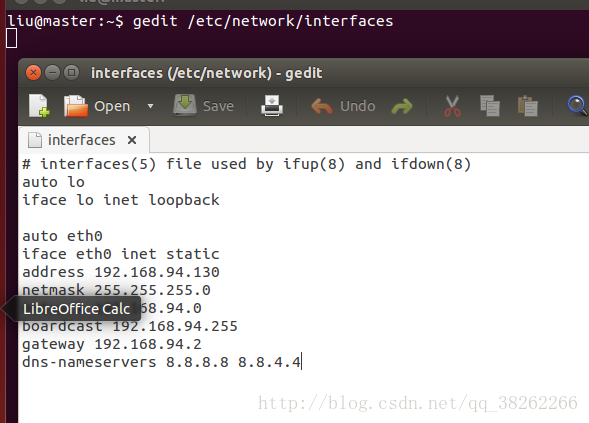
3、ssh免密码登录
先在master上,在当前用户目录下生成公钥、私钥对
alice@master:~$ssh-keygen -t rsa -P ''
查看生成.ssh文件
alice@master:~$ls -al
进入.ssh/文件
alice@master:~$cd .ssh/
导入公钥$cat id_rsa.pub > authorized_keys
然后执行 ssh master 即可查看是否对自己免密登录了,如果还需要输入密码,则失败。














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









