







Apache Hive简介:
维基百科介绍:
Apache Hive是一个建立在Hadoop架构之上的数据仓库.它能够提供数据的精炼,查询和分析,Apache Hive起初由Facebook开发,目前也有其他公司使用和开发Apache Hive,例如Netflix等。亚马逊公司也开发了一个定制版本的Apache Hive,亚马逊网络服务包中的Amazon Elastic MapReduce包含了该定制版本。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL的查询功能,可以将SQL语句转换为 MapReduce任务进行运行,其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive与关系型数据库的对比
1.hive和关系型数据库存储文件系统的不同,hive使用的是Hadoop的HDFS;关系数据库则是服务器本地的系统
2.hive使用的是MapReduce的计算模型,二关系型数据则是自己设计的计算模型
3.关系型数据库是为实时查询业务进行设计的,而hive是则是为了海量数据做挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大区别和不同
4.Hive很容易扩展自己的存储能力和计算能力,这个继承Hadoop的,而关系数据库在这个方面比数据库差很多.
5.关系数据库一个重要的特点是可以对某一行或某些行的数据进行更新、删除操作,hive不支持对某个具体行的操作,hive对数据的操作只支持覆盖原数据和追加数据。Hive也不支持事务和索引。更新、事务和索引都是关系数据库的特征,这些hive都不支持,也不打算支持,原因是hive的设计是海量数据进行处理,全数据的扫描时常态,针对某些具体数据进行操作的效率是很差的,对于更新操作,hive是通过查询将原表的数据进行转化最后存储在新表里,这和传统数据库的更新操作有很大不同。
Hive的架构图
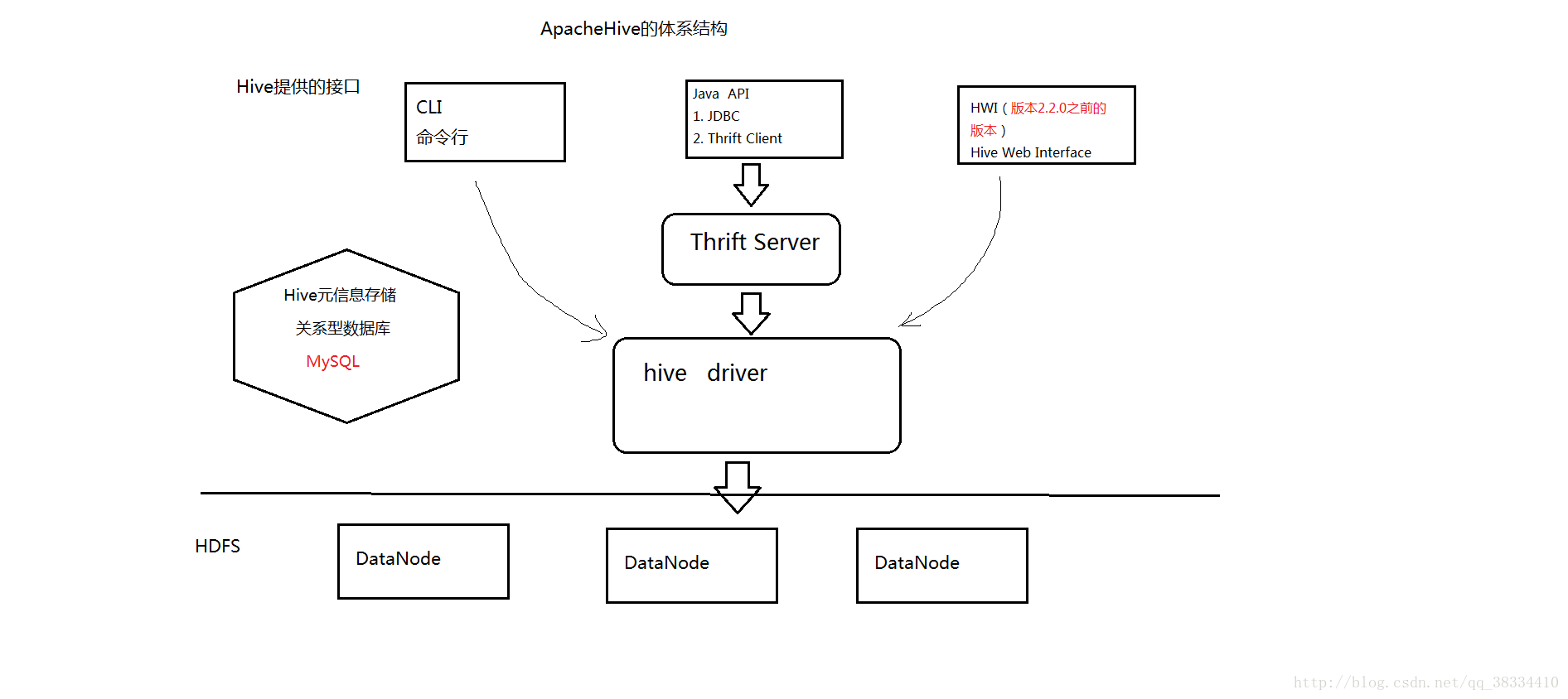
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
服务端的一些组件:
Driver组件: 该组件包括Complier, Optimizer和Executor,他的作用将我们写的HiveQL(类SQL)语句解析,编译优化,生出执行计划然后调用底层的mapreduce计算框架
Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
客户端:
CLI:command line interface,命令行接口。
PS:Hive的metastore组件时hive元数据集中存放地.Metastore组件包括两个部分:metastore服务和后台数据存储.后台数据存储的介质是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质上,并且可以和hive服务精心交互的服务组件,默认的情况下,metastore服务和忽略服务是安装在一起,运行在同一个进程中。我们可以吧metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率。
Hive的数据模型和数据类型:
1.内部表:相当于MySQL中的表
//指定以“,”分隔
create table emp(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int) row format delimited fields terminated by ',';
保存数据: insert语句, load语句
load (1) 加载HDFS数据到Hive的表中 (2)加载本地Linux数据到Hive的表中
相当于: ctrl + x
举例: 加载HDFS: load data inpath '/scott/emp.csv' into table emp;
加载本地数据: load data local inpath '/scott/emp.csv' into table emp; 2.分区表—> 每个分区也是一个HDFS的目录
(*) 复习: 分区
Oracle中的分区
(1) 范围分区
(2)列表分区
(3)Hash分区
(4)Hash-范围分区
(5)hash-列表分区
建立分区是为了提高效率 ——>查看SQL的执行计划
按照员工的部门号建立分区表
create table emp_part
(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int
)
partitioned by (deptno int)
row format delimited fields terminated by ' , ';
使用子查询往分区表中插入数据
insert into table emp_part partition(deptno=10) select empno, ename,job,mgr,hiredate,sal,comm from emp1 where deptno=10;
insert into table emp_part partition(deptno=20) select empno, ename,job,mgr,hiredata,sal,comm from emp1 where deptno=203.外部表
(*)概念:将数据保存在Hive数据仓库目录的外面
(*)创建表的时候,指向一个HDFS的目录
(*)举例
create external table ext_student((sid int,sname string,age int) row format delimited fields terminated by ','
localtion '/students'(*)Oracle数据库也有外部表
数据的加载方式:
(1)Oracle SQL*Loader
(2)Oracle数据泵
4.桶表: 类似Oracle数据中Hash分区
(1) 也是一种分区表,但每个分区是一个文件
create table emp_bucket
(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int
)
clustered by (job) into 4 backets
row format delimited fields terminated by ',';
使用桶表,打开一个开关
set hive.enforce.bucketing=true;
插入数据
inset into emp_bucket select * from emp;













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









