







- 凸优化的定义
1.1 凸优化
1.2 全局最优化与局部最优化 - Least-squares and linear programming(最小二乘与线性规划)
2.1 最小二乘
2.2 线性规划 - 最优化方法的一般结构
- 优化理论在机器学习,深度学习中扮演的角色
1.优化的定义
1.1 凸优化
最优化问题目前在机器学习,数据挖掘等领域应用非常广泛,因为机器学习简单来说,主要做的就是优化问题,先初始化一下权重参数,然后利用优化方法来优化这个权重,直到准确率不再是上升,迭代停止,那到底什么是最优化问题呢?
它的一般形式为:
- 相当于你要从上海去北京,你可以选择搭飞机,或者火车,动车,但只给你500块钱,要求你以最快的时间到达,其中到达的时间就是优化的目标,500块钱是限制条件,选择动车,火车,或者什么火车都是x。
满足所有约束条件的点集称为可行域,记为X,又可以写为:
在优化问题中,应用最广泛的是凸优化问题:
- 若可行域X是一个凸集:即对于任给的
x,y∈X
,总有
λx+(1−λ)y∈X,对于任意的 λ∈(0,1)
- 并且目标函数是一个凸函数:即
f(λx+(1−λ)y))≤λf(x)+(1−λ)f(y)我们称这样的优化问题为凸优化问题。
用图像来表示就是:
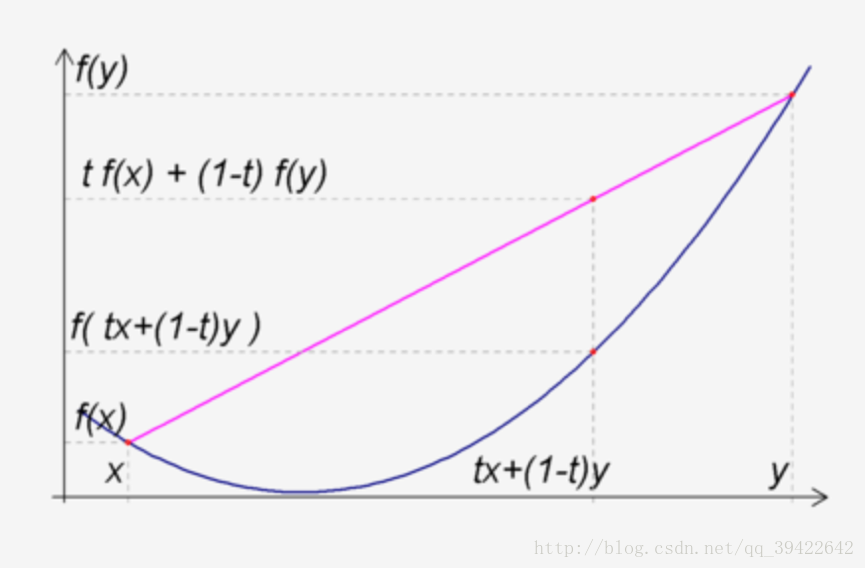
函数上方的点集就是凸集,函数上任意两点的连线,仍然在函数图像上方。
一句话说清楚就是:希望找到合适的
x
,使得
1.2 全局最优化与局部最优化
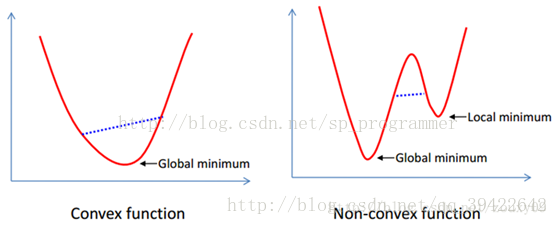
全局最优化指的是在满足条件约束的情况下,找到唯一的一个点满足最大值或者最小值。
局部最优化指的是在满足条件约束的情况下,有可能找到一个局部最大/小点,但不是全局最大或者最小的点。
用图像表示为:
2.Least-squares and linear programming(最小二乘与线性规划)
关于这两个问题的更详细的例子会在接下来的文章中说到,这次只是简单的介绍一下我们的内容。
2.1 最小二乘
最小二乘问题是无约束的优化问题,通常可以理解为测量值与真实值之间的误差平方和:
这个问题既然没有约束条件,那应该怎么求解呢?我们的目标是求解出最好的x,观察这个式子可以发现,这个式子一定是大于等于0的,所以这样的最优化问题,我们可以把它转成线性方程来求解:
加权的最小二乘问题:
正则化的最小二乘问题:
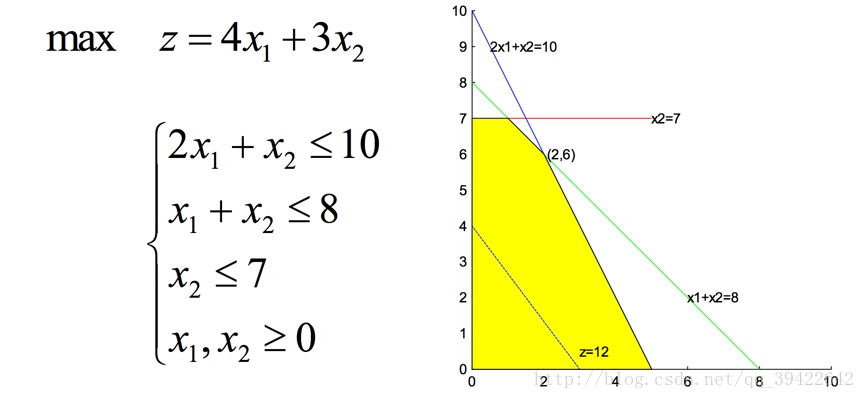
2.2 线性规划
另一类重要的优化问题是线性规划,它的目标函数和约束条件都是线性的:
用画图的方法,就是根据条件,画出可行域,然后将目标函数在可行域上移动,直到得到最大值。
3.最优化方法的一般结构
最优化的过程,相当于爬山,如图:
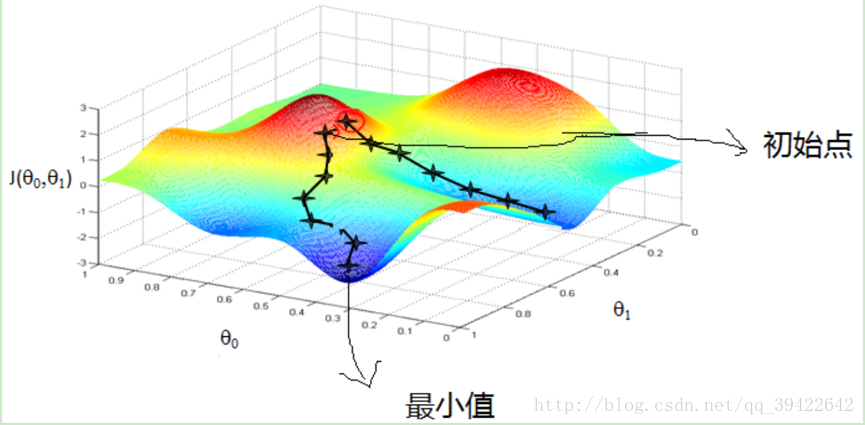
希望找到一个点列
xk
使得他的函数值是一直减少的,直到到达某一停止条件或者达到最小值的点
xk
.
用数学上的术语可以表示为:
- 设
xk
为第k次迭代点,
dk
为第k次搜索方向,
αk
为第k次迭代的步长因子,则第k次迭代为:
xk+1=xk+αkdk
从这里可以看到不同的步长和不同的搜索方向组成了不同的优化方法,这就是最优化理论中所讨论的。
f
是
而最优化的基本可以表示为:给定初始点 xk
- 确定搜索方向 dk ,即按照一定规则画方法确定f在 xk 处的下降方向
- 确定步长因子 αk ,使得目标函数有一定的下降
- 令
xk+1=xk+αkdk不断迭代,直到 xk+1 满足某种某种停止条件,即得到最优解 xk+1
最优化中的问题中,大部分都是在寻找各种各样的方法确定步长和方向,使得迭代的速度尽可能快,得到的解尽可能是最优的解。
4.优化理论在机器学习,深度学习中扮演的角色
凸优化,或者更广泛的说,是最优化理论,在目前的机器学习,数据挖掘,或者是深度学习的神经网络中,都要用到。
他的地位相当于人的脊背一样的,支撑着整个模型的学习过程。因为模型,通俗来说就像人学习思考一样,我们自己知道自己该学什么,该怎么学,发现自己的知识学错了之后怎么调整,但计算机可没有人这么聪明,知道学什么,往哪里学。
而最优化,就是告诉模型应该学什么,怎么学的工具。模型学习的往往都是一个映射函数,也就是模型中的参数W,这个参数的好坏,得看答案才能知道,但知道自己错了之后,该往哪里学,怎么学,怎么调整,这就是优化理论在其中扮演的角色。如果没有优化理论,那么模型是不知道该怎么学习的,也就是没有了最优化,模型的学习永远都是停滞不前的,这下你知道最优化理论的重要性了吧。














 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









