







一、Redis的持久化机制
1.简介
Redis有两种持久化机制,分别是RDB和AOF,RDB:每个一段时间保存一个快照;AOF:保存每次写的操作指令;
2.RDB
(1)RDB的概念
RDB:每隔一段时间,把内存中的数据写入磁盘的临时文件,作为快照,恢复的时候把快照文件读进内存。如果宕机重启,那么内存里的数据肯定会没有的,因为RDB的存在,那么重启redis后,则会恢复。
(2)备份与恢复
备份:内存备份 --> 磁盘临时文件
恢复:磁盘临时文件 --> 恢复到内存
(3)RDB优劣势分析
优势
a. 每隔一段时间全量备份(快照)
b. 灾备简单,可以远程传输
c. 子进程备份的时候,主进程不会有任何io操作(不会有写入修改或删除),保证备份数据的的完整性
d. 相对AOF来说,当有更大文件的时候可以快速重启恢复
劣势
a发生故障是,有可能会丢失最后一次的备份数据
b.可能会造成CPU负担,因为子进程所占用的内存比会和父进程一模一样
c. 由于定时全量备份是重量级操作,所以对于实时备份,就无法处理了
(4)配置RDB持久化机制
修改redis.conf文件的关键信息
#快照文件名称
dbfilename "dump.rdb"
#redis工作目录,临时备份文件将会存在这个位置
dir "/usr/local/redis/working"
#至少发生了一次变化,会在900秒后保存
save 900 1
#至少发生了10次变化,会在300秒后保存
save 300 10
#至少发生了10000次变化,会在60秒后保存
save 60 10000
#如果save过程出错,是否停止写操作 yes:停止|no:不停止,一般使用yes
stop-writes-on-bgsave-error yes
#是否开启rdb压缩模式
rdbcompression yes
#压缩时,是否真的rdb进行校验
rdbchecksum yes
注意,如果使用RDB,可能会丢失最后一次备份的rdb文件,如果对于数据完整性关注度不高,可以忽略不计,如果数据完整性要求高,可以选择使用AOF持久化机制
3.AOF
(1)概念
a.以日志的形式来记录用户请求的写操作。只记录写操作
b. 文件以追加的形式而不是修改的形式
c. redis的aof恢复其实就是把追加的文件从开始到结尾读取执行写操作
(2)RDB优劣势分析
优势
a. AOF更加精确,可以以秒级别为单位备份,如果发生问题,也只会丢失最后一秒的数据,大大增加了可靠性和数据完整性
b.当数据太大的时候,redis可以在后台自动重写aof。当redis继续把日志追加到老的文件中去时,重写也是非常安全的,不会影响到客户端的其他操作
c. AOF 日志包含的所有写操作,会更加便于redis的解析恢复
d.以log日志形式追加,如果磁盘满了,会执行 redis-check-aof 工具
劣势
a.同一份数据,AOF更占内存
b. 针对不同的同步机制,AOF会比RDB慢,因为AOF每秒都会备份做写操作,这样相对与RDB来说性能就略低
c.AOF发生过bug,就是数据恢复的时候数据不完整,这样显得AOF会比较脆弱,容易出现bug
(3)配置AOF持久化机制
修改redis.conf文件的关键信息
# AOF 默认关闭,yes可以开启
appendonly no
# AOF 的文件名
appendfilename "appendonly.aof"
#备份机制 no:不同步 | everysec:每秒备份,推荐使用 | always:每次操作都会备份,安全并且数据完整,但是慢性能差
appendfsync everysec
# 重写的时候是否要同步,no可以保证数据安全
no-appendfsync-on-rewrite no
# 重写机制:避免文件越来越大,会自动优化压缩指令,该机制会复刻一个新的进程去完成重写动作,新进程里的内存数据会被重写,此时
# 当前AOF文件的大小是上次AOF大小的100% 并且文件体积达到64m,满足两者则触发重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
二、Redis 内存淘汰机制与缓存过期处理
1.Redis 的内存淘汰机制
(1)概念
当内存占用满了以后,redis提供了一套缓存淘汰机制:MEMORY MANAGEMENT
(2)策略
#默认
maxmemory-policy noeviction
解释:
noeviction:旧缓存永不过期,新缓存设置不了,返回错误
allkeys-lru:清除最少用的旧缓存,然后保存新的缓存(推荐使用)
allkeys-random:在所有的缓存中随机删除(不推荐)
volatile-lru:在那些设置了expire过期时间的缓存中,清除最少用的旧缓存,然后保存新的缓存
volatile-random:在那些设置了expire过期时间的缓存中,随机删除缓存
volatile-ttl:在那些设置了expire过期时间的缓存中,删除即将过期的
2.Redis的缓存过期处理
(1)概念
Redis的高并发高性能都是基于内存的,但是内存都是有限的,并且内存越大的服务器越贵。
(2)设置了expire的key缓存过期了,但是服务器的内存还是会被占用,这是与redis的缓存过期删除策略有关
a.定时随机的检查过期的key,如果过期则清理删除。(每秒检查次数在redis.conf中的hz配置)
b.当客户端请求一个已经过期的key的时候,那么redis会检查这个key是否过期,如果过期了,则删除,然后返回一个nil。这种策略对CPU比较友好,惰性删除,基本不会损耗CPU,但是内存占用会比较高。
当然,Redis是使用了这两种机制相结合的形式来进行过期处理的,对于内存占用情况还是有不错的改善。
三、redis的主从机制
1. 单节点分析
一般情况而言,单节点并发可以达到几万,如果运维人员对优化做的足够好,也最多不会超过20万,所以当并发量上来后,可以考虑使用主从模式;
2.主从模式概念
主从模式,也是读写分离模式,主节点负责写数据,并且将新的数据同步到从节点,而从节点负责读数据。主从模式,属于水平扩展,通过增加服务器节点的方式来提高并发量。使用主从模式,如果在从节点上写数据,这里会提示错误,因为从节点只负责读取数据。
3.主从原理
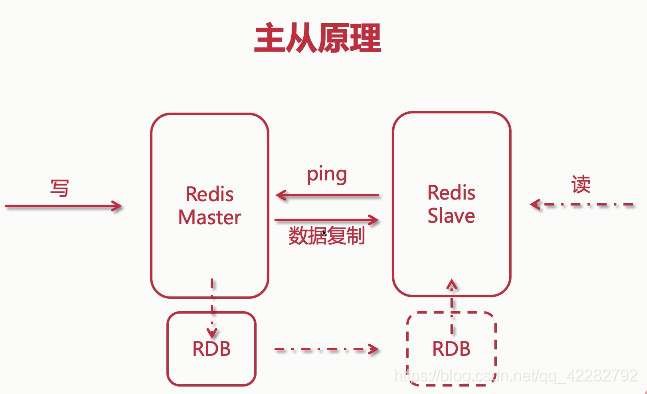
(1)初始化
从节点(slave)初次启动时会向主节点(master)发送ping包,在发送ping包后,主节点会把数据全量的同步到从节点。
(2)后续写操作
主节点每一次触发写操作,都会将指令同步给从节点,以此来修改从节点相应的数据
(3)slave宕机重启
slave宕机重启后,master会把slave宕机的这段时间的数据增量的同步给slave
(4)主从模式,master必须开启持久化
主从模式下,如果master没有开启持久话,那么一旦宕机,master再次重启时,所有数据都将会丢失,包括从节点的数据。
4.配置主从模式
(1)修改从节点配置文件redis.conf
a.进入配置目录
#配置文件目录根据实际情况而定
cd /usr/local/redis
b.搜索配置目标
/replica
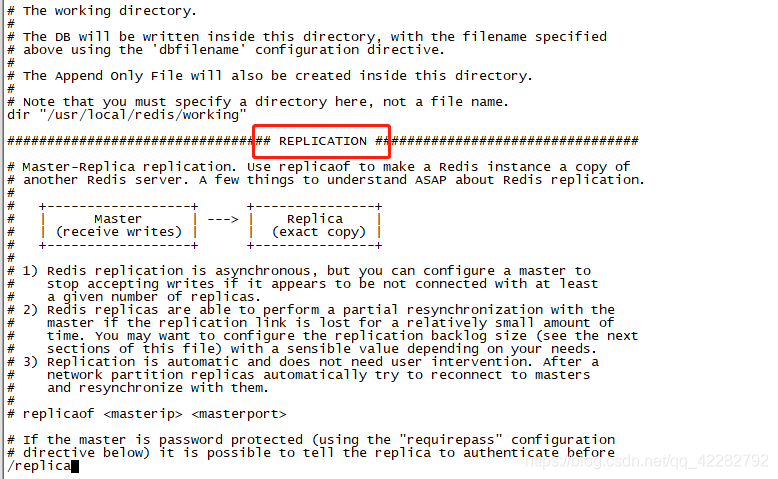
c.配置内容
#主节点信息
replicaof 192.168.1.2 6379
#主节点密码
masterauth root
#配置从节点为只读
replica-read-only yes
注:
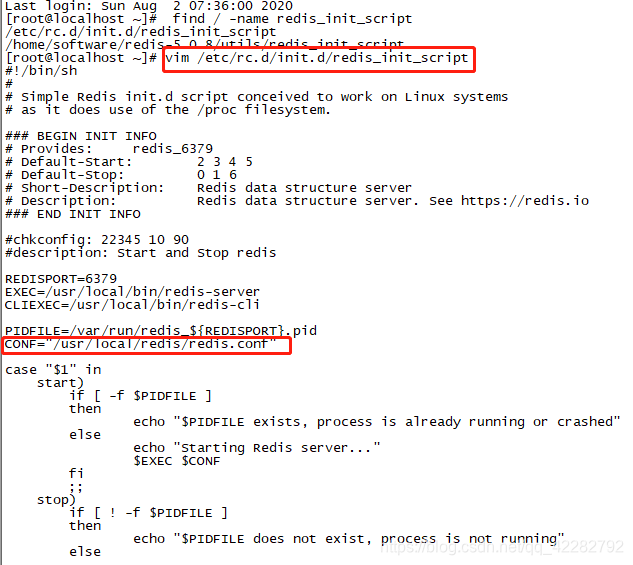
如果不知道redis使用的配置文件在哪里,可以使用find / -name redis_init_script 检查启动文件中关联的配置文件在哪里
查找启动文件

查看关联的配置文件
四、redis的哨兵机制
1.意义
Master挂了,继续保证可用性,实现继续读写
2.概念
Sentinel(哨兵)是用于监控Redis集群中Master状态的工具,是 Redis 高可用解决方案,哨兵可以监视一个或者多个redis master服务,以及这些master服务的所有从服务。当某个master服务宕机后,会把这个master下的某个从服务升级为master来替代已宕机的master继续工作。
3.配置主节点
(1)拷贝redis解压目录下的sentinel.conf文件到/usr/local/redis/目录
#进入解压目录
cd /home/software/redis-5.0.8
#拷贝文件
cp sentinel.conf /usr/local/redis/
(2)修改sentinel.conf文件
cd /usr/local/redis/
vim sentinel.conf
(3)配置内容
普通配置:
这里只展示修改过的配置,其他默认
#是否开启保护模式,注意节点没有在公网上使用no,在公网上需要改为yes,且需要配置bind
protected-mode no
#哨兵是否在后台运行
daemonize yes
#日志文件
logfile /usr/local/redis/sentinel/redis-sentinel.log
#工作目录
dir /usr/local/redis/sentinel
核心配置
这里只展示可能需要修改的内容,其他默认
# 配置哨兵
sentinel monitor mymaster 127.0.0.1 6379 2
# 密码
sentinel auth-pass <master-name> <password>
# master被sentinel认定为失效的间隔时间
sentinel down-after-milliseconds mymaster 30000
# 剩余的slaves重新和新的master做同步的并行个数
sentinel parallel-syncs mymaster 1
# 主备切换的超时时间,哨兵要去做故障转移,这个时候哨兵也是一个进程,如果他没有去执行,超过这个时间后,会由其他哨兵接替当前哨兵的工作
sentinel failover-timeout mymaster 180000
4.配置从节点
(1)将主节点的sentinel.conf文件远程拷贝到从节点
scp sentinel.conf root@192.168.1.7:/usr/local/redis/
(2)检查从节点sentinel.conf文件是否有误
more sentinel.conf | grep ^[^#]
5.启动-主节点
(1)启动主节点哨兵
redis-sentinel sentinel.conf
(2)查看进程
ps -ef|grep redis

(3)查看启动日志
cd /usr/local/redis/sentinel/
tail -f redis-sentinel.log
6.启动-从节点
(1)启动
redis-sentinel sentinel.conf
(2)打开客户端,检查主从是否配置错误
redis-cli
auth root
info replication
7.原Master恢复后很有可能出现不同步的问题
(1)现象
当master宕机后,再次重启恢复,此时该节点的角色从主节点转换为从节点,在该节点的客户端中通过指令info replication查看节点信息,如果看到主节点的状态为 master_link_status:down,则说明当前节点的redis核心配置文件(redis.conf)没有配置masterauth
(2)解决
修改redis核心配置文件(redis.conf)
#主节点密码
masterauth root
(3)其他可能造成master数据无法同步给slave的原因
a. 网络通信问题,要保证互相ping通,内网互通
b. 关闭防火墙,对应的端口开发(虚拟机中建议永久关闭防火墙,云服务器的话需要保证内网互通)
c.统一所有的密码(masterauth),不要漏了某个节点没有设置
8.哨兵信息检查
# 查看mymaster下的master节点信息
sentinel master mymaster
# 查看mymaster 下的slaves节点信息
sentinel slaves mymaster
# 查看mymaster 下的哨兵节点信息
sentinel sentinels mymaster
五、Redis-Cluster 集群
1.经典模式
三主三从,经典模式
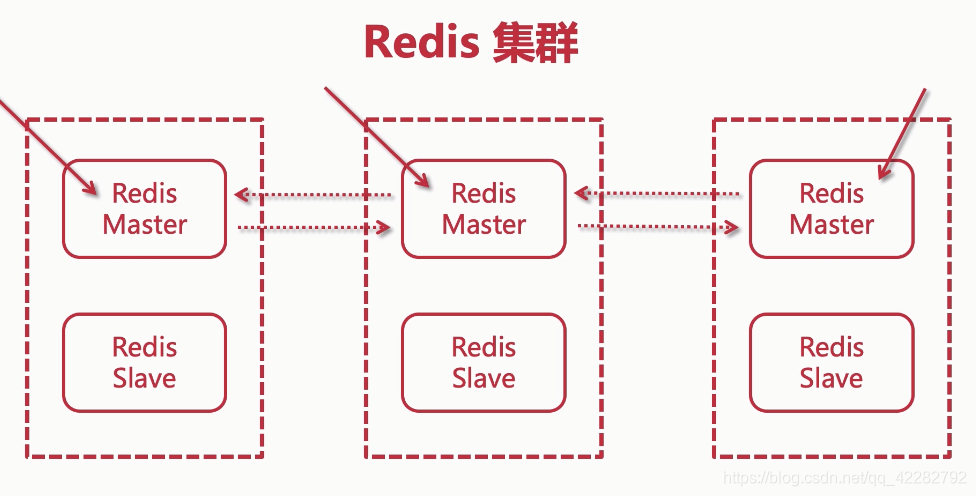
2.环境准备
准备6台redis单节点服务器,尽量不要使用配置过其他模式的redis节点,避免出现异常情况。如果一定要用,记得还原配置,主要是redis.conf
3.构建Redis集群
(1)redis.conf 配置
# 开启集群模式
cluster-enabled yes
# 每一个节点需要有一个配置文件,需要6份。每个节点处于集群的角色都需要告知其他所有节点,彼此知道,这个文件用于存储集
cluster-config-file nodes-201.conf
# 超时时间,超时则认为master宕机,随后主备切换
cluster-node-timeout 5000
# 开启AOF
appendonly yes
(2)删除原有备份文件
#进入redis.conf 中的dir配置的目录下,具体路径视个人情况而定
cd /usr/local/redis/working
#删除RDB备份文件
rm dump.rdb -f
#删除aof备份文件
rm appendonly.aof -f
(3)启动6个redis实例
a.启动6台
b. 如果启动过程出错,把rdb等文件删除清空
(4)创建集群
#####
# 注意1:如果你使用的是redis3.x版本,需要使用redis-trib.rb来构建集群,最新版使用C语言来构建了,这个要注意 # 注意2:以下为新版的redis构建方式
##### # 创建集群,主节点和从节点比例为1(--cluster-replicas 1),1-3为主,4-6为从,1和4,2和5,3和6分别对应为主从关系。这也是redis集群中最经典的一种
redis-cli -a root --cluster create ip1:port1 ip2:port2 ip3:port3 ip4:port4 ip5:port5 ip6:port6 --cluster-replicas 1
按回车后,会提示是否可以设置时,请输入yes
注意:使用redis-cli --cluster指令可以查看集群指令管理。
slots:槽,用于装数据,主节点有,从节点没有
(5)检查集群信息
redis-cli -a root --cluster check ip:port
(6)进入集群控制台
redis-cli -c -a root -h ip -p port
#在集群控制台中,查看集群信息
cluster info
#在集群控制台中,查看节点信息
nodes info
如果没有密码,就不需要使用额外附加指令-a root
4.关于槽节点
(1)槽(slot)节点分配

特点:均等分配,只要master上才有槽节点
(2)槽怎么存储
hash(key)%16384(总槽节点)














 5683
5683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









