









B/S 网络架构:
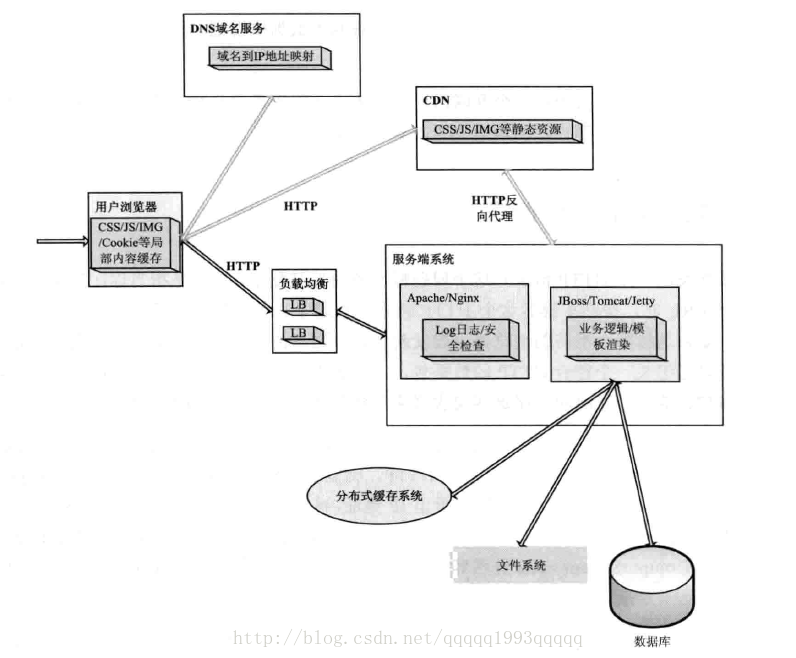
http://blog.csdn.net/m13666368773/article/details/8060481 (简单地解释了正向代理和反向代理,很清晰!)
http://blog.csdn.net/yanxi252515237/article/details/51955675
(四次挥手的抓包)
(转)一次完整的HTTP事务是怎样一个过程?
当我们在浏览器的地址栏输入 www.linux178.com ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
(简单的必经过程)
域名解析 –> 发起TCP的3次握手 –> 建立TCP连接后发起http请求 –> 服务器响应http请求,浏览器得到html代码 –> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) –> 浏览器对页面进行渲染呈现给用户
以下就是上面过程的一 一分析,我们就以Chrome浏览器为例:
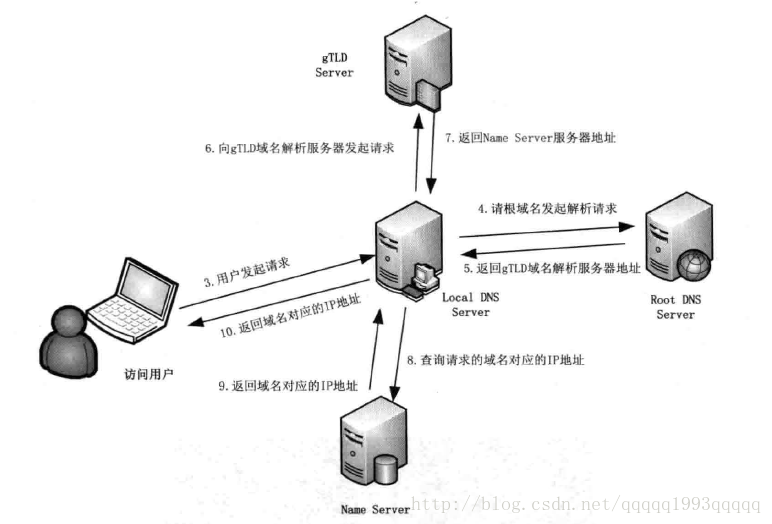
一、域名解析
1 Chrome浏览器 会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有www.linux178.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
注:我们怎么查看Chrome自身的缓存?可以使用 chrome://net-internals/#dns 来进行查看
2 如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
注:怎么查看操作系统自身的DNS缓存,以Windows系统为例,可以在命令行下使用 ipconfig /displaydns 来进行查看 (位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
在该文件中,你可以将任何域名解析到任何能够访问的IP地址,这也是域名有可能被劫持的原因。
3 如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,LDNS)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。
4 如果没有找到对应的条目,则LDNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(LDNS服务器都内置13台根域的DNS的IP地址),找到根域的DNS地址,就会向其发起请求。
5 根域(Root Server)发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址。于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求。
6 com域(gTLD 国际顶级域名服务器)这台服务器告诉运营商DNS我不知道www.linux178.com这个域名的IP地址,但是我知道linux178.com这个域的DNS地址。
7 于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求,运营商的DNS服务器就拿到了www.linux178.com这个域名对应的IP地址和一个TTL值,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.linux178.com对应的IP地址,该进行下一步的动作了。
注:一般情况下是不会进行以下步骤的
如果经过以上的7个步骤,还没有解析成功,那么会进行如下步骤:
8 操作系统就会查找NetBIOS name Cache(NetBIOS名称缓存,就存在客户端电脑中的),那这个缓存有什么东西呢?凡是最近一段时间内和我成功通讯的计算机的计算机名和Ip地址,就都会存在这个缓存里面。什么情况下该步能解析成功呢?就是该名称正好是几分钟前和我成功通信过,那么这一步就可以成功解析。
9 如果第8步也没有成功,那会查询WINS 服务器(是NETBIOS名称和IP地址对应的服务器)
10 如果第9步也没有查询成功,那么客户端就要进行广播查找
11 如果第10步也没有成功,那么客户端就读取LMHOSTS文件(和HOSTS文件同一个目录下,写法也一样)
如果第八步还没有解析成功,那么就宣告这次解析失败,那就无法跟目标计算机进行通信。只要这八步中有一步可以解析成功,那就可以成功和目标计算机进行通信。
===
看下图抓包截图:
Linux虚拟机测试,使用命令 wget www.linux178.com 来请求,发现直接使用chrome浏览器请求时,干扰请求比较多,所以就使用wget命令来请求,不过使用wget命令只能把index.html请求回来,并不会对index.html中包含的静态资源(js、css等文件)进行请求。

1 号包,这个是那台虚拟机在广播,要获取192.168.100.254(也就是网关)的MAC地址,因为局域网的通信靠的是MAC地址,它为什么需要跟网关进行通信是因为我们的DNS服务器IP是外围IP,要出去必须要依靠网关帮我们出去才行。
2 号包,这个是网关收到了虚拟机的广播之后,回应给虚拟机的回应,告诉虚拟机自己的MAC地址,于是客户端找到了路由出口。
3 号包,这个包是wget命令向系统配置的DNS服务器提出域名解析请求(准确的说应该是wget发起了一个DNS解析的系统调用),请求的域名www.linux178.com,期望得到的是IP6的地址(AAAA代表的是IPv6地址)
4 号包,这个DNS服务器给系统的响应,很显然目前使用IPv6的还是极少数,所以得不到AAAA记录的
7 号包,这个才是请求的域名对应的IPv4地址(A记录)
8 号包,DNS服务器不管是从缓存里面,还是进行迭代查询最终得到了域名的IP地址,响应给了系统,系统再给了wget命令,wget于是得到了www.linux178.com的IP地址,这里也可以看出客户端和本地的DNS服务器是递归的查询(也就是服务器必须给客户端一个结果)这就可以开始下一步了,进行TCP的三次握手。
二、TCP的三次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有http,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。

1) Client首先发送一个连接试探,ACK=0 表示确认号无效,SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据,seq = x 表示Client自己的初始序号(seq = 0 就代表这是第0号包),这时候Client进入syn_sent状态,表示客户端等待服务器的回复
2) Server监听到连接请求报文后,如同意建立连接,则向Client发送确认。TCP报文首部中的SYN 和 ACK都置1 ,ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到(ack=1其实是ack=0+1,也就是期望客户端的第1个包),seq = y 表示Server 自己的初始序号(seq=0就代表这是服务器这边发出的第0号包)。这时服务器进入syn_rcvd,表示服务器已经收到Client的连接请求,等待client的确认。
3) Client收到确认后还需再次发送确认,同时携带要发送给Server的数据。ACK 置1 表示确认号ack= y + 1 有效(代表期望收到服务器的第1个包),Client自己的序号seq= x + 1(表示这就是我的第1个包,相对于第0个包来说的),一旦收到Client的确认之后,这个TCP连接就进入Established状态,就可以发起http请求了。
三、建立TCP连接后发起http请求
进过TCP3次握手之后,浏览器发起了http的请求(看第⑫包),使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0

下面是第12号包的详细内容:
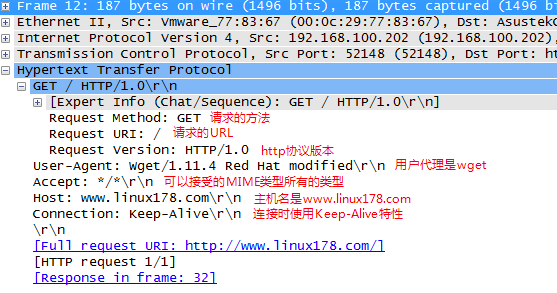
以上的报文是HTTP请求报文。
URI Uniform Resource Identifier 统一资源标识符 URL Uniform Resource Locator
统一资源定位符 格式如下: scheme://[username:password@]HOST:port/path/to/source
http://www.magedu.com/downloads/nginx-1.5.tar.gzURN Uniform Resource Name 统一资源名称
URL和URN 都属于 URI
为了方便就把URL和URI暂时都同指一个东西
下面是Chrome发起的http请求报文头部信息
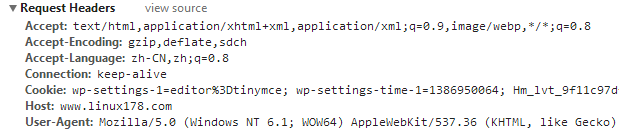
Accept 就是告诉服务器端,我接受那些MIME类型
Accept-Encoding 这个看起来是接受那些压缩方式的文件
Accept-Lanague 告诉服务器能够发送哪些语言
Connection 告诉服务器支持keep-alive特性
Cookie 每次请求时都会携带上Cookie以方便服务器端识别是否是同一个客户端
Host 用来标识请求服务器上的那个虚拟主机,比如Nginx里面可以定义很多个虚拟主机
那这里就是用来标识要访问那个虚拟主机。
User-Agent 用户代理,一般情况是浏览器,也有其他类型,如:wget curl 搜索引擎的蜘蛛等
条件请求首部:
If-Modified-Since 是浏览器向服务器端询问某个资源文件如果自从什么时间修改过,那么重新发给我,这样就保证服务器端资源
文件更新时,浏览器再次去请求,而不是使用缓存中的文件
安全请求首部:
Authorization: 客户端提供给服务器的认证信息;
四、服务器端响应http请求,浏览器得到html代码
看下图 第12号包是http请求包,第32包是http响应包
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
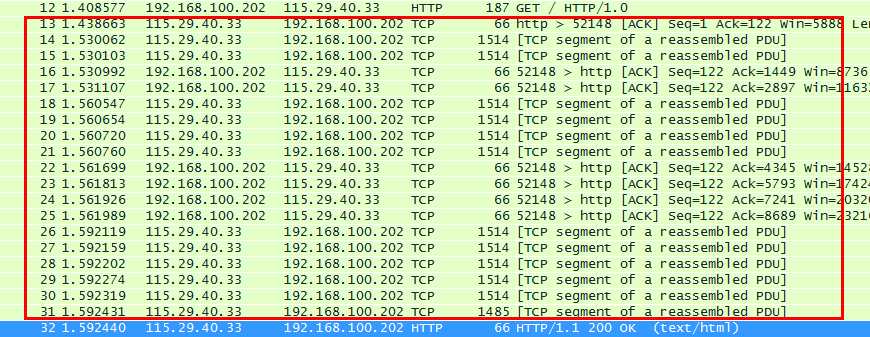
第32号包 是服务器返回给客户端http响应包(200 ok 响应的MIME类型是text/html),代表这一次客户端发起的http请求已成功响应。200 代表是的 响应成功的状态码,还有其他的状态码如下:
1xx: 信息性状态码
100, 101
2xx: 成功状态码
200:OK
3xx: 重定向状态码
301: 永久重定向, Location响应首部的值仍为当前URL,因此为隐藏重定向;
302: 临时重定向,显式重定向, Location响应首部的值为新的URL
304:Not Modified 未修改,比如本地缓存的资源文件和服务器上比较时,发现并没有修改,服务器返回一个304状态码,
告诉浏览器,你不用请求该资源,直接使用本地的资源即可。
4xx: 客户端错误状态码
404: Not Found 请求的URL资源并不存在
5xx: 服务器端错误状态码
500: Internal Server Error 服务器内部错误
502: Bad Gateway 前面代理服务器联系不到后端的服务器时出现
504:Gateway Timeout 这个是代理能联系到后端的服务器,但是后端的服务器在规定的时间内没有给代理服务器响应服务器端接收到http请求后是怎么样生成html文件?
假设服务器端使用nginx+PHP(fastcgi)架构提供服务
1 nginx读取配置文件
2 把php文件交给fastcgi进程去处理
注1:nginx是怎么找index.php文件的?
当nginx发现需要/web/echo/index.php文件时,就会向内核发起IO系统调用(因为要跟硬件打交道,这里的硬件是指硬盘,通常需要靠内核来操作,而内核提供的这些功能是通过系统调用来实现的),告诉内核,我需要这个文件,内核从/开始找到web目录,再在web目录下找到echo目录,最后在echo目录下找到index.php文件,于是把这个index.php从硬盘上读取到内核自身的内存空间,然后再把这个文件复制到nginx进程所在的内存空间,于是乎nginx就得到了自己想要的文件了。
注2:寻找文件在文件系统层面是怎么操作的?
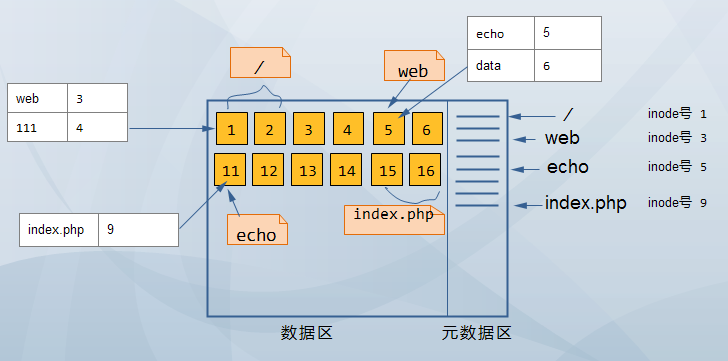
比如nginx需要得到/web/echo/index.php这个文件
每个分区(像ext3 ext3等文件系统,block块是文件存储的最小单元 默认是4096字节)都是包含元数据区和数据区,每一个文件在元数据区都有元数据条目(一般是128字节大小),每一个条目都有一个编号,我们称之为inode(index node 索引节点),这个inode里面包含 文件类型、权限、连接次数、属主和数组的ID、时间戳、这个文件占据了那些磁盘块也就是块的编号(block,每个文件可以占用多个block,并且block不一定是连续的,每个block是有编号的),如下图所示:
五、浏览器解析html代码,并请求html代码中的资源
一次完整的HTTP事务是怎样一个过程?浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。














 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









