








scrapy是个好东西,它的官方文档写的很详细,很适合入门。链接:http://scrapy-chs.readthedocs.io/zh_CN/1.0/index.html
记录点东西免得以后自己忘记。网上scrapy教程一搜一大把,只记录一些认为比较重要的学习思路。有什么技术问题欢迎留言评论!
1. 创建工程注意事项
框架结构和django蛮像的,一眼就能看个大概。其中setting.py在之后的用处很大,LOG_LEVEL并没有默认写在里面,默认是LOG_LEVEL= ‘DEBUG’, 每次运行爬虫输出很多信息,一开始很有用,毕竟还不熟悉,到了后来,每次都输出抓取到的list显得太繁琐了,可以改成LOG_LEVEL= ‘INFO‘, ’WARNING‘ ’ERROR‘,我现在一般放在INFO
以下几个在一开始学习时可以先设置为以下设置
DOWNLOAD_DELAY = 5(防封,一般2就足够)
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'(防封)
2.scrapy shell
对于我来说,shell最大的用处是测试xpath和re是否抓对,其他功能还没怎么接触。
在终端里输入:scrapy shell "www.baidu.com" (不带引号也可以,但对一些特殊符号的网址最好带引号,不然会出错)
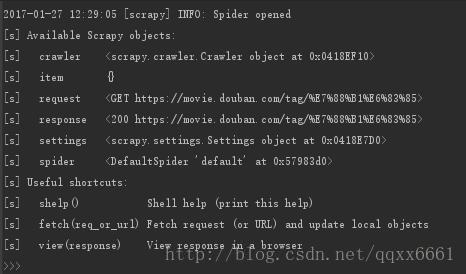
运行后的一些指令:
response.body: 查看网页整个源代码
response.xpath: 用xpath找出符合的list

respose.xpath().re(): xpath后混合re(复杂的网页用得比较多)

在scrapy shell中确定好匹配式方便之后直接码代码。
3.xpath
详细教程可以看: http://www.w3school.com.cn/xpath/index.asp
用xpath有偷懒办法,就是用类似chrome的浏览器开发者工具(很多其他浏览器基本都有,搜狗等),在待抓取网页按F12,或者直接选取想提取的文字,右键审查元素。
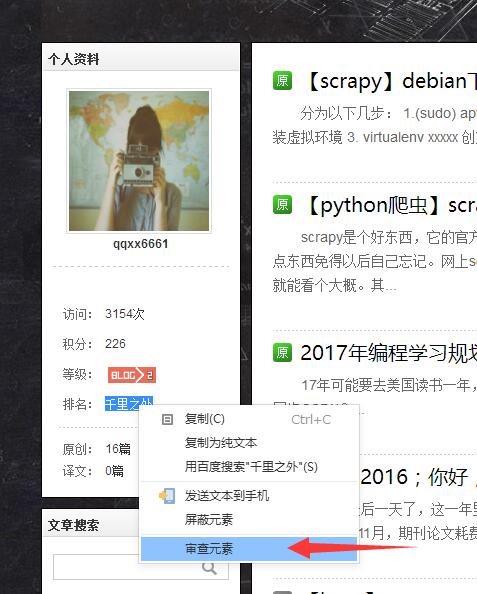
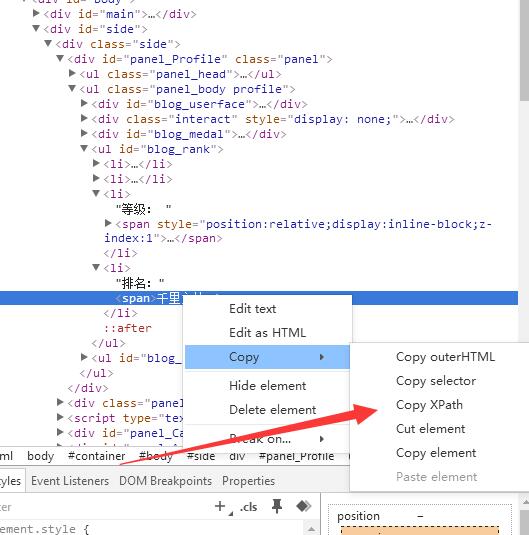
如上网页抓出来后(千里之外)是://*[@id="blog_rank"]/li[4]/span
其实这样的li[4]不太好,最好使用其它标签属性抓取,不然有时候网页的显示顺序变化后,比如有时候缺少一个标签(豆瓣电影就这样,都是泪)这样的依靠位置抓取很不靠谱。所以尽量找别的属性抓,例如可以靠“排名:”正则匹配一下。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









