







1、简介
大家熟知的PCA算法是一种无监督的降维算法,其在工作过程中没有将类别标签考虑进去。当我们想在对原始数据降维后的一些最佳特征(与类标签关系最密切的,即与 y 相关),这个时候,基于Fisher准则的线性判别分析LDA就能派上用场了。注意,LDA是一种有监督的算法。
本文参考“JerryLead”的文章线性判别分析(Linear Discriminant Analysis)(一)及线性判别分析(Linear Discriminant Analysis)(二)。
2、LDA算法(二类情况)
给定特征为
现在我们想将
d
维特征降到只有一维,而又要保证类别能够“清晰”地反映在低维数据上,也就是这一维就能决定每个样例的类别。这里的降维可以通过将样本点投影到一个低维平面上来实现。在这里为了简单起见,我们设样例为二维的,也就是
样例
我们的目的是寻找一条从原点出发方向为$w$的直线,可以将投影后的样例点很好的分离,大概如下图所示:
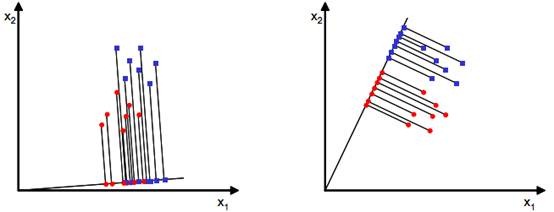
从直观上来讲,第二条直线看起来还不错,可以很好地将两类样例分离,那这条直线是不是我们所要找的最佳的直线呢?要回答这个问题,我们就要从定量的角度来确定最佳的投影直线,即直线的方向向量 w 。
首先求每类样例的均值(中心点):
那么投影后的每类样例的均值(中心点)为: μi~=1Ni∑y∈wiy=1Ni∑x∈wiwTx=wTμi
从上面两条公式可以看出,投影后的中心点就是中心点的投影。
从上面两张图可以看出,能够使投影后的两类样本中心点尽量分离的直线是好的直线,定量表示就是: maxwJ(w)=|μ1~−μ2~|=|wTμ1−wTμ2| 。但是仅仅考虑 J(w) 是不行的,如下图所示:
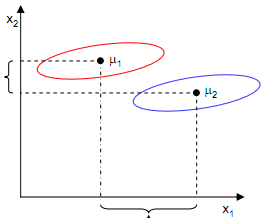
尽管在 x1 轴上取得了中心点投影的最大间距,但是由于重叠严重,反而不能很好的分离两类样本点。中心点投影在 x2 轴上的间距虽然很小,但是却能够取得比 x1 轴更好的分离效果。这是为什么呢?
LDA是基于Fisher准则的算法,其必须同时遵从类内密集,类间分离这两个条件。中心点投影间距最大化只是满足类间分离而没有考虑类内密集,所以为了获得最佳的投影方向 w ,我们还要将同一类样例的类内密集度做为一个约束,在这里,我们采用散列值(scatter)作为密集度的一个度量。
每个类别的散列值定义如下:
有了散列值,我们得以满足Fisher准则的类内密集的要求,结合最大化中心点的投影间距,我们可以提出最终的度量公式: maxwJ(w)=|μ1~−μ2~|2s1~2+s2~2 。
将散列值的公式展开可得:
si~2=∑y∈wi(y−μi~)2=∑x∈wi(wTx−wTμi)2=∑x∈wiwT(x−μi)(x−μi)Tw
令 Si=∑x∈wi(x−μi)(x−μi)T , Sw=S1+S2
则 si~2=wTSiw , s1~2+s2~2=wTSww ,分母部分完毕,接下来处理分子部分。
展开分子, (μ1~−μ2~)2=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw
令 SB=(μ1−μ2)(μ1−μ2)T ,则 (μ1~−μ2~)2=wTSBw ,分子部分完毕。
度量公式可表示为: maxwJ(w)=wTSBwwTSww
在我们求导之前,需要对分母进行归一化,因为不做归一的话,
w
扩大任何倍,都成立,我们就无法确定
c(w)=wTSBw−λ(wTSww−1)
dcdw=2SBw−2λSww=0
SBw=λSww
若
Sw
可逆,则
S−1wSBw=λw
,即
w
是矩阵
上面这个式子还可以进一步化简:
代入原式可得:
S−1wSBw=S−1w(μ1−μ2)∗λw=λw
,由于对
w
扩大缩小任何倍不影响结果,因此可以约去两边的未知常数
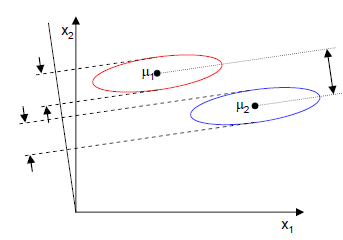
上面那张图的投影结果如下图所示:
3、LDA算法(多类情况)
在二类情况下,J(w)的分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。除却这个变化,其他推导与二类情况相似,这里不做展开说明。具体情况可以参照线性判别分析(Linear Discriminant Analysis)(一)。
4、实例
三维投影到二维平面:
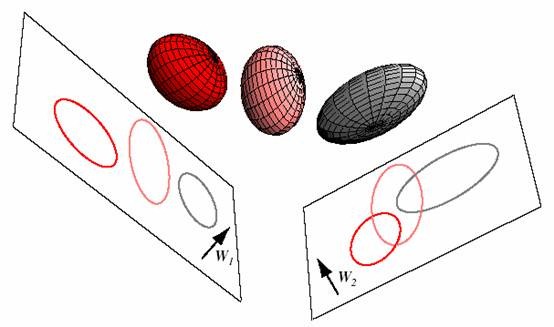
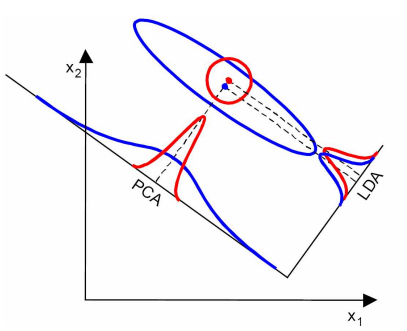
LDA与PCA的对比,PCA选择样本点投影具有最大方差的方向,LDA选择分类性能最好的方向:
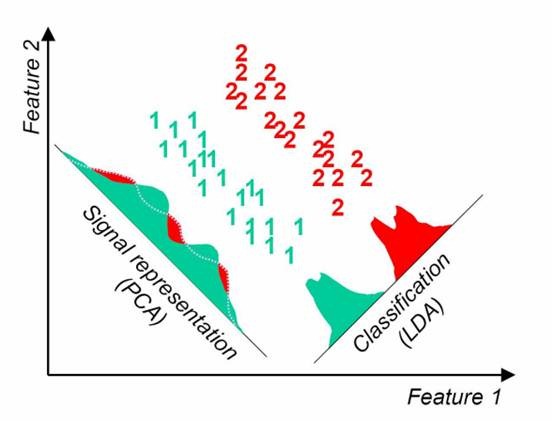
5、使用LDA的一些限制
本部分内容完全由“JerryLead”总结。
1. LDA至多可生成C-1维子空间。LDA降维后的维度区间在
[1,C−1]
,与原始特征数
n
<script type="math/tex" id="MathJax-Element-6">n</script>无关,对于二值分类,最多投影到1维。
2. LDA不适合对非高斯分布样本进行降维。下图中红色区域表示一类样本,蓝色区域表示另一类,由于是2类,所以最多投影到1维上。不管在直线上怎么投影,都难使红色点和蓝色点内部凝聚,类间分离。
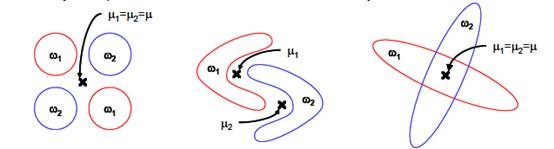
3. LDA在样本分类信息依赖方差而不是均值时,效果不好。下图中样本点依靠方差信息进行分类,而不是均值信息。LDA不能够进行有效分类,因为LDA过度依靠均值信息。
- LDA可能过度拟合数据。














 1857
1857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









