







无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。教程链接:https://www.cbedai.net/qtlyx
和线性回归一样,我们对参数是要做检验的。不是回归出了什么方程,什么系数我们就认了。如果回归学的好的话,我们还会记得,在多元归中,我们有一个F检验,用来检验是否所有因子前面的回归系数是显著的,只要有一个显著,F检验就会拒绝零假设。
在自回归中,我们也要对回归的显著性做一个假设。时间序列的自回归检验通常有两种:Box-Pierce 与 Box-Ljung。两个大致一样,唯一的区别就是后者更加适合小样本。如果你的样本比较少,那么用后面一个比较好。在R中,我们检验一下之前的那个序列。
#example 4
Box.test(yt)
Box.test(yt,type = 'Ljung-Box')检验的结果如下:
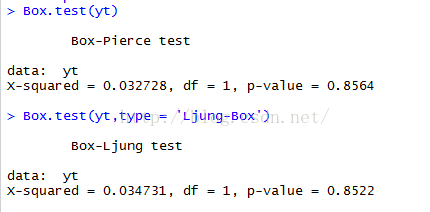
如何看这些检验结果呢?我们只要记住,这些检验方法和F检验一下,零假设都是所有相关性都是不显著的,也就是所有系数都是零。同时,P-value越小越拒绝。这里,P-value都很大,至少大于0.05,对应95%的显著性水平下,我都不能拒绝零假设,换句话说,我们不能说,存在显著的自回归关系。
很显然,我们是随机产生的时间序列,所以是这个结果是正确的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











