







内容来自Andrew老师课程Machine Learning的第六章内容的Bias vs. Variance部分。
一、Diagnosing Bias vs. Variance(诊断偏差 vs. 方差)
如果一个算法表现的不理想,多半是出现两种情况,一种情况是偏差比较大(这种情况是欠拟合情况),另一种是方差比较大(这种情况是过拟合的情况)。下图是欠拟合、刚好、过拟合三种情况的Size-price图(仍然是预测房价的示例)。
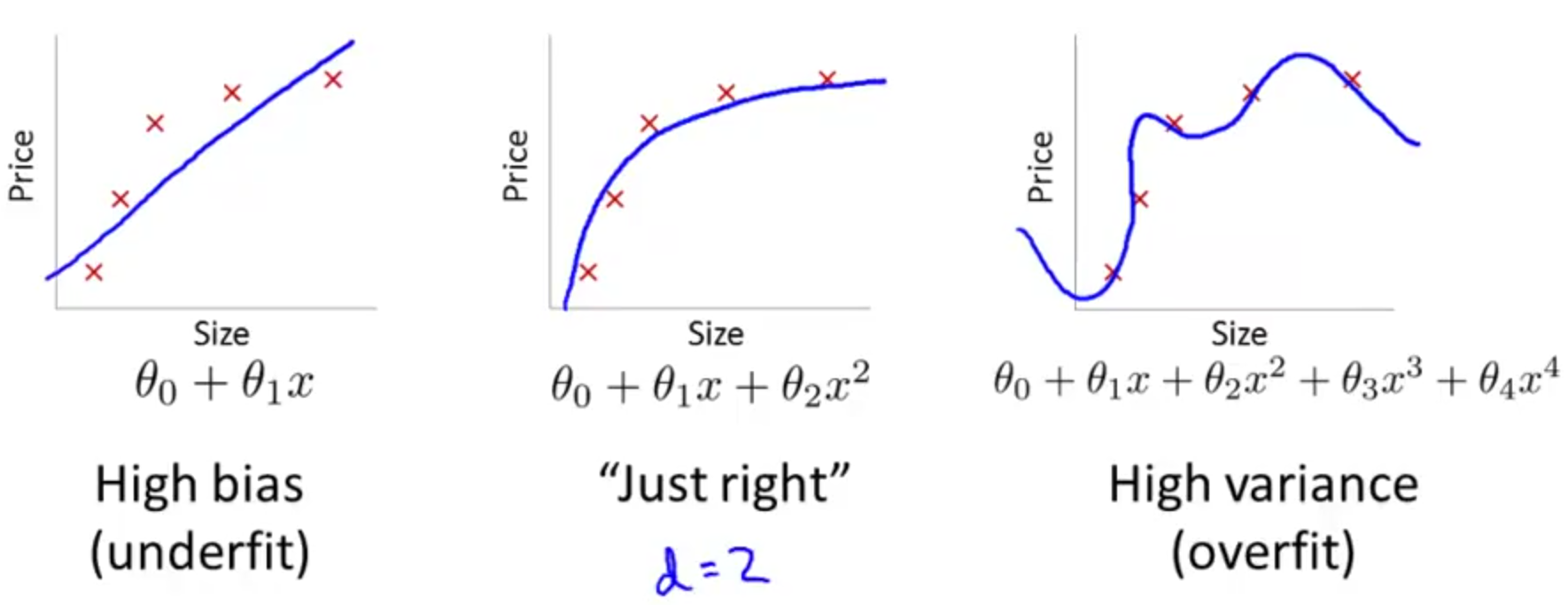
那么,多项式的次数对cv误差的影响是什么呢?
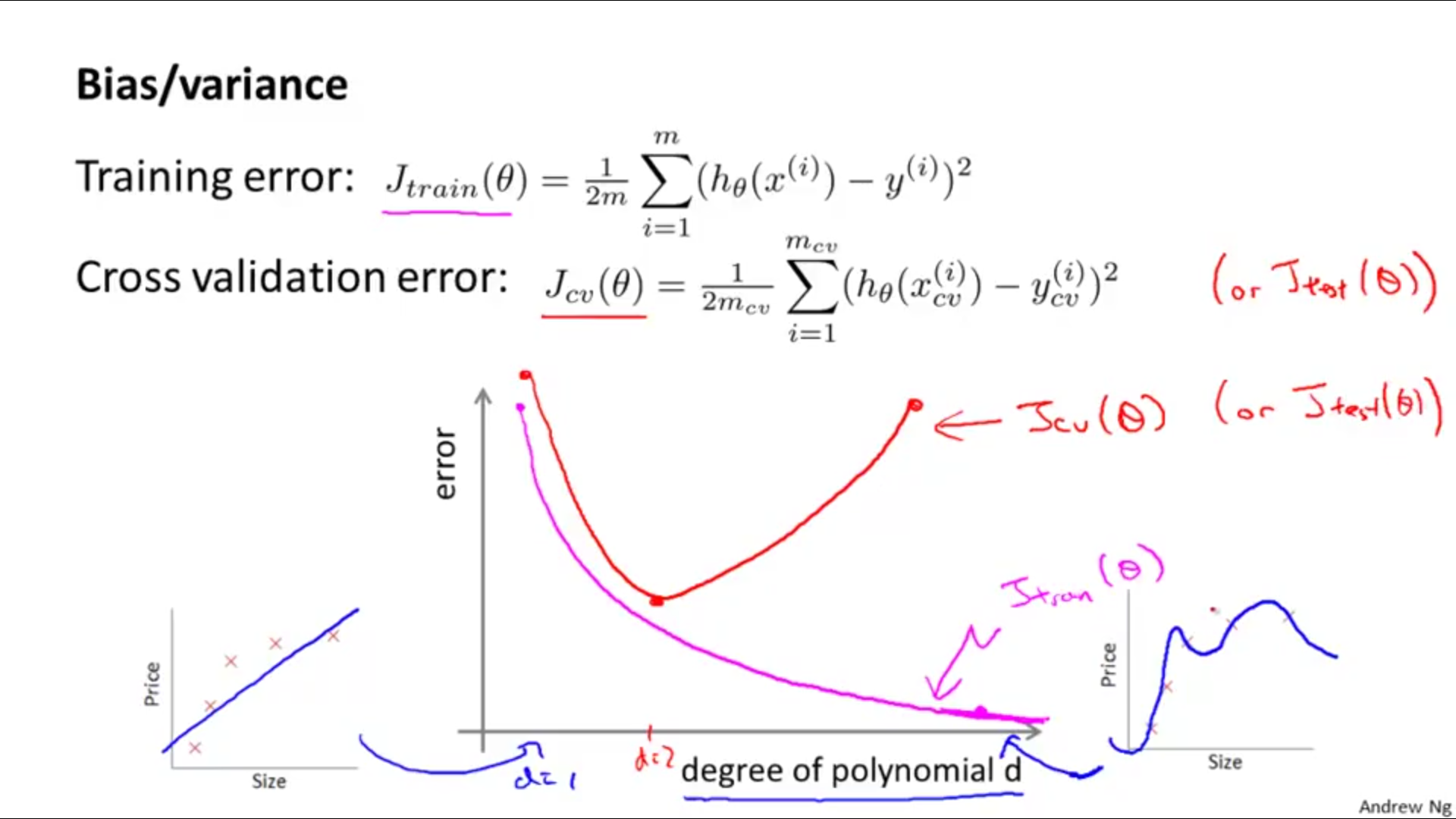
上图展示了训练误差、验证误差的公式,以及对欠拟合和过拟合一个直观上的分析,最简单的情况就是看最左边和最右边的图形,这有助于理解整个d-error曲线。关于在这个曲线上哪些地方是欠拟合,哪些地方是过拟合,见下图:
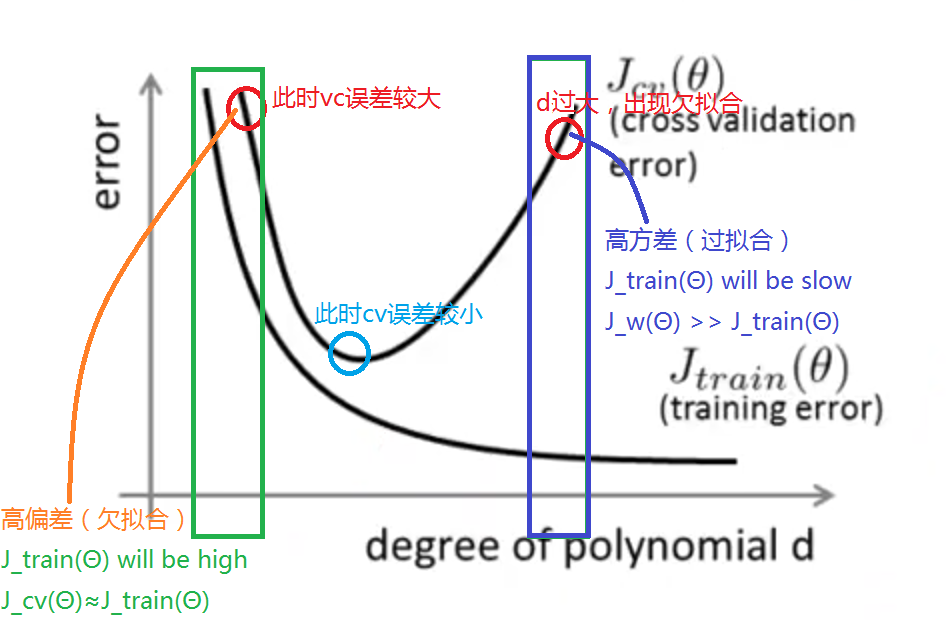
上图圈出了对应区域可能出现欠拟合和过拟合的情况,随着d的增大:J_train(Θ)不断减小,J_cv(Θ)先减小再增加。蓝色圈出的地方(cv误差较小的地方)maybe是d的最优值。
在欠拟合(高偏差)情况下:J_train(Θ)比较高,并且J_cv(Θ)≈J_train(Θ);
在过拟合(高方差)情况下:J_train(Θ)比较低,但是J_cv(Θ)比较高,J_cv(Θ) >> J_train(Θ)。
二、Regularization and Bias/Variance(正则化以及偏/方差)
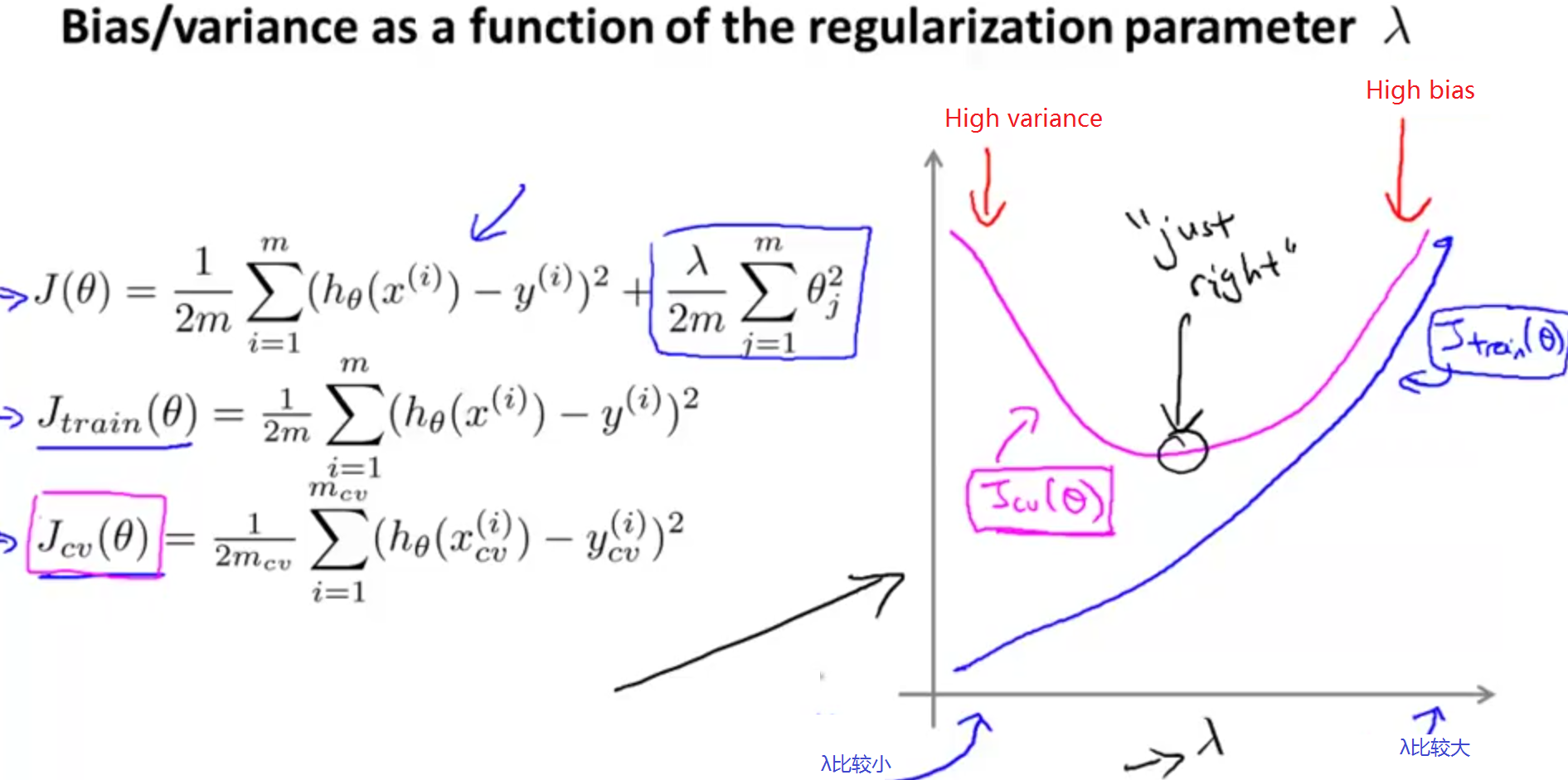
算法正则化能够通过控制λ的值,使参数Θ尽可能地小,这样可以有效防止过拟合问题的发生,那么,正则化和算法的方差/偏差到底有什么关系呢?正则化系数λ的大小对方差/偏差的影响是什么呢?
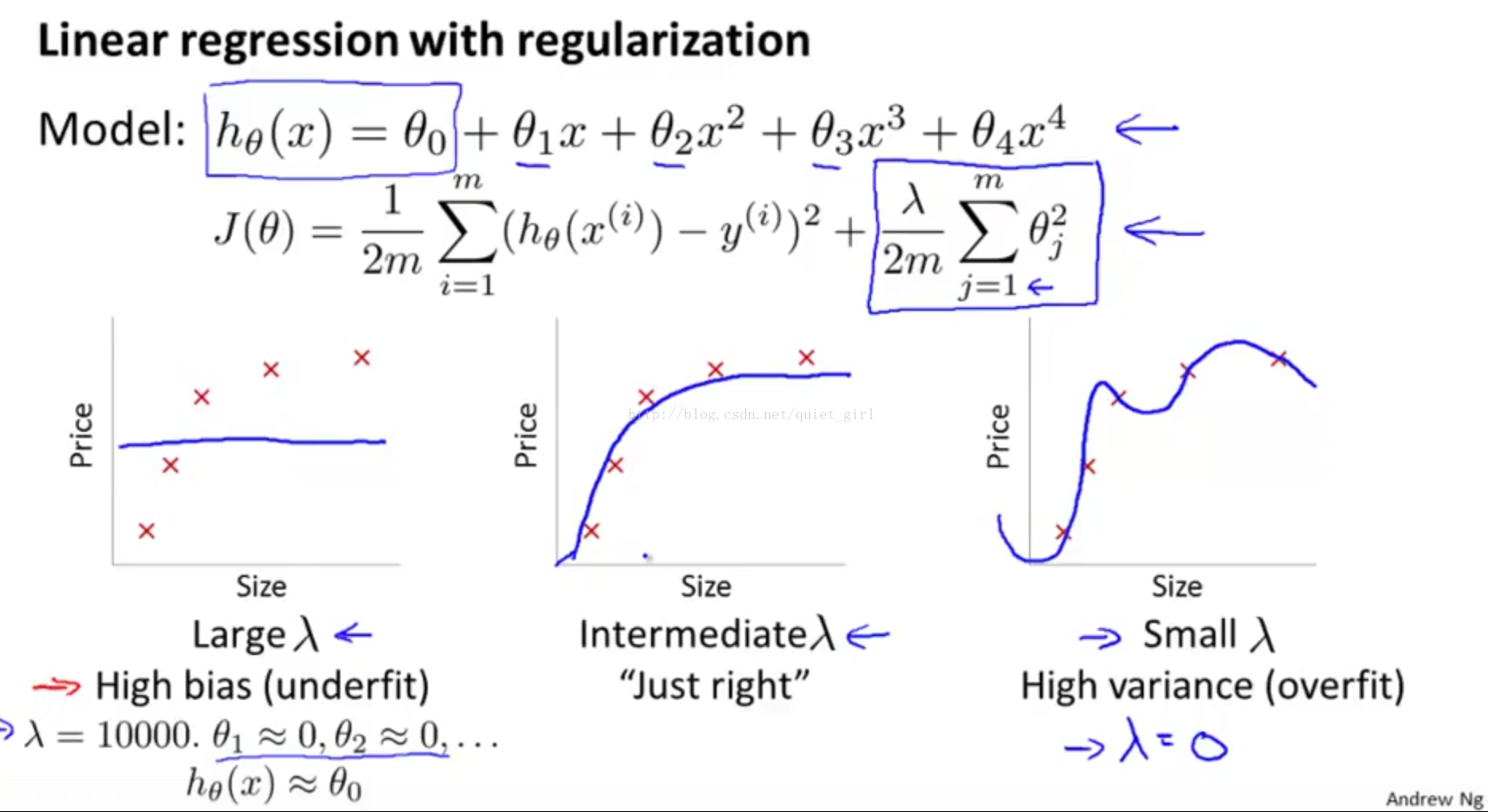
由上图可知,当λ非常大的时候,对Θ的压缩也比较大,使得θ1、θ2、......、θn都≈0(记住,θ0没有被压缩),因此h(x)≈θ0,即h(x)是一条直线,在这种情况下,会出现欠拟合的现象,若最左侧的图;中间的图形是比较合适的λ,这种情况下拟合效果"Just right";最右侧的图是过拟合的情况,在这种情况下,λ的值较小。
正则化参数λ对J_train(θ)曲线和J_cv(θ)曲线的有什么影响呢?
In order to choose the model and the regularization term λ, we need to:
- Create a list of lambdas (i.e. λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24});
- Create a set of models with different degrees or any other variants.
- Iterate through the λ s and for each λ go through all the models to learn some Θ .
- Compute the cross validation error using the learned Θ (computed with λ) on the JCV(Θ) without regularization or λ = 0.
- Select the best combo that produces the lowest error on the cross validation set.
- Using the best combo Θ and λ, apply it on Jtest(Θ) to see if it has a good generalization of the problem.
三、Learning Curves(学习曲线)
本部分主要分析三张图的曲线,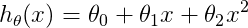 、
、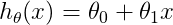 和
和 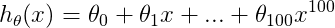 对应的学习曲线及其分析。
对应的学习曲线及其分析。
、和 对应的学习曲线及其分析。
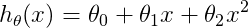 的学习曲线
的学习曲线
由右侧图形可知,随着训练集样本数的增加,二次函数拟合的效果越来越差,即训练误差越来越高。而随着训练样本数的增加,验证误差/测试误差越来越小,即当m足够大时,cv error(test error)≈train error。
(二)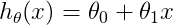 的学习曲线
的学习曲线
的学习曲线
上图的学习曲线是高偏差(high bias)的情况,在这种情况下:
(1)当m较小时,train error较小,cv error(test error)非常大
(2)当m较大时,train error≈cv error(test error),这是由于在接近找到最好的拟合函数时,train error和cv error(test error)趋于平稳。
以上表明:当学习算法出现高偏差时,使用更多的训练数据集不会有太大的帮助。
(三)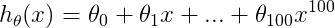 的学习曲线
的学习曲线
的学习曲线
上图的学习曲线是高方差(high variance)的情况,在这种情况下:
(1)当m较小时,train error较小,cv error(test error)非常大
(2)当m较大时,仍然存在train error < cv error(test error),train error和cv error(test error)之间有一定的距离。但是两者都越来越接近于desired performance曲线。
以上表明:当学习算法出现高方差时,使用更多的训练数据集可能会有帮助。
四、Deciding What to Do Next Revisited(决定下一步做什么)
当我们实现了预测模型,但是在使用它进行预测的时候,发现其效果并不是很好,我们可能会想到一下几种解决方法。

通过绘制学习曲线我们可以观察到模型是出现高方差还是高偏差,那么上面的几种解决方法是高偏差的时候使用还是高方差的时候使用呢?我们有如下总结:

上述问题对应的是在线性回归中的一些情况,在神经网络中什么时候会出现过拟合什么情况会出现欠拟合呢?如下图:
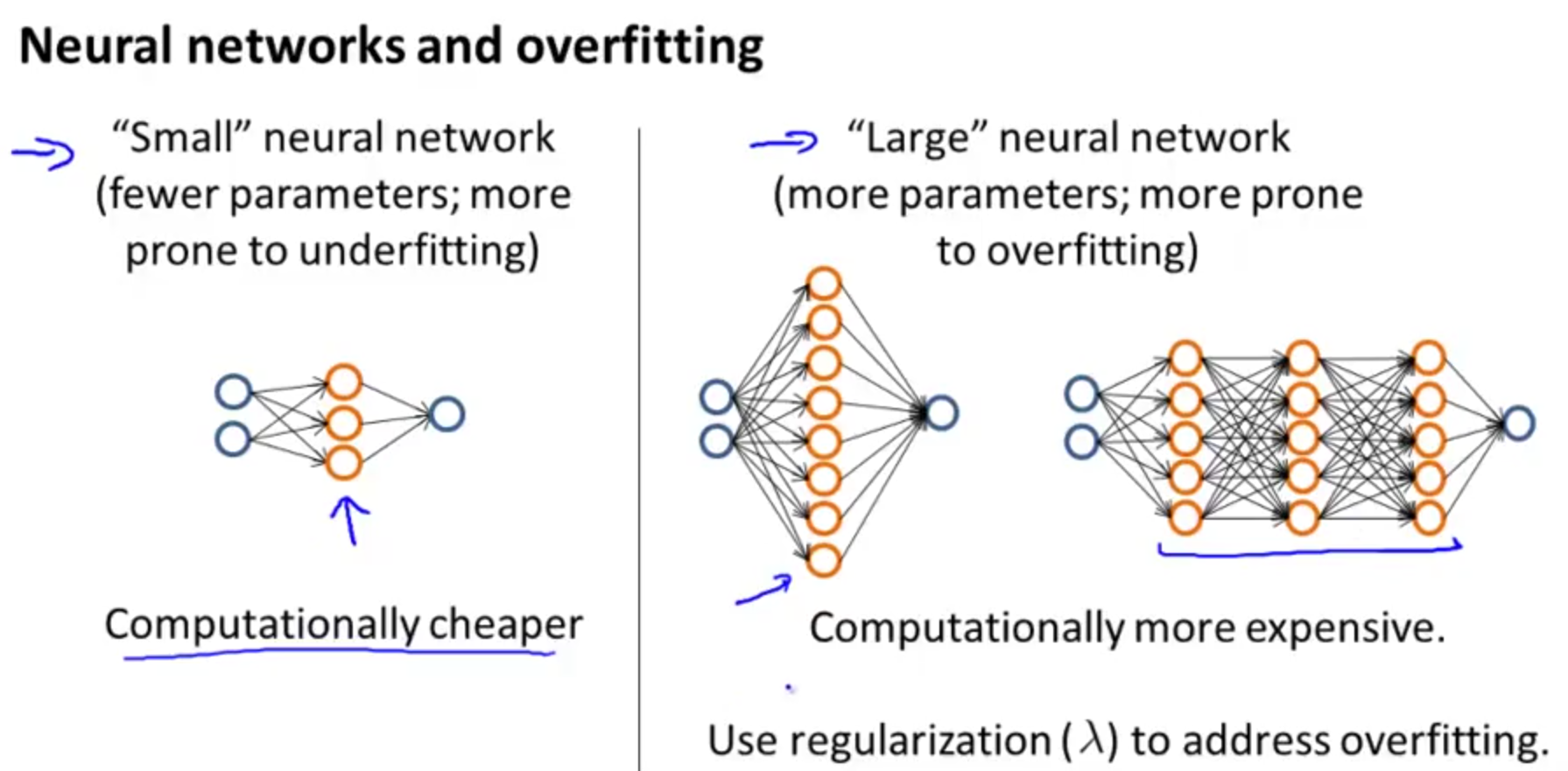
在神经网络的架构中,默认情况下是使用一个隐藏层,若需要使用多个隐藏层,则需要尝试1层、2层、3层......,找到使得交叉验证误差较小的层数值。














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









