







BP
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
一个神经网络的结构示意图如下所示。
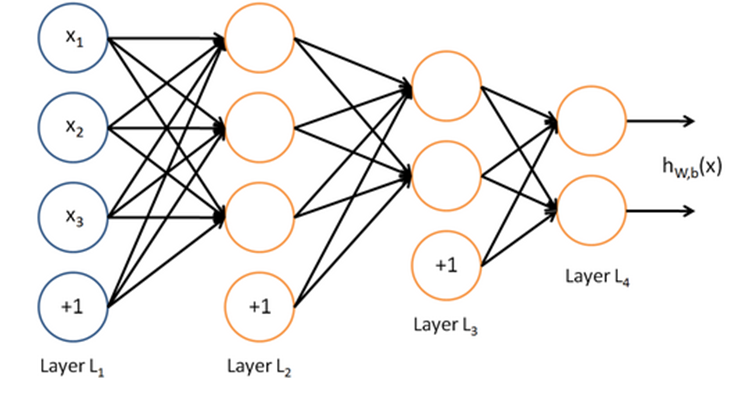
一个四层的神经网络
输入层:三个神经元
隐含层1:三个神经元
隐含层2:两个神经元
输出层:两个神经元
前馈阶段
网络中突触的权值是固定的,输入信号在网络中一层一层的传播,直到输出端。
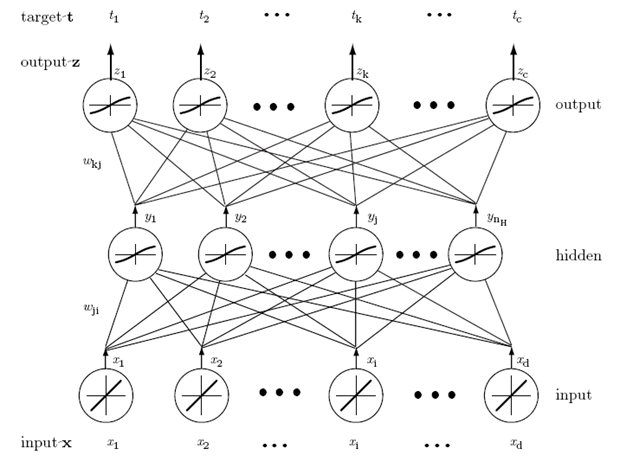
对某层
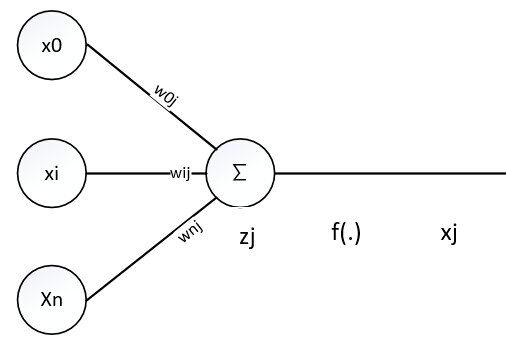
神经元输入结点:
其中x0=1 ,w0j可以理解为偏置
第l层神经元结点i到神经元结点j权值是
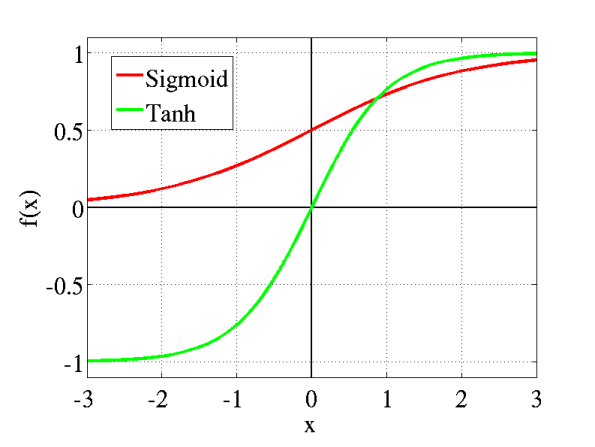
激活函数一般选:
sigmoid激活函数:
值域:[0,1]
其导数:
tanh激活函数:
值域:[−1,1]
其导数:
f′(x)=1−f(x)2
两个函数的图像:
根据上面的一个图,前馈过程就是:
zj=∑i=ni=0wijxj
xj=f(zj)
这样一层一层的向前递归下去
反馈阶段
反馈阶段是利用训练误差,更新各层神经元权值
先说明下这里反馈阶段更新权值每次是利用一个训练样本数据更新权值
对某一个样本x,其各维数据值:
设该BP神经网络共有L层
第
第l层的神经元数:
第l层第i个神经元的加权和:
输出层输出值:y0,y1,...,ySL
输出层期望值(也就是该样本数据的真实值):d0,d1,...,dSL−1
对该样本x的输出层第j神经元的训练误差:
对该样本x的输出层所有神经元的平方误差:
其中:
yj=f(z(L)j)
z(L)j=∑i=SLi=0w(L)ijx(L)i
好的模型应该是输出层神经元的平方误差最小
这里我们需要求的参数只有wlij,下面可以利用梯度下降法或者拟牛顿法进行求解。利用梯度下降法需要计算E对
下面利用梯度下降法进行求解
我们知道需要计算E对
隐含层到输出层
当l==L时,也就是说是隐含层到输出层,需要求的是输出层各神经元的权值矩阵wL
网络结构可以简单描述为:
E对
其中:
∂E∂ej=ej
∂ej∂yj=−1
∂yj∂z(L)j=f′(z(L)j)
∂z(L)j∂w(L)ij=x(L)i
所以:
在许多论文书籍中往往定义神经元j的敏感度
第l层第
也就是,输出层平方误差对神经元j的加权和的偏导数的负数
对输出层L第
所以:
利用梯度下降法更新w(L)ij
或者直接写出:
其中:
η是学习率
δ(L)j是第L层输出神经元
x(L)i表示第L层输入神经元
δ(L)j=ejf′(zLj)=(dj−yj)f′(zLj)
n表示迭代次数
隐含层到隐含层
当
当l=L−1,这是倒数第二层,其下一层就是输出层
其网络结构:
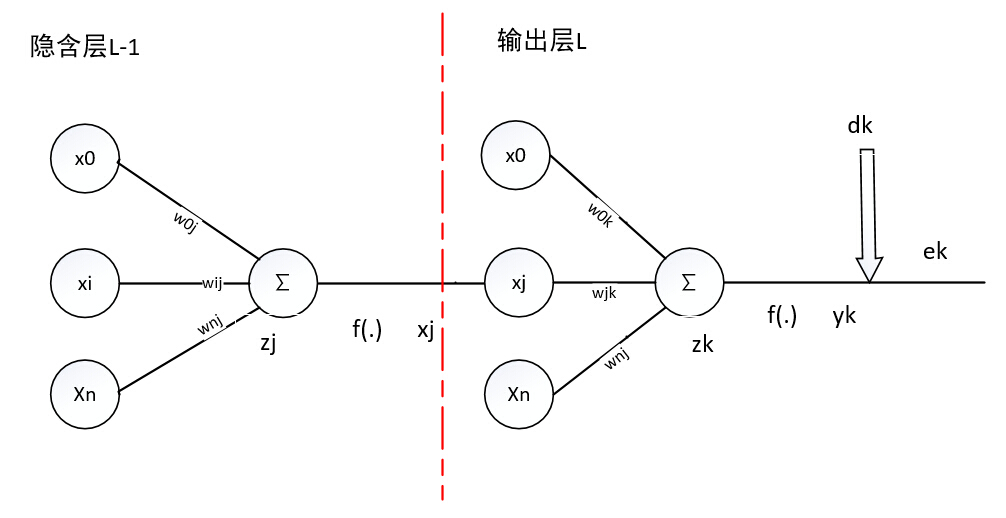
请忽略图中明显的不足、错误之处
各参数:
第L−1层神经元i到神经元j的权值wL−1ij
第L−1层神经元j的加权和:
z(L−1)j=∑i=SL−1i=0w(L−1)ijx(L−1)i
第L−1层神经元j的敏感度:
第L−1层神经元数:SL−1
第L层神经元j到神经元k的权值
第L层神经元
z(L)k=∑j=SLj=0w(L−1)jkx(L)j
第L层神经元
第L层神经元数:
第L层神经元
yk=f(z(L)k)
第L层神经元
第L层神经元的平方误差:
E对
下面分别对上面的链式法则中的各项进行求解
∂z(L−1)j∂w(L−1)ij=x(L−1)i
δ(L−1)j的求解,根据上面简单网络模型和链式法则进行求解
先看下面的图
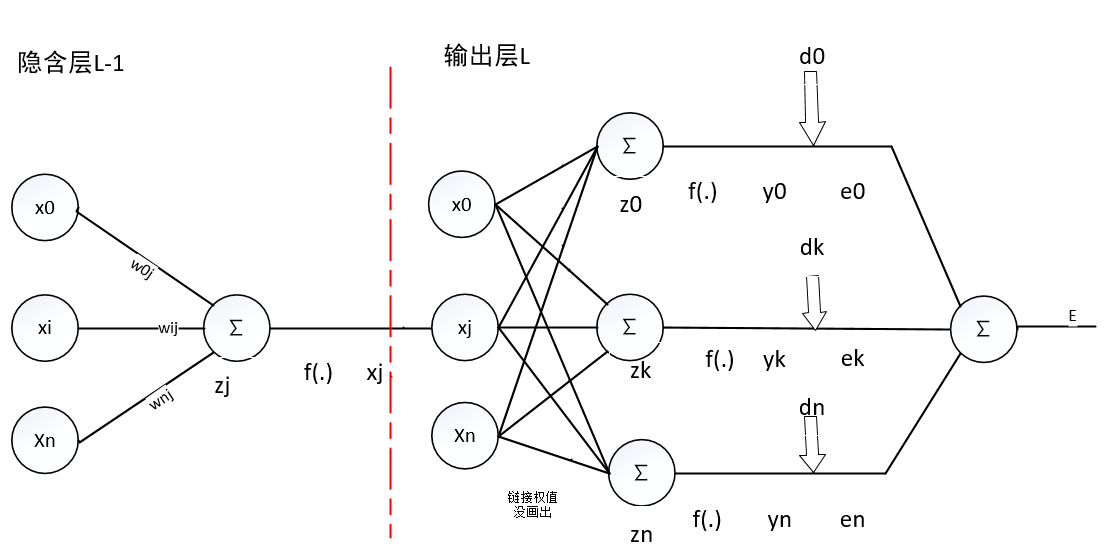
<图中不足之处请见谅>
我们需要求δ(L−1)j=−∂E∂z(L−1)j
利用链式法则需要对ek,yk,z(L)k,x(L)j,z(L−1)j求导
我们发现x(L)j对该层的所有加权和都产生了影响,加权和又对yk,(k=0,1,SL)产生了影响,一直到所有的ek,(k=0,1,2,...n),最后累加到E,所以这个求导要分别对
δ(L−1)j=−∂E∂z(L−1)j=−∑k=SLk=0∂E∂ek
对ek进行链式求导法则
δ(L−1)j=−∂E∂z(L−1)j=−∑k=SLk=0∂E∂ek∂ek∂yk∂yk∂z(L)k∂z(L)k∂x(L)j∂x(L)j∂z(L−1)j=−∑k=SLk=0ek(−1)f′(z(L)k)w(L−1)jkf′(z(L−1)j)=f′(z(L−1)j)∑k=SLk=0ekf′(z(L)k)w(L−1)jk=f′(z(L−1)j)∑k=SLk=0δ(L)kw(L−1)jk
利用梯度下降法更新w(L−1)ij
或者直接写出:
其中:
η是学习率
δ(L−1)j是第L−1层输出神经元j的敏感度
根据上面可以得出规律,对于l层,隐含层之间利用梯度下降法更新权值系数公式:
其中:
η是学习率
δ(l)j是第l层输出神经元
x(l)i表示第l层输入神经元
δ(l)j=f′(z(l)j)∑k=Sl+1k=0δ(l+1)kw(l)jk
总结
第l层神经元之间的权值系数:
当l==L也就是隐含层到输出层:
当l<=L−1也就是隐含层之间:
为了防止出现振荡问题,一种改进的权值修正方法:
其中:
α是动量系数,通常取0.2-0.8
对于上面的式子,在一些书中可能形式不一样
BP伪代码:
参数:隐含层数量,隐含层大小,动量系数,学习率
随机初始化各个权值系数
对每个训练样本数据进行训练:
前馈阶段:
利用输入值,权值系数,进行逐步迭代,直到最后输出层
反馈阶段:
利用训练误差,逐步向后更新权值系数
当到达最大迭代次数的时候停止更新
自己整理,符号表示比较复杂,有上标也有下标,还有中标,如有错误请指出

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









