









KNN原理及优缺点
KNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
算法原理是,从训练集中找到和新数据距离最接近的k条记录,然后根据这K条记录的分类来决定新数据的类别。所以Knn的关键是,训练集与测试集、距离或相似的衡量、k的大小及分类决策规则。一旦他们确定了,则结果就确定了。常用的距离度量公式是欧氏距离,K值的选择反映了对近似误差与估计误差之间的权衡,K值的选择会对结果产生重大的影响,通常由交叉验证选择最优的K值。
KNN算法的优点:
简单,易于理解,易于实现,无需估计参数,无需训练; 适合对稀有事件进行分类;特别适合于多分类问题, kNN比SVM的表现要好
缺点:懒惰算法,对测试样本分类时的计算量大,内存开销大(我自己够用)
KNN的python实现
#-*- coding: utf-8 -*-
from numpy import *
import operator
'''从文件中读取数据,将文本记录转换为矩阵,提取其中特征和类标'''
def filematrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines) #得到文件行数
returnMat=zeros((numberOfLines,7)) #创建以零填充的numberOfLines*7的NumPy矩阵
classLabelVector=[]
index=0
for line in arrayOLines: #获取数据,获取特征矩阵
line=line.strip()
##文本分割
listFromLine=line.split('\t')
# print(listFromLine[1:8])
##获取X
returnMat[index, : ]=listFromLine[1:8]
##获取标签Y
classLabelVector.append(listFromLine[-1])
index+=1
return returnMat,classLabelVector #返回特征矩阵和类标集合
'''归一化数字特征值到0-1范围,防止特大值与特小值的影响'''
'''输入为特征值矩阵'''
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet, ranges, minVals
def classify(sample,dataSet,labels,k):
dataSetSize=dataSet.shape[0] #数据集行数即数据集记录数
'''距离计算'''
diffMat=tile(sample,(dataSetSize,1))-dataSet #样本与原先所有样本的差值矩阵
sqDiffMat=diffMat**2 #差值矩阵平方
sqDistances=sqDiffMat.sum(axis=1) #计算每一行上元素的和
distances=sqDistances**0.5 #开方
sortedDistIndicies=distances.argsort() #按distances中元素进行升序排序后得到的对应下标的列表(索引值)
'''选择距离最小的k个点'''
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
'''从大到小排序'''
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def ClassTest():
hoRatio=0.20 #测试样例数据比例
datingDataMat,datingLabels=filematrix('user_info_and_topic_5topicand50word.txt')
#将测试集数据标准化,转化为0-1之间
normMat, ranges, minVals=autoNorm(datingDataMat)
##样本总数目
m =normMat.shape[0]
##测试集的数目
numTestVecs=int(m*hoRatio)
precisionCount=0.0
##运行时,设置K的数目来调解算法的准确率
k=35
##对测试集一个一个与训练集算距离
for i in range(numTestVecs):
classifierResult=classify(normMat[i, : ],normMat[numTestVecs:m, : ], datingLabels[numTestVecs:m],k)
print("The classifier came back with: %s, the real answer is: %s" % (classifierResult, datingLabels[i]))
##如果真实类别的和预测的类别相同,则加1
if(classifierResult == datingLabels [i] ) :
precisionCount += 1.0
print("the total precision rate is: %f" % (precisionCount/float(numTestVecs)))
def main():
ClassTest()
if __name__=='__main__':
main()
KNN的python代码中的数据格式
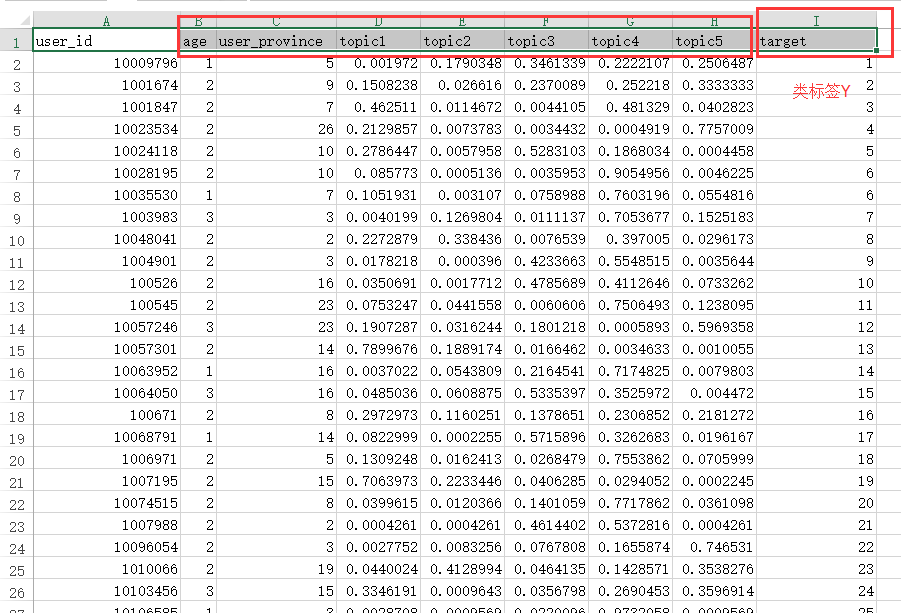
如图所示,为以上算法的数据格式,但是在运用是需要将数据的第一行删除,只保留数字。并将其转化为.txt文档,注意最好是utf-8的形式。以下代码中的,其中7表示age,user_province,topic1……..topic5七个变量
returnMat=zeros((numberOfLines,7)) #创建以零填充的numberOfLines*7以下代码是获得变量X的
##获取X
returnMat[index, : ]=listFromLine[1:8]'''从文件中读取数据,将文本记录转换为矩阵,提取其中特征和类标'''
def filematrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numberOfLines=len(arrayOLines) #得到文件行数
returnMat=zeros((numberOfLines,7)) #创建以零填充的numberOfLines*7的NumPy矩阵
classLabelVector=[]
index=0
for line in arrayOLines: #获取数据,获取特征矩阵
line=line.strip()
##文本分割
listFromLine=line.split('\t')
# print(listFromLine[1:8])
##获取X
returnMat[index, : ]=listFromLine[1:8]
##获取标签Y
classLabelVector.append(listFromLine[-1])
index+=1
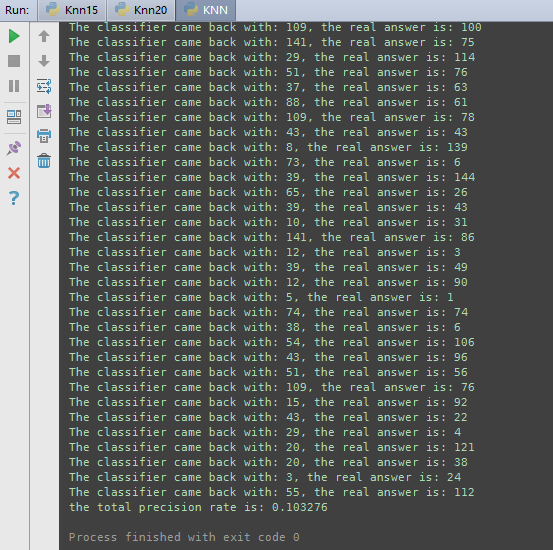
return returnMat,classLabelVector #返回特征矩阵和类标集合如下图所示,为KNN算法,针对我的数据跑出的精度,以及预测的标签,通过调节K值来调解预测的精度。















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









