







Baoguang Shi, Xiang Bai, Serge Belongie. Detecting Oriented Text in Natural Images by Linking Segments[J]. arXiv preprint arXiv:1703.06520v3, 2017
本文针对文字检测的特定环境改进SSD算法,提出Seglink多方向文本检测方法。核心是将文本检测转换成两个局部元素的检测:segment和link。segment 是一个有方向的box,覆盖文本内容的一部分,而link则连接了两个相邻的segments,表达了这两个segment是否属于同一个文本。本文算法通过在多尺度上进行segment和link的检测,最终按照links的表达将相关的segment合并成最终的bounding box。经实验证明,该算法提高了检测正确率及训练效率。
-网络结构
-Training过程
-Combine算法
-实验相关
-算法的局限性
1. 网络结构(cnn model)
本文算法以图片作为CNN模型的输入,模型输出为一组segments和links。具体的网络结构如下图所示:
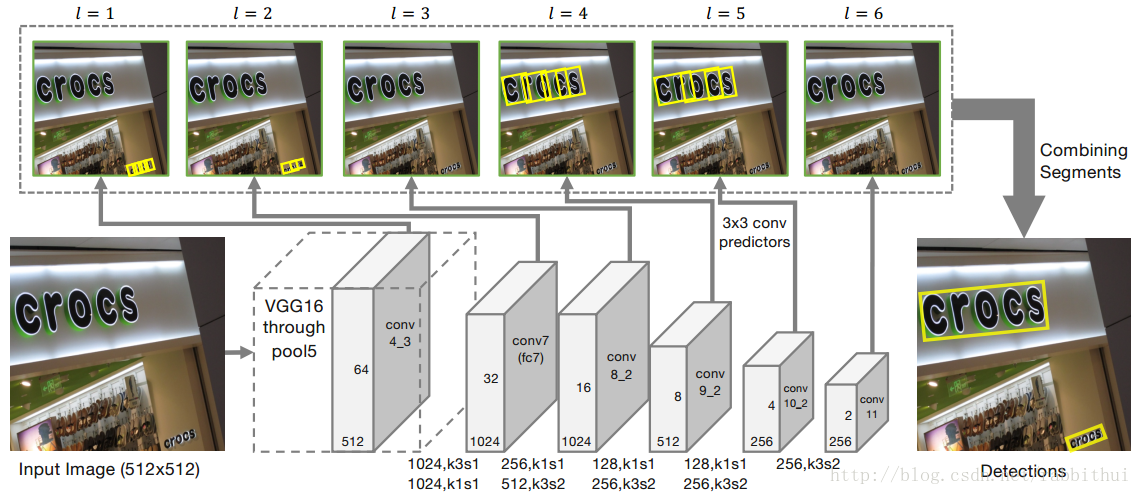
图中的网络由卷积feauture layers和predictors组成,在多个feature layer(文中为6个)上检测出segments和links,再合并成一个完整的检测结果。
网络结构与SSD相似,采用VGG16作为基础网络,其中全连接层(fc6,fc7)替换成卷积层(conv6,conv7),再接卷积层conv8_1到conv11。从其中的6个feature layer上检测segment和link,feature layer的索引设为 l=1.....6 。
1)Segment的预测
segment的预测部分,网络结构与SSD很相似,不同地方在于: a)每个feature map的每个位置上只用了一个default box;b)default box的scale不是人工设置,而是与感受野相关,aspect ratio=1,不是原来的1,2,3,1/2,1/3;c)输出为 s=(xs,ys,ws,hs,θs) ,比SSD网络多了一个角度参数。
对于第 l 个feature layer,default box的中心位置为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









