










HUE
Hue是cdh专门的一套web管理器,它包括3个部分hue ui,hue server,hue db。hue提供所有的cdh组件的shell界面的接口。你可以在hue编写mr,查看修改hdfs的文件,管理hive的元数据,运行Sqoop,编写Oozie工作流等大量工作。
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
支持基于Impala的应用进行交互式查询
支持Spark编辑器和仪表板(Dashboard)
支持Pig编辑器,并能够提交脚本任务
支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
支持Job设计器,能够创建MapReduce/Streaming/Java Job
支持Sqoop 2编辑器和仪表板(Dashboard)
支持ZooKeeper浏览器和编辑器
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
安装hue
这里我用的hue docker image. 就省去了安装,
环境:centos7 3台, 已经安装了ambari的hadoop集群
docker拉取hue
docker pull gethue/hue:latest检测下服务器没有被占用8888端口
netstat -anp | grep 8888运行hue
运行image
docker run -tid --name hue8888 --hostname cnode1.domain.org \
-p 8888:8888 -v /usr/hdp:/usr/hdp -v /etc/hadoop:/etc/hadoop \
-v /etc/hive:/etc/hive -v /etc/hbase:/etc/hbase \
-v /docker-config/pseudo-distributed.ini /hue/desktop/conf/pseudo-distributed.ini \
c-docker.domain.org:5000/hue:latest \
./build/env/bin/hue runserver_plus 0.0.0.0:8888解释下上面的命令,
-i 标志保证容器中STDIN是开启的
-t 表示告诉docker要为创建的容器分配一个伪tty终端
-d 会把容器放到后台运行
--name alias_name 可以为这个docker指定一个别名, 要放前面, e.g.:docker run -tid --name alias_name images:version /bin/bash
--hostname 指定hostname, 类似--ip
-p docker 容器的端口:外部主机的端口, 作端口映射, 来公开在dockerfile里面定义的expose的所有端口.
-v 挂在目录, 外部主机目录:容器内部目录, 这里我挂在了 ambari的 hadoop配置文件/etc/hadoop, hive配置路径/etc/hive, hbase配置路径/etc/hbase, 以及用了本地的hue配置文件去替代docker里面的hue配置文件.
最后是要启动容器后要运行的命令 ./build/env/bin/hue runserver_plus 0.0.0.0:8888
cnode1.domain.org 是我的一台服务器的域名. 拿来跑hue的
c-docker.domain.org 是我的私有docker仓库. 注意这里需要在docker daemon里面加上 --insecure-registry c-docker.domain.org:5000来允许不安全的授权拉取, centos7具体修改docker insecure-registry如下
vim /etc/systemd/system/docker.service
在[Service]下增加和修改如下内容
EnvironmentFile=-/etc/sysconfig/docker
ExecStart=/usr/bin/docker daemon -H fd:// $OPTIONS
vim /etc/sysconfig/docker
添加
OPTIONS="-D --selinux-enabled --insecure-registry c-docker.domain.org:5000"
重启docker和daemon
systemctl restart docker
systemctl daemon-reload配置hue
hue-docker的相关配置文件在/hue/desktop/conf/pseudo-distributed.ini
修改相关参数, scp传出来后修改如下参数,保存到主机cnode1上/docker-config/pseudo-distributed.ini
http_port=8888
fs_defaultfs=hdfs://cnode1.domain.org:8020
logical_name=cnode1
webhdfs_url=http://cnode1.domain.org:50070/webhdfs/v1
hadoop_conf_dir=/etc/hadoop/conf
hive_server_host=cnode1.domain.org
hive_server_port=10000
hive_conf_dir=/etc/hive
hbase_clusters=(cluster1|cnode2.domain.org:9090)
hbase_conf_dir=/etc/hbase注意上面的地址 hbase_clusters 的cluster1只是hue里面显示的, 可以随便命名, cnode2.domain.org:9090 是hbase thrift 1的地址, 在ambari的主机里面用如下命令启动起来
/usr/hdp/2.4.0.0-169/hbase/bin/hbase-daemon.sh start thrift使用
第一次进入需要配置账户和密码
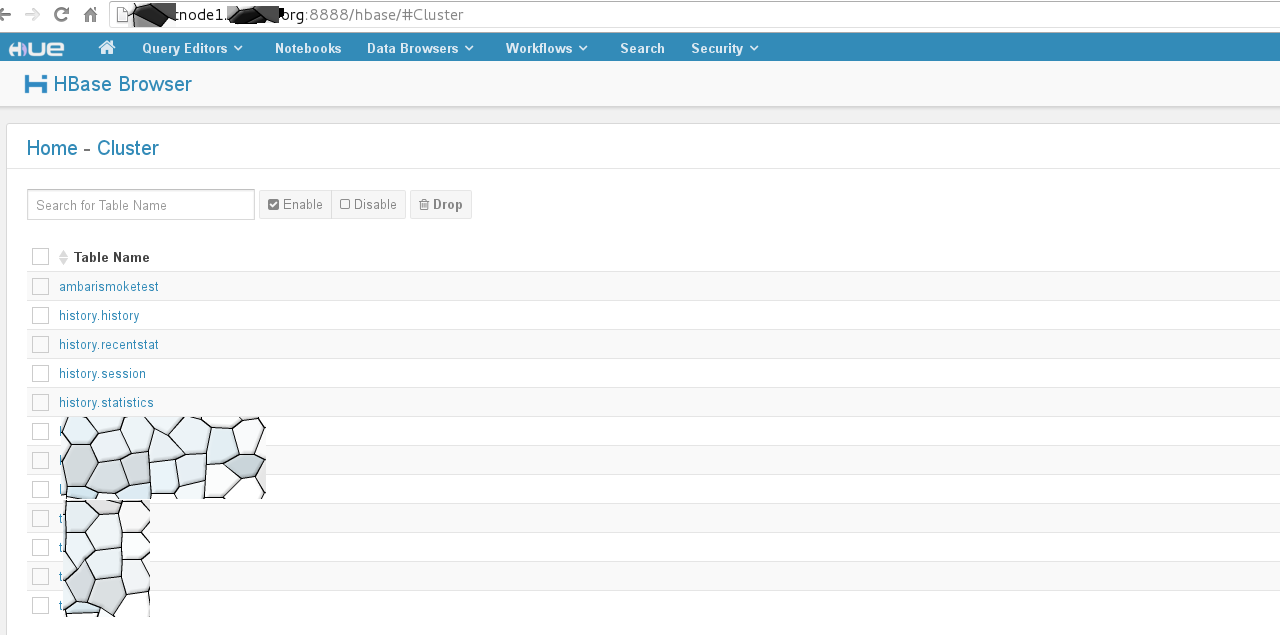
使用hue来连接mysql
同样是编辑pseudo-distributed.ini,
找到[librdbms]这段后, 按照自己需要修改如下的内容, 注意要取消[[[mysql]]]的注释
[[[mysql]]]
nice_name="Hyve-ENG UAT MySQL"
name=dbname_test
# Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
engine=mysql
host=192.168.85.100
# Port the database server is listening to. Defaults are:
# 1. MySQL: 3306
# 2. PostgreSQL: 5432
# 3. Oracle Express Edition: 1521
port=3306
# Username to authenticate with when connecting to the database.
user=tom
# Password matching the username to authenticate with when
# connecting to the database.
password=db12@34#56%78保存后, 重启docker container
docker restart hue8888接下来就可以在http://cnode1.domain.org:8888/rdbms/ 来进行对应的mysql查询.
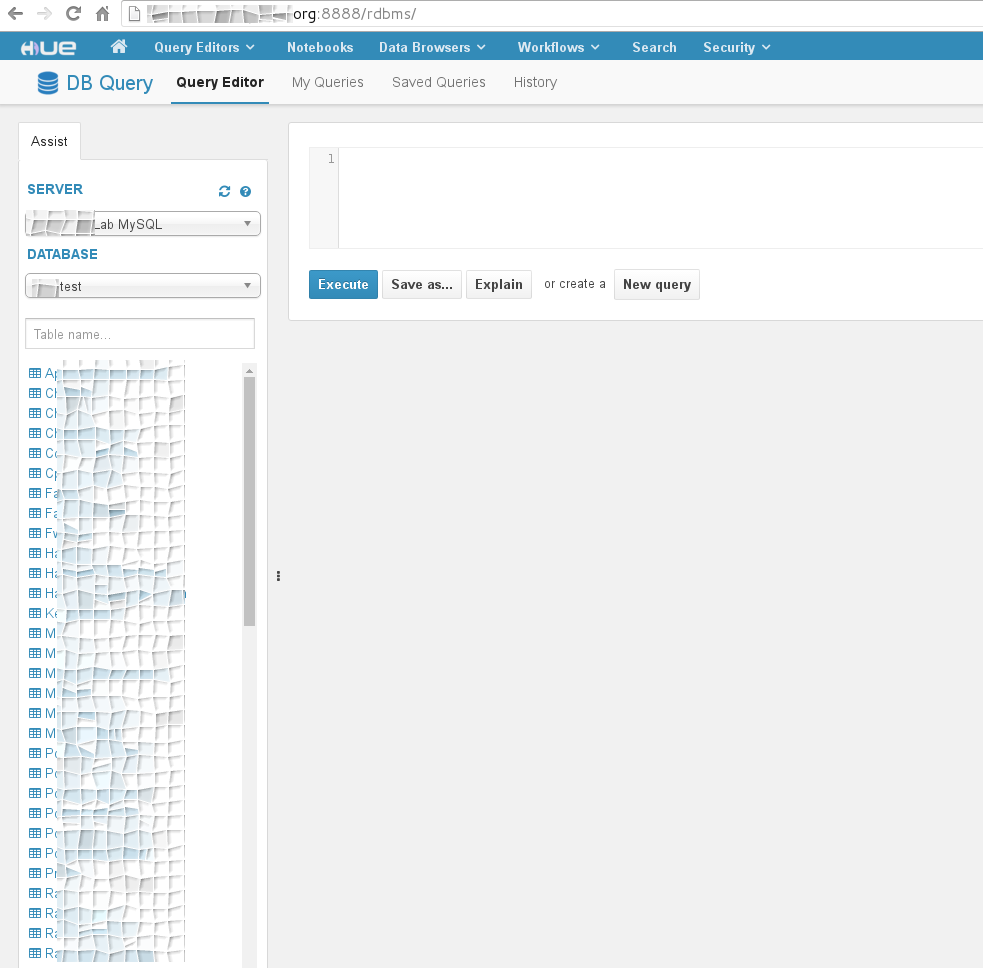
多个db支持, 需要复制完整的 对应的db段, 比如要支持postsql, 或者新的mysql db库, 需要复制
如下, 在options里面可以定制相关编码等:
[[[mysql3]]]
nice_name="UAT MySQL"
name=mysqldbname
engine=mysql
host=192.168.80.116
port=3306
user=tommy
password=p12391kf1#jkew
[[[mysql2]]]
nice_name="UAT MySQL"
name=mysqldbname2
engine=mysql
host=192.168.80.116
port=3306
user=tommy
password=p12391kf1#jkew
options={ "init_command":"SET NAMES 'utf8'"}options里面init_command支持一些初始化链接行为, 比如设置编码, 设置连接超时, 设置select的limit数量,
具体可以参考http://dev.mysql.com/doc/refman/5.6/en/mysql-tips.html#safe-updates 和django的database部分, 比如下面
"init_command": 'set storage_engine=INNODB; \
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED', }设置默认查询数量,
options={"init_command": "SET sql_select_limit=100"}多组init_command:
options={"init_command": "SET sql_select_limit=100; SET names 'utf8'; SET sql_safe_updates=1"}













 5160
5160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









