






本文来自Weaveworks的工程师Anita Burhrle在Rancher Labs与Weaveworks联合举办的Online Meetup上的技术分享。在此次分享中,嘉宾们讨论了如何使用Rancher、Weave Cloud和Prometheus来轻松部署、管理与监控Kubernetes。本文将分享Weave是为何以及如何开发出RED最佳实践方法来使用Prometheus在Kubernetes中监控应用程序的。
什么是Prometheus监控?
最近有很多关于Prometheus的消息,尤其是在Kubernetes中监控应用程序这方面。深入RED方法之前,我们先了解一些背景内容。应用程序运行在容器上并由Kubernetes负责调度,在此环境中它们是高度自动化并且动态的。传统的监控工具一般是基于服务器,只监控静态的服务,所以当要在这种动态环境监控应用程序时,传统的监控工具往往很难满足这一需求。
这时就需要Prometheus出马了。
Prometheus是一个开源项目,最初由SoundCloud的工程师开发。它专门用于监控那些运行在容器中的微服务。每经过一个时间间隔,数据都会从运行的服务中流出,存储到一个时间序列数据库中,这个数据库之后可以通过PromQL语言查询。另外,因为数据是以时间序列存储的,当出现问题时,可以根据这些时间间隔进行诊断,另外还可以预测基础设施的长期监控趋势—-这是Prometheus的两大功能。
在Weaveworks,我们把服务搭建在Prometheus的开源分布上,并且创建了一个可扩展、多租户的版本,这是我们软件即服务概念的一部分,称为Weave Cloud。
现在,该服务已经运行了几个月,同时也使用Weave Cloud监控自己本身,在这个过程中我们积累到了一些有关监控云本机应用程序的经验,并根据这些经验设计了一个系统来确定在检测代码前需要测量什么。
该检测什么?
在搭建Prometheus监控时,确定需要收集的指标类型十分重要,这些指标和应用程序相关。选择的指标可以简化故障发生时排除故障的流程,并且还可以在服务和基础设施上保持很高的稳定性。为帮助理解instrument的重要性,我们定义了一个称之为RED方法的系统。
RED方法遵循Four Golden Signals中提及的原则,聚焦于检测最终用户在使用web服务时关心的东西。
在RED方法中,我们通过监控三项关键指标来管理架构中的每个微服务:
- (Request)Rate – 你的服务所服务的每秒的请求数
- (Request)Errors – 每秒失败的请求数
- (Request)Duration – 每个请求所花费的时间,用时间间隔表示
RED方法希望由Rate、Errors、Duration三项指标涵盖最典型的Web服务问题。同时这些指标还能够反映出请求的错误率。通过这三项指标,我们就能监测到通常情况下会影响客户体验的问题。
如果想要获得更细节的信息,还需要用到Saturation指标。Saturation指标用在USE(Utilization Saturation and Errors)方法中,它指的是一种带有额外作业的资源,而该资源不能够提供服务,因此必须添加到队列中以备后续处理。
USE vs. RED方法
对比两种方法,USE方法更侧重于监控的性能,并以此为出发点寻找影响性能问题的根本原因以及其他系统的瓶颈。
在理想状态下,我们可以在监控应用程序时同时使用USE和RED方法。
为什么要对每个服务衡量相同的指标
从监控的角度来看,如果能处理好每项服务,你的运营团队就可以在此基础上继续扩展服务。
扩展性对运营团队意味着什么?
我们从这个角度看待问题,一个团队可以支持多少个服务。在理想状态下,一个团队可以支持的服务数量和团队规模无关,而取决于其他因素,比如SLA协议的响应类型以及是否需要全天候覆盖等等。
如何将可支持的服务数量与团队规模去藕化?
办法是让每一个服务都变得一样。这既减少了团队针对特定的服务进行培训的数量,还减少了在高压事件响应场景或者所谓“认知负载”这些针对特定服务的特殊情况发生时,呼叫者需要记录的内容。
容量规划:
考虑QPS(每秒查询次数)和延迟
自动化任务以及发出警报:
RED方法的优点在于它可以帮助你考虑如何在仪表板中显示信息。通过这三个指标,你可以对仪表板的布局进行调整,让它更易于阅读,并在问题发生时发出警报。例如,一个布局可能意味着 — 每个服务都有一个不同的Weave Cloud记事本,包含了PromQL查询的请求&错误,以及每个服务的延迟。
毫无疑问,如果把所有的服务都视为一样的,那么将会更加易于自动化执行重复任务。
PromQL查询
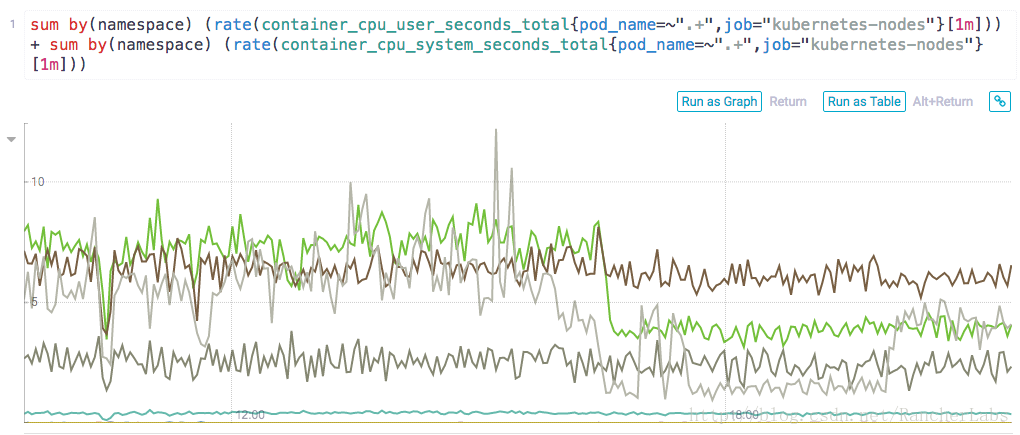
在Weave Cloud上监控RED方法中的指标
局限性
事实上,这种方法(RED)仅适用于请求驱动的服务——比如,它在处理面向批处理的服务或者流服务时会发生错误。对于请求驱动它也不是完全适用,当需要监控其他东西——比如主机CPU&内存或者缓存资源时,USE方法表现的更好。
原文来源:Rancher Labs















 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









