







代码地址:https://code.csdn.net/ranky2009/pythonsmallproject
编码中遇到的问题Note:
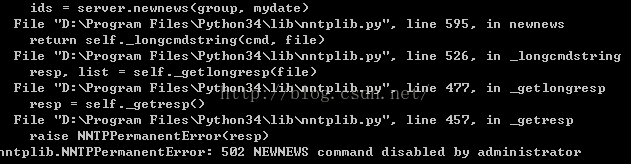
1.在编写中发现使用newnews时出现如下错误:
502 NEWNEWS command disabled by administrator
由于使用newnews命令出现问题,所以改为使用其他的命令替代。用group 和article命令,见项目代码。
2.使用如下code打印中文会报错误
代码url_test.py:
from urllib.request import urlopen
with urlopen('http://www.baidu.com') as f:
print(f.read().decode('utf-8'))
错误:
UnicodeEncodeError: 'gbk' codec can't encode character '\ufeff' in position 0: i
llegal multibyte sequence

错误环境是OS:WIN7, version of python:3.4.3,窗口:控制台cmd
后来发现,这个错误是由于在控制台中运行(python url_test.py)代码。
解决方法:
开始->所有程序->启动IDLE (Python 3.4 GUI
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









