







在探索者界面详解的系列中我们提到,探索者界面简单易用但有一个缺点:它将样本数据全部加载到内存中,所以样本的大小受限于内存的大小。而本篇介绍的知识流界面正好弥补了这一缺陷。
知识流界面的主体是一个设计画布。用户从工具条中选择 Weka 组件,并将其置于设计画布上,连接成一个处理和分析数据的具有方向性的流程图。比如用户可以先使用 属性选择 组件找出样本中重要的属性,然后再使用分类器,基于重要的属性进行挖掘。
知识流界面共有标签8个:
DataSources:选择数据源
DataSinks:保存结果,注意在linux下一定要保存在当前用户有权写的目录中
Filters:过滤器选择
Classifiers:分类器选择
Clusterers:聚类器选择
Associations:关联规则算法选择
Evaluation:评估器
Visualization:用于将结果可视化的组件选择
一般操作知识流界面的顺序是:
选择一个数据源组件,置于画板上。
再到评估器标签中找到 ClassAssigner ,这个评估器用于指明样本中决定分类的属性,将其置于画板上。
然后右键数据源组件来连接数据源组件和ClassAssigner组件,连接方式有两种:dataset 和 instance(只能选一种)。dataset指批量传递数据,而 instance 一个一个地传递实例,用于像贝叶斯网络这样增量更新的分类器。
然后继续在评估器标签中找到 训练集和测试集的分配方案 ,比如 CrossValidationFoldMaker组件(交叉验证)。
接着就可以到分类器选择标签中找相应算法的分类器组件。
最后在可视化标签中找到 可以显示结果的组件(有文本式的,树状的,显示ROC曲线的,矩阵式的)
确保连接好所有的组件,最后右键数据源组件,选择 Start Loading,开始挖掘。
所有的组件都可以通过右键选择 Configure 来配置参数。
最后上两张截图:
这是一个对样本属性进行离散化过滤后再分类的方案:
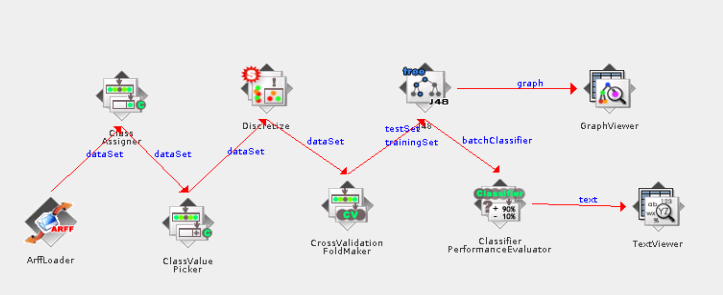
这是部分组件的说明:
















 1853
1853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











