




 本文详细介绍了SAX解析XML的工作原理及其优势与局限性。通过实际案例演示了如何使用SAX解析器处理XML文档,包括解析过程中的事件处理机制。
本文详细介绍了SAX解析XML的工作原理及其优势与局限性。通过实际案例演示了如何使用SAX解析器处理XML文档,包括解析过程中的事件处理机制。
SAX解析XML文件采用事件驱动的方式进行,也就是说,SAX是逐行扫描文件,遇到符合条件的设定条件后就会触发特定的事件,回调你写好的事件处理程序。使用SAX的优势在于其解析速度较快,相对于DOM而言占用内存较少。而且SAX在解析文件的过程中得到自己需要的信息后可以随时终止解析,并不一定要等文件全部解析完毕。凡事有利必有弊,其劣势在于SAX采用的是流式处理方式,当遇到某个标签的时候,它并不会记录下以前所遇到的标签,也就是说,在处理某个标签的时候,比如在startElement方法中,所能够得到的信息就是标签的名字和属性,至于标签内部的嵌套结构,上层标签、下层标签以及其兄弟节点的名称等等与其结构相关的信息都是不得而知的。实际上就是把XML文件的结构信息丢掉了,如果需要得到这些信息的话,只能你自己在程序里进行处理了。所以相对DOM而言,SAX处理XML文档没有DOM方便,SAX处理的过程相对DOM而言也比较复杂。
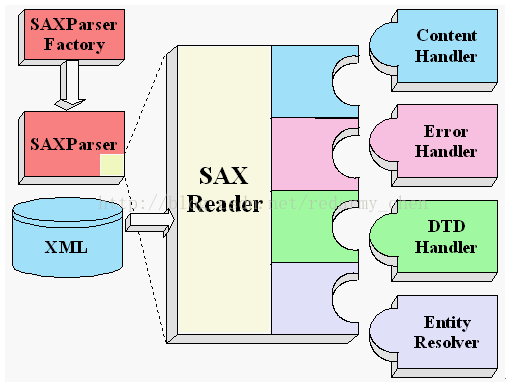
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
备注说明:SAX API中主要有四种处理事件的接口,它们分别是ContentHandler,DTDHandler, EntityResolver 和 ErrorHandler
这里使用最多的就是ContentHandler,仔细阅读 API文档,了解常用方法:startElement、endElement、characters等
1.startElement方法说明
void startElement(String uri,
String localName,
String qName,
Attributes atts)
throws SAXException
方法说明:
解析器在 XML 文档中的每个元素的开始调用此方法;对于每个 startElement 事件都将有相应的 endElement 事件(即使该元素为空时)。所有元素的内容都将在相应的 endElement 事件之前顺序地报告。
参数说明:
uri - 名称空间 URI,如果元素没有名称空间 URI,或者未执行名称空间处理,则为空字符串
localName - 本地名称(不带前缀),如果未执行名称空间处理,则为空字符串
qName - 限定名(带有前缀),如果限定名不可用,则为空字符串
atts - 连接到元素上的属性。如果没有属性,则它将是空 Attributes 对象。在 startElement 返回后,此对象的值是未定义的
void endElement(String uri,
String localName,
String qName)
throws SAXException接收元素结束的通知。
SAX 解析器会在 XML 文档中每个元素的末尾调用此方法;对于每个 endElement 事件都将有相应的 startElement 事件(即使该元素为空时)。
参数:
uri - 名称空间 URI,如果元素没有名称空间 URI,或者未执行名称空间处理,则为空字符串
localName - 本地名称(不带前缀),如果未执行名称空间处理,则为空字符串
qName - 限定的 XML 名称(带前缀),如果限定名不可用,则为空字符串3.characters方法
void characters(char[] ch,
int start,
int length)
throws SAXException
接收字符数据的通知,可以通过new String(ch,start,length)构造器,创建解析出来的字符串文本.
参数:
ch - 来自 XML 文档的字符
start - 数组中的开始位置
length - 从数组中读取的字符的个数 其它方法请参考api数据
下面我们就具体讲解sax解析的操作.
一.我们通过XMLReaderFactory、XMLReader完成,步骤如下
1.通过XMLReaderFactory创建XMLReader对象
XMLReader reader = XMLReaderFactory.createXMLReader();
2. 设置事件处理器对象
reader.setContentHandler(new MyDefaultHandler());
3.读取要解析的xml文件
FileReader fileReader =new FileReader(new File("src\\sax\\startelement\\web.xml"));
4.指定解析的xml文件
reader.parse(new InputSource(fileReader));案例:通过案例对uri、localName、qName和attribute参数有更加深入的了解
1.首先创建要解析的web.xml文件,内容如下
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns:csdn="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<csdn:display-name></csdn:display-name>
</web-app>
<!--
uri - 名称空间 URI,如果元素没有任何名称空间 URI,或者没有正在执行名称空间处理,则为空字符串。
xml namespace-xmlns
localName - 本地名称(不带前缀),如果没有正在执行名称空间处理,则为空字符串。
qName - 限定的名称(带有前缀),如果限定的名称不可用,则为空字符串。
attributes - 附加到元素的属性。如果没有属性,则它将是空的 Attributes 对象。
-->2.创建解析测试类及事件处理的内部类代码如下
package sax.startelement;
import java.io.File;
import java.io.FileReader;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
public class Demo3 {
@Test
public void test() throws Exception {
// 通过XMLReaderFactory创建XMLReader对象
XMLReader reader = XMLReaderFactory.createXMLReader();
// 设置事件处理器对象
reader.setContentHandler(new MyDefaultHandler());
// 读取要解析的xml文件
FileReader fileReader = new FileReader(new File(
"src\\sax\\startelement\\web.xml"));
// 指定解析的xml文件
reader.parse(new InputSource(fileReader));
}
// 自定义的解析类,通过此类中的startElement了解uri,localName,qName,Attributes的含义
class MyDefaultHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
System.out
.println("--------------startElement开始执行--------------------------");
System.out.println("uri:::" + uri);
System.out.println("localName:::" + localName);
System.out.println("qName:::" + qName);
for (int i = 0; i < attributes.getLength(); i++) {
String value = attributes.getValue(i);// 获取属性的value值
System.out.println(attributes.getQName(i) + "-----" + value);
}
System.out
.println("------------------startElement执行完毕---------------------------");
}
}
}
3.程序运行的结果如下:
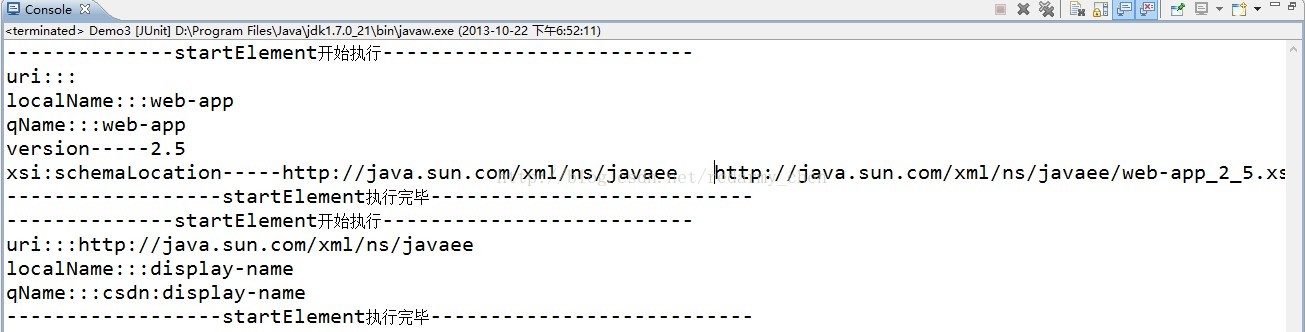
通过运行结果,希望你对uri,localName,qName有更加深入的了解.
二.我们通过SAXParserFactory、SAXParser、XMLReader完成,步骤如下
1.使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
2.通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
3.通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader();
4.设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler());
5.解析xml文件
xmlReader.parse("book.xml");
说明:如果只是使用SAXParserFactory、SAXParser他们完成只需要如下3步骤
1.获取sax解析器的工厂对象
SAXParserFactory factory = SAXParserFactory.newInstance();
2.通过工厂对象 SAXParser创建解析器对象
SAXParser saxParser = factory.newSAXParser();
3.通过解析saxParser的parse()方法设定解析的文件和自己定义的事件处理器对象
saxParser.parse(new File("src//sax//sida.xml"), new MyDefaultHandler());
案例:解析出"作者"元素标签中的文本内容
1.需要解析的sida.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 四大名著[
<!ELEMENT 四大名著 (西游记,红楼梦)>
<!ATTLIST 西游记 id ID #IMPLIED>
]>
<四大名著>
<西游记 id="x001">
<作者>吴承恩</作者>
</西游记>
<红楼梦 id="x002">
<作者>曹雪芹</作者>
</红楼梦>
</四大名著>2.解析测试类和事件处理器类的实现代码
package sax;
import java.io.File;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxTest {
@Test
public void test() throws Exception {
// 1.获取sax解析器的工厂对象
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.通过工厂对象 SAXParser创建解析器对象
SAXParser saxParser = factory.newSAXParser();
// 3.通过解析saxParser的parse()方法设定解析的文件和自己定义的事件处理器对象
saxParser.parse(new File("src//sax//sida.xml"), new MyDefaultHandler());
}
// 自己定义的事件处理器
class MyDefaultHandler extends DefaultHandler {
// 解析标签开始及结束的的标识符
boolean isOk = false;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
// 当解析作者元素开始的时候,设置isOK为true
if ("作者".equals(qName)) {
isOk = true;
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
// 当解析的标识符为true时,打印元素的内容
if (isOk) {
System.out.println(new String(ch, start, length));
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
super.endElement(uri, localName, qName);
// 当解析作者元素的结束的时候,设置isOK为false
if ("作者".equals(qName)) {
isOk = false;
}
}
}
}
3.程序运行结果如下:

通过以上解析希望你对sax解析有初步的认知.
下面我们也给大家留两个思考题,希望有兴趣的同学可以做一做?
1.sax与Dom解析的区别
2.如果用(二的解析方式解析web.xml)会有什么样的输出结果?怎么解释尼?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









