






下面两个函数,要完成的功能都是一样的,当都在gcc的-O3条件下编译,如果要选出目标代码效率更高的一个,你会选择哪个?
作为提示,先回顾一下memory hierarchy的概念.

上图说明,同样一条指令,如果从寄存器取操作数需要一个cycle的话,那么从主内存取操作数的时间就需要40~100 cycles.效率相差最大可以到100倍.即使从L1 cache取操作数也最大会有5倍的差距.
c语言里就有一个关键字"register",被register修饰的变量相当于请求编译器希望能把它'分配'到一个通用寄存器中,由memory hierarchy的道理可知这样能比把它放到内存获得更高的运行时效率.往往在O3的高优化编译条件下,哪怕没有用'register'修饰的变量往往也会被编译器聪明地放到寄存器中,比如下面这样的代码:
如果不带O3编译的话,大概会生成这样的目标码(x86):
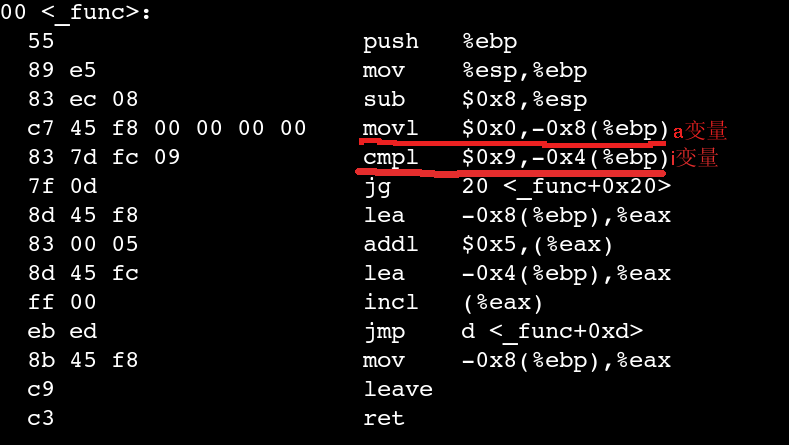
很显然,其中的i和a变量都被分配到了栈(内存)中,分别在-4(%ebp)和-8(%ebp)里--ebp是什么以及indirect寻址就不用我解释了吧.
如果带上O3编译的话,目标代码就是这个样子:
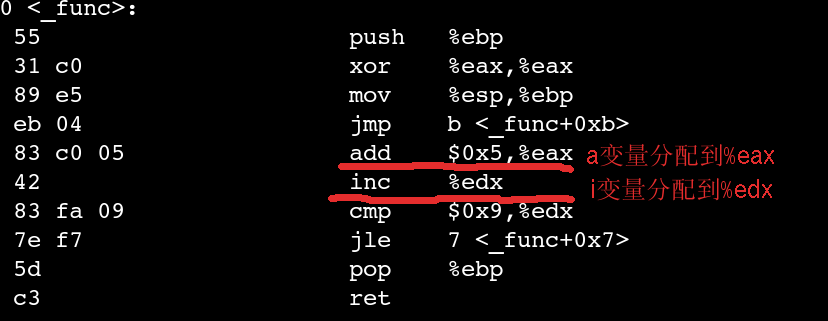
里面甚至连分配栈空间的代码都没有.i被放到%edx中,a被放到%eax中.
所以,在编译优化的技术中就专门有一步叫'寄存器分配',好的编译器能将更多的变量保存在寄存器中以及使其保存时间更持久(近量少的寄存器溢出)。
回头看文章最开始的那个函数,我们发现(*a)在代码中只是被读,重来没有被回写过;所以,在O3的优化下,我们揣测一下,gcc是不是可以对*a只求值一次,然后将其求值结果保存到一个寄存器中;在循环中,cpu就可以总是从寄存器中取值到b[i],而不用每次都从a所代表的内存地址中去读memory.
但结果是遗憾的,哪怕在O3编译条件下,仍然会生成这样的代码:
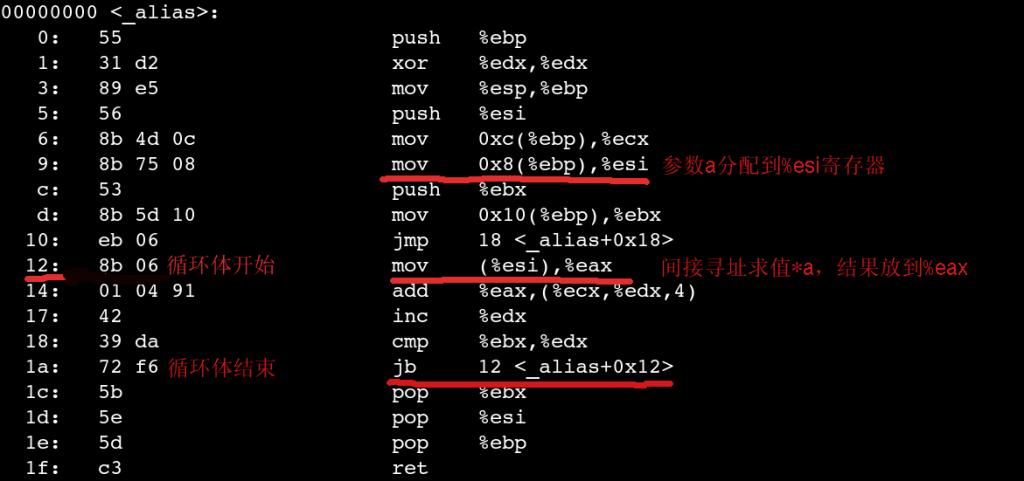
即a自身的值被保存到%esi中,每次循环中都由mov (%esi), %eax来取*a的结果(--这里的mov指令对%esi也是indirect寻址).也就是说每次对*a的引用仍然会引发cpu到内存中去取值.
也许你会说,这不是还有cache么,a本身又不会变,所以 cpu第一次取*a的值时多半已经将其放到对应地址(a)所映射的cache line了,那么接下来循环的引用都是从cache取值了,也不会跑到内存中去.对,你说得没错,但是,这段代码对cache其实也不是那么'友好'的,注意在对*a求值后接下来的一条指令就是对b[i]写操作数的指令--add %eax, (%ecx, %edx, 4):这也是一条会访问内存的指令(%ecx是b[0]的地址,%edx是i,也是indirect寻址).a和&b[i]如果碰巧在数值上有一定的关系,即正好都映射到一条cache line,那么最坏的情况就是每次循环会发生两次cache miss,即两次读写操作都导致cpu到内存中去取值,这种'最坏的情况'一旦发生,在后期解决性能瓶颈的调优过程中将是很难被发现的.
那么,为什么gcc不把*a求值结果放到寄存器中呢,这不是在O3吗?编译器为啥不给力?
我们仔细看看这个函数,可以肯定,如果该函数出现在任何现实项目中,它的目的只有一个,那就是将参数一(一个集合)中的每个数都加上参数二(一个数的地址)储存的值.注意到扮演加数的参数二的类型是int *而非int.问题就在这里!仔细想想,假如当调用这个函数时,我们传递这样的参数:
函数运行完后,应该出现的结果是:array变成
4,5,6,10,11,12
但假如函数按我们认为应该做的优化的方式来编译,则结果是:array变成
4,5,6,7,8,9
所以,编译器还能做优化么?要知道,编译器除了负责产生高效的代码以外,它首要要保证的是,无论任何情况下,程序的执行结果得是正确的.也就是说,编译器,必定是保守的,哪怕它顾虑的情况永远也不会出现.
类似这种情况的还有更直观的例子,如下程序:
编译器可不能把最后一句'return *a'优化成"return 1",因为,运行时有a==b这种情况出现的可能,所以编译器怎么能在编译期知道到底该优化成"return 1"还是"return 2"呢.
这种阻止编译器产生更优代码的原因有个较专业的名字----"aliasing",即潜在地对同一个存储空间产生多次引用.由上面两个例子可知,指针往往是aliasing现象的罪魁祸首,比如第一个例子中的参数a,就是一个作为pass by-reference的指针参数,试想如果将第一个例子的函数原型换成pass by-value的话,因为by-value的参数是分配在栈上的一个副本,它永远不可能同另一个参数b同名.编译器也能工作得更开心.同样,如果把第二个例子改为:
你用任何编译器编译它都会发现最后的'return a'被优化成了'return 1'.
但假如某个函数只能用pass by-reference的方式来传参数时怎么办?这里举了一个运用局部变量来解决问题的方式,再回到开始那个问题中的第二个函数,因为我们当然是知道a和b永远也不可能指向相同存储空间的(我们是知道该函数调用的语义的),那么可以把一会儿要频繁读取的*a拷贝到局部变量tmp中,以后所有对*a的只读引用都显示地改为对tmp的引用,而编译器自然是能把局部变量tmp分配到寄存器中的(同pass by-value的原理一样,tmp也是分配在栈上,它同另一个参数b也不可能同名)。
不过这种方法相当于降低了我们所看待的语言的表达能力(明明做的是同样的事情,却要多一个局部变量的拷贝赋值);或者说降低了语言的抽象力,看看那句int tmp = *a的表达式,好比我们自己(程序员)在将*a分配一个寄存器中一样,而这事应该由编译器来做的。
试想这个问题的根本原因是编译器不知道函数调用的语义,它‘合理地怀疑’两个指针可能指向同样的内容这么一个其实我们程序员知道在假设的应用场合中不可能发生的情况(如果发生了,那是bug)。所以,如果我们能将我们知道的情况告诉编译器呢?
c99定义了一个qualifier关键字'restrict',用restrict关键字修饰的指针,其所指向的对象只能通过这个指针所访问到。换句话说,找不到第二个指针可能和该指针指向同样的内容。
比如还是那个无聊的赋值例子,如果在a和b的声明前加上restrict关键字:
因为是c99标准,用gcc编译时最好加上-std=c99选项,gcc编译后就可以发现return *a被优化为return 1了。
不过很遗憾,用本文开头的那个例子来做测试,发现即使在a和b前面都加上restrict修饰,仍然不会生成最优代码。难道这里面还有什么陷阱么?














 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









